3 Looking at Images
3.1 Introduction
Vision is about solving an amazing problem: Can we build a system capable of perceiving its surrounding world using only the information available in the small number of electromagnetic waves that fall into the observer’s sensor (eye or camera), after accidentally bouncing off the objects surrounding the observer? How is it possible to sense the world and its three-dimensional (3D) structure without touching it? It seems quite likely that if humans did not have the sense of vision, we would think that solving this problem is impossible.
The goal of this chapter is to present vision not as an engineering problem that we want to solve, but as a set of scientific questions that we want to answer. We want to understand how it is that our visual system can interpret the world the way it does. We want to explain what components of an image can be used to infer certain properties of the world. We want to know what questions about the world can be answered by just looking at an object with the light that reaches our eyes.
In this chapter we will not answer any of those questions, instead, we will use images to motivate a set of questions that vision scientists and computer vision engineers have been studying for many years. The goal of this chapter is to help you ask questions about how do you perceive the world around you.
3.2 Looking at Individual Pixels
Before we build systems that can see, it is good to learn to look at images and to pay attention to individual pixels. The image in Figure 3.1 is a tiny image with just \(32 \times 32\) pixels.
What is the minimum number of pixels needed to form a recognizable image? The answer depends on the image. It is possible to create visually recognizable images with very few pixels [1]
It is so small that we can actually look at each single pixel and think about how it is that we can make sense of it. For instance, let’s look at the pixel in row 13 counting from the bottom, and column 12 counting from the left. That pixel corresponds to a dark gray pixel, which is near a couple of other pixels with similar intensity, surrounded by a set of white pixels. That pixel seems to be a pen, but how do we know what it is? The pen is barely three pixels long and one pixel wide. How can that provide enough information?

Same image as in Figure 3.1 but shown small and blurred to remove the artifacts due to the square pixels.

Reducing the size and blurring helps better recognizing the objects despite containing the same visual information.
Recognition of the meaning of that pixel can not come just from the intensity of that pixel or the few pixels nearby. There are way too many possible situations in which different objects in the world could map to a similar set of pixel intensities. Instead, is the whole image and the context of the pen that provides the necessary information to recognize the pen. Taken in isolation, those pixels are impossible to recognize. Here we show, from left to right, the hand, the blue mug, and the pen.
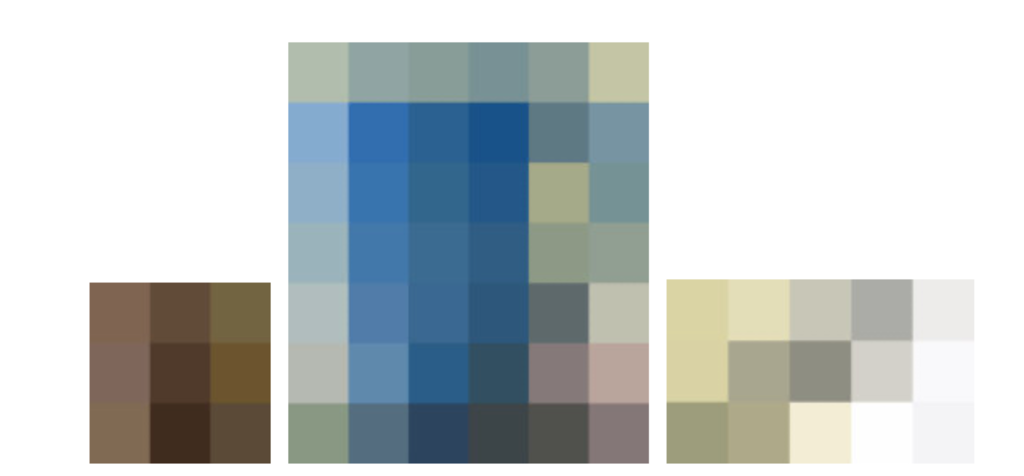
3.3 The More You Look, the More You See
Visual perception cannot be formulated as a simple input-output function over predefined domains. Vision is a dynamical system, even when looking at a static image. The longer you look at an image, the more details you see and the better you understand the scene. Just look at the image shown in Figure 3.3 and try to write down everything you see down to the smallest detail.

But this feeling of unlimited and effortless understanding of a picture is also an illusion. Do you truly understand everything you see? For instance, are you sure you can make sense of all the chair legs in Figure 3.3? In fact, this image has been manipulated so that some of legs do not correspond to any chair.
When solving a task, as the visual cognitive load increases we are more likely to make judgment mistakes.
As you look around the image, notice that each patch you look at is actually a small photo in its own right. In fact, a big image like this contains thousands of tiny images within it (Figure 3.4). A single photo can be big data; if you chop up this photo you get a big dataset of tiny images. A common trick in computer vision is to take a method that was developed for processing a dataset and instead apply it to the set of patches in an image, or vice versa.

3.4 The Eye of the Artist
Learning to paint is a great way of learning to see. You start from a white piece of canvas and a finite set of acrylic paints, and your goal is to paint an object that should look real, with shadows, 3D shape, and reflections. What mixtures of paint and what strokes can accomplish that? Artists learn to see the world not by what it represents, but as why it looks the way it does.
The following sequence Figure 3.5 painted by Agata Lapedriza, shows different steps in the painting process of a strawberry. Layer after layer, the artist replicates the light that will fool your eye into seeing a strawberry instead of acrylic paint. It is interesting to see that the realism does not increase monotonically as the painting progresses. For instance, from step 3 to 4, the right side of the strawberry has lost realism. However, those new strokes will become the shading that will make the strawberry pop out from the canvas.

3.5 Tree Shadows and Image Formation
When walking under the shadow of a tree on a bright sunny day when the sun is right above us (Figure 3.6[left]), we can see how some light rays get through the holes left between leaves, creating spots on the floor (Figure 3.6[right]).

But something is a bit odd about the shape of the bright spots projected on the floor. We would expect that the spots of light would have irregular shapes as the openings between leaves will have all kinds of irregular profiles (Figure 3.6[left]). Instead, as shown in Figure 3.6(right), the spots appear to be circular and of similar size. This observation already puzzled Aristotle. What could be happening? As a hint, Figure 3.7 shows the shadow of leaves during a solar eclipse.

One of the most common situations that we often encounter is the pinhole cameras formed by the spacing between the leaves of a tree. The tiny holes between the leaves of a tree create a multitude of pinholes. The pinholes created by the leaves project different copies of the sun on the floor. When the openings between leaves are small enough, the shape of the projected spot light is dominated by the shape of the sun. This is something we see often but rarely think about the origin of the spotlights that we see on the floor.
In fact, the leaves of a tree create pinholes that produce images in many other situations. We will talk about pinhole cameras in .
3.6 Horizontal or Vertical
Looking at the previous picture of the shadow of the tree, another interesting question comes to mind: How do you know you are looking at a picture of the ground? How do you know the orientation of the camera?
Look at the two drawings in Figure 3.8. The lines in the drawing on the left correspond to tiles in a floor, the line drawing on the right is the same drawing rotated 90 degrees. Which one seems to be an horizontal surface and which one seems vertical? Why? The differences in the line orientations are subtle and yet it produces a very different perception.
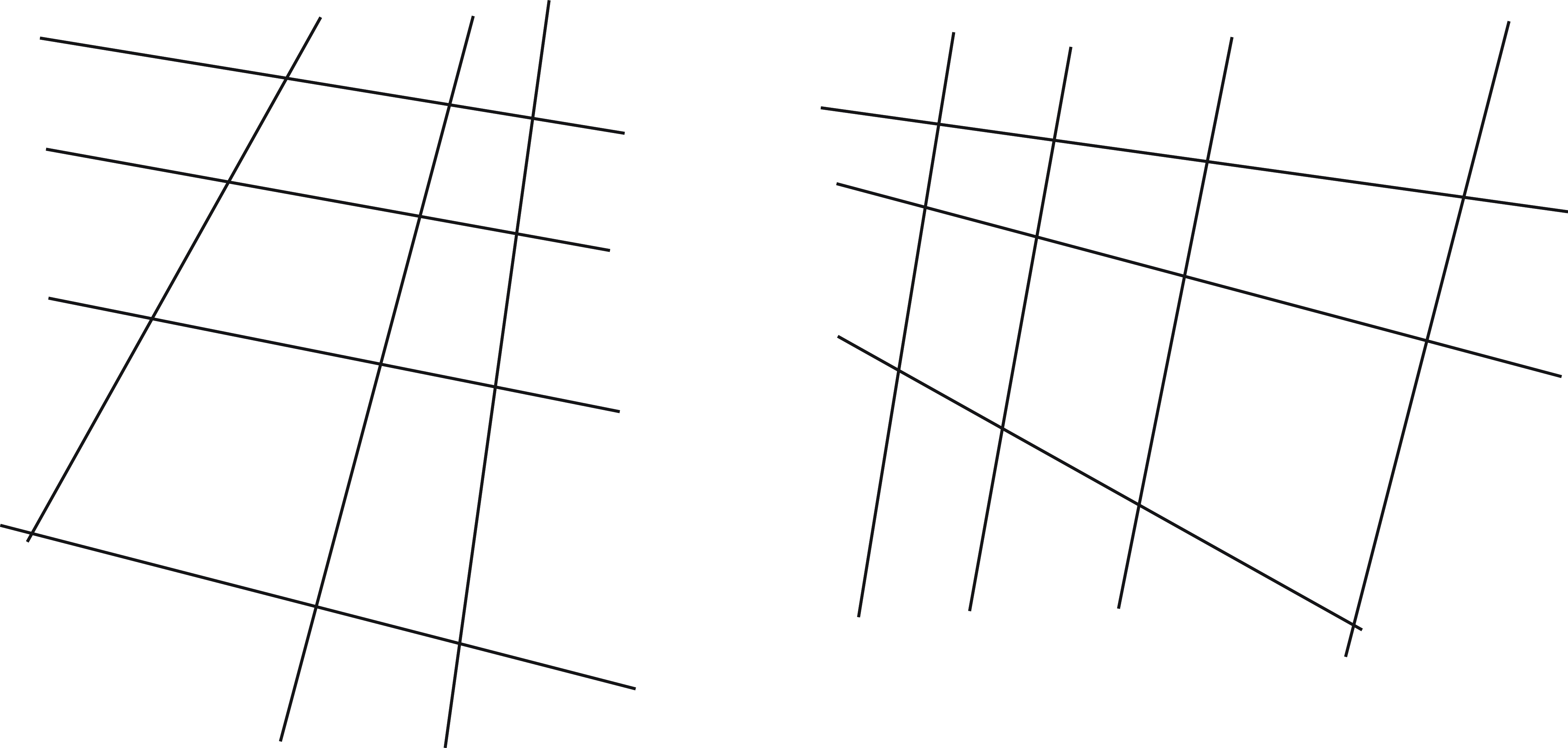
In the arrangement in the left, there are two vanishing points (the points in which parallel lines intersect) and both are above the drawing, compatible with the horizon line. However, on the drawing on the right, one of the vanishing points is below the figure and gives the impression that the camera is looking at a vertical wall (the camera seems to be higher than the visible part of the wall). The horizon line of the plane (the line that connects both vanishing points) is horizontal in the left drawing and vertical on the right one.
3.7 Motion Blur
When we are in a moving car and we take a picture from the passenger window, often images will appear blurring, especially when taken at night (Figure 3.9). Blur is due to the fact that the camera sensor is collecting light during a period of time while the car is moving and the picture that results is the average of several translated copies of the same image. However, note that not all of the objects are equally blurry. Things that are far away might still look sharp while things nearby appear very blurry.

The amount of blur is related to the car speed, the exposure time, and the distance between the camera and each object in the scene. We will talk more about how camera motion relates to distance in .
3.8 Accidents Happen
Principle of continuity. In the following drawing, we see one wave and one line:

Despite this, other groupings are also possible.
We learned about the generic view principle in , and this idea comes up a lot in computer vision. But it turns out that in most photographs it’s easy to find accidents. This is because photos contain so many things, thousands of tiny images, and there are so many coincidences that could occur. Figure 3.10 shows a famous photo and we will look for some coincidences in it. The coincidences are of a specific variety: generically, if you see smooth, continuous line segments you assume that they lie on a single object because it’s quite a coincidence for two objects to line up just so their contours perfectly align. The gestalt psychologists called this the principle of continuity. The insets for Figure 3.10 show several locations in the photo “Migrant Mother” by Dorothea Lange where exactly this happens. Can you find more?

You have to be careful about this when developing vision algorithms. If you assume no accidents will happen, then you will be in for some trouble. This is one reason why older, rule-based methods failed, because they did not handle exceptions to the rules.
3.9 Cues for Support
When can we tell by looking that one object supports another? Consider the ball over a surface depicted in . The drop shadow provides a strong cue that the ball is above the surface in Figure 3.11 (a) and Figure 3.11 (c), while the slack string provides evidence for the ball being on the surface in figures Figure 3.11 (b) and Figure 3.11 (c). Only is a doctored photograph.
In which of these figures does the ball appear to be in contact with the ground plane?

3.10 Looking at Raindrops
When it rains you get to see a rare sight. Every raindrop refracts a panorama of the scene around it (Figure 3.12). What you are seeing is not just one photo but hundreds of images of the scene, one in each raindrop, all from slightly different angles. It turns out specially designed cameras have been made that do the same thing, and they are called light field cameras. These cameras use an array of tiny lenses rather than raindrops, but the result is similar: they capture what the scene looks like from hundreds of different viewing angles, and from that density of information they can achieve many interesting tricks, such as triangulating the depth of objects in the scene and synthetically refocusing the image after it has been taken.

3.11 Plato’s Cave
In the Allegory of the Cave, Plato imagined a group of prisoners chained up in a cave whose only experience of the outside world is through shadows cast on the cave’s wall. When we look at images, we think we are directly seeing reality, but actually the situation is much more like Plato’s cave. An image is a crude projection of the underlying physical state. It collapses all the 3D geometry into a flat 2D grid of pixels. From any given viewing angle, most of the scene is occluded. Materials are only depicted in terms of how photons bounce off their surfaces; what’s below the surface may be completely omitted. When you look at a picture, think about all the things you cannot see. There’s more you don’t see than you do. One job of a vision system is to infer everything you can’t see given everything you can.
The allegory of the cave has several layers of indirection: the shadows are cast by puppets that are controlled by puppeteers who act out interpretations of the broader reality outside.
3.12 How Do You Know Something Is Wet?
Our visual system allows us to recognize not just objects, but also material. We can tell if something will feel hot or cold, soft or hard, smooth or rugged. We can also recognize if something is wet or not without touching it, as shown in Figure 3.13.

Why does sand look darker when it’s wet? Does everything wet look darker than when it is dry? How can we tell which parts of the sand are dark because they are wet and which ones are dark because they are under a shadow?
3.13 Concluding Remarks
Your brain is like a detective looking at all the clues that reveal what the world is made of.
This chapter was about learning to ask questions about what we see, why things look the way they do, and how do we recognize them. There are so many things that we see every day that we recognize by the way they look, and yet we seldom ask ourselves why they look that way. Why does the sky appear blue? Why does the moon always look the same? Why do hot things become redder? There are many other sources you can consult that explore why things look the way they do in the world. A beautiful book on this topic is by Marcel Minnaert [2], first published in 1937.
After reading this chapter, you will not know how to implement anything new, nor will you have learned new math or new algorithms. The goal of this chapter was to show you some of the questions you should ask about the visual world that you experience every day. The exercise to do now is to go around with your camera and take pictures of interesting visual phenomena.