37 Transfer Learning and Adaptation
37.1 Introduction
A common criticism of deep learning systems is that they are data hungry. To learn a new concept (e.g., “is this a dog?”) may require showing a deep net thousands of labeled examples of that concept. Conversely, humans can learn to recognize a new kind of animal after seeing it just once, an ability known as one-shot learning.
Correspondingly, few-shot learning refers to learning from just a few examples, and the zero-shot setting refers to when a model works out of the box on a new problem, with zero adaptation whatsoever.
Humans can do this because we have extensive prior knowledge we bring to bear to accelerate the learning of new concepts. Deep nets are data hungry when they are trained from scratch. But they can actually be rather data efficient if we give them appropriate prior knowledge and the means to use their priors to accelerate learning. Transfer learning deals with how to use prior knowledge to solve new learning problems quickly.
Transfer learning is an alternative to the ideas we saw last chapter, where we simply trained on a broad distribution of data so that most test queries happen to be things we have encountered before. Because it is usually impossible to train on all queries we might encounter, we often need to rely on transfer learning to adapt to new kinds of queries.
37.2 Problem Setting
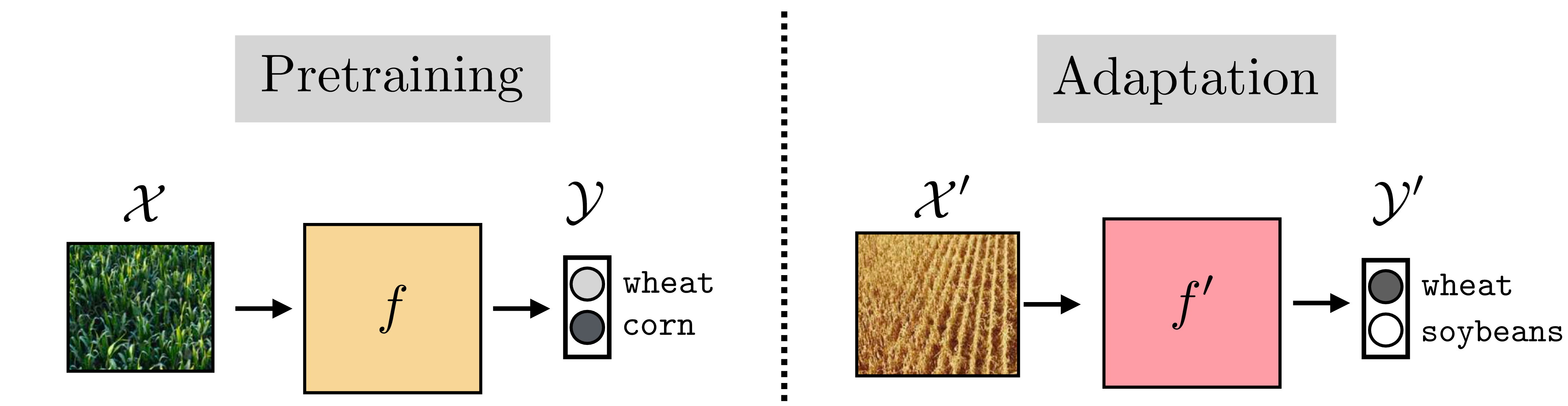
Suppose you are working at a farm and the drones that water the plants need to be able to recognize whether the crop is wheat or corn. Using the machinery we have learned so far, you know what to do: gather a big dataset of aerial photos of the crops and label each as either wheat or corn, then, train your favorite classifier to perform the mapping \(f_{\theta}: \mathcal{X} \rightarrow \{\texttt{wheat}, \texttt{corn}\}\). It works! The crop yield is plentiful. Now a new season rolls around and it turns out the value of corn has plummeted. You decide to plant soybeans instead. So, you need a new classifier; what should you do?
One option is to train a new classifier from scratch, this time on images of either wheat or soybeans. But you already know how to recognize wheat; you still have last year’s classifier \(f_{\theta}\). We would like to make use of \(f_{\theta}\) to accelerate the learning of this year’s new classifier. Transfer learning is the study of how to do this.
Transfer learning algorithms involve two parts:
Pretraining: how to acquire prior knowledge in the first place.
Adaptation: how to use prior knowledge to solve a new task.
In our example, the pretraining phase was training the wheat versus corn classifier, and the adaptation phase is updating that classifier to instead recognize wheat versus soybeans. This is visualized below in Figure 37.1.
The pretraining phase could just be regular training, which we only call pretraining in retrospect, once we decide to start adapting to a new problem. Or we can specifically design pretraining algorithms that are only meant as a warm up for the real event. Representation learning algorithms Chapter 30 are of this latter variety.
In the next sections we will describe specific kinds of transfer learning algorithms, which handle each of these stages in different ways. Then, in Section 37.9, we will reflect on the landscape of choices we have made, and we will see that transfer learning is better understood as a collection of tools, which can be combined in innumerable ways, rather than as a set of specific named algorithms.
37.3 Finetuning
There are many ways to do transfer learning. We will start with perhaps the simplest: when you encounter a new task, just keep on learning as if nothing happened.
Finetuning consists of initialializing a new classifier with the parameter vector from the pretrained model, and then training it as usual. In other words, finetuning is making small (fine) adjustments (tuning) to the parameters of your model to adapt it to do something slightly different than what it did before, or even something a lot different.
There are three stages: (1) pretrain \(f: \mathcal{X} \rightarrow \mathcal{Y}\), (2) initialize \(f^{\prime} = f\), and (3) finetune \(f^{\prime}: \mathcal{X}^{\prime} \rightarrow \mathcal{Y}^{\prime}\). The full algorithm is written in Algorithm 37.1, with \(f\) and \(f^{\prime}\) indicated as just a continually learning \(f_{\theta}\) with different iterates of \(\theta\) as learning progresses.
Finetuning is simple and works well. But there is one tricky bit we still need to deal with: What if the structure of \(f_{\theta}\) is incompatible with the new problem we wish to finetune on?
For example, suppose \(f\) is a neural net and \(\theta\) are the weights and biases of this net. Then the previous algorithm will only work if the dimensionality of \(\mathcal{X}\) matches the dimensionality of \(\mathcal{X}^{\prime}\), and the same for \(\mathcal{Y}\) and \(\mathcal{Y}^{\prime}\). This is because, for our neural net model, \(f_{\theta}\) must have the same shape inputs and outputs regardless of the values \(\theta\) takes on. What if we start with our net trained to classify between wheat and corn and now want to finetune it to classify between wheat, corn, and soybeans? The dimensionality of the output has changed from two classes to three.
To handle this it is common to cut off the last layer of the network and replace it with a new final layer that outputs the correct dimensionality. If the input dimensionality changes, you can do the same with the first layer of the network. Both these changes are shown next, in Figure 37.2.
To be precise, let \(f: \mathcal{X} \rightarrow \mathcal{Y}\) decompose as \(f= f_1 \circ f_2 \circ f_3\), with \(f_1: \mathcal{X} \rightarrow \mathcal{Z}_1\), \(f_2: \mathcal{Z}_1 \rightarrow \mathcal{Z}_2\), and \(f_3: \mathcal{Z}_2 \rightarrow \mathcal{Y}\). Now we wish to learn a function \(f^{\prime}: \mathcal{X}^{\prime} \rightarrow \mathcal{Y}^{\prime}\), which decomposes as \(f^{\prime}= f^{\prime}_1 \circ f^{\prime}_2 \circ f^{\prime}_3\), with \(f^{\prime}_1: \mathcal{X}^{\prime} \rightarrow \mathcal{Z}_1\), \(f_2: \mathcal{Z}_1 \rightarrow \mathcal{Z}_2\), and \(f_3: \mathcal{Z}_2 \rightarrow \mathcal{Y}^{\prime}\). The finetuning approach here would be to first learn \(f\); then, in order to learn \(f^{\prime}\), we initialize \(f^{\prime}_2\) with the parameters of \(f_2\) and initialize \(f^{\prime}_1\) and \(f^{\prime}_3\) randomly (i.e., train these from scratch).
37.3.1 Finetuning Subparts of a Network
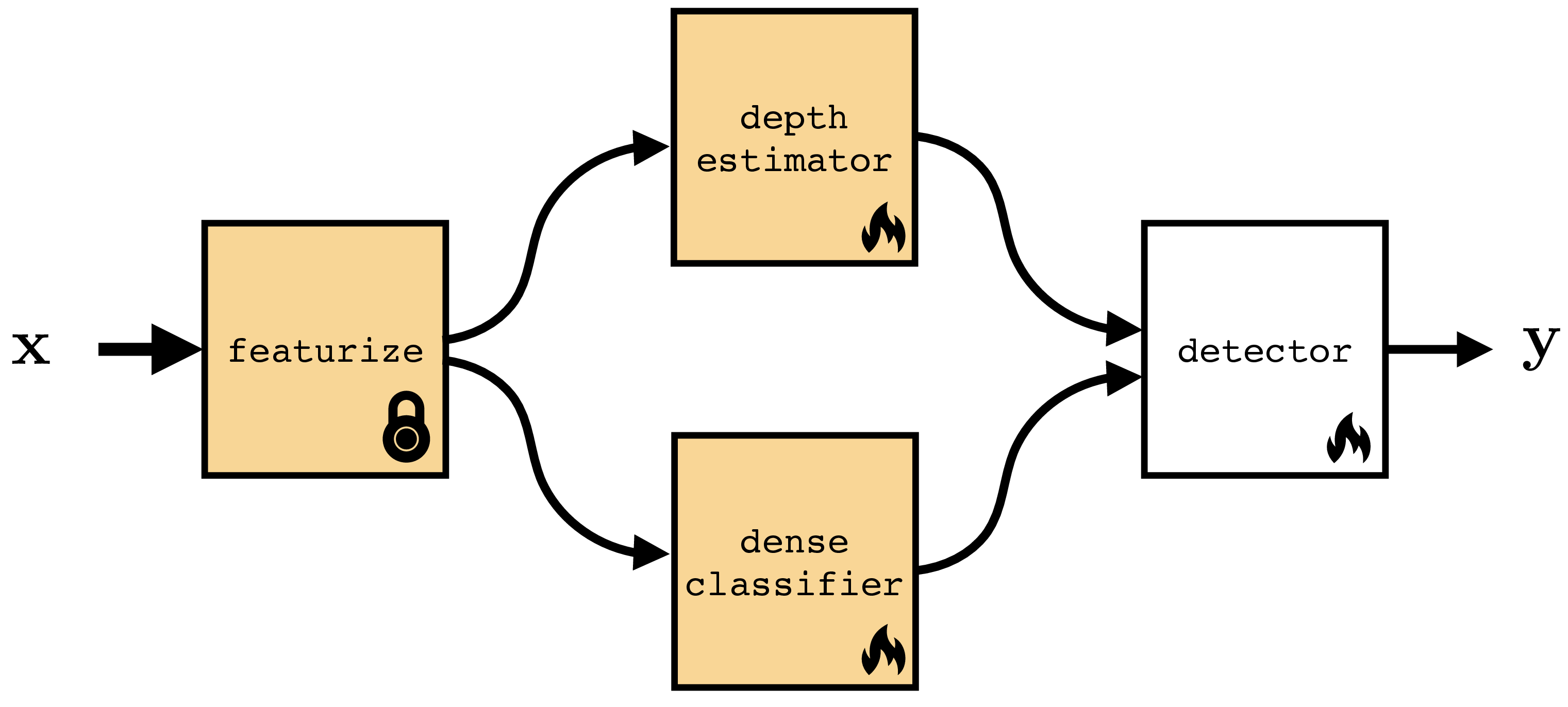
Figure 37.2 shows that you don’t have to finetune all layers in your network but can selectively finetune some and initialize others from scratch. In fact this strategy can be applied quite generally, where we initialize some parts of a computation graph from pretrained models and initialize others from scratch. There are many reasons why you might want to do this, or not. Sometimes you might have pretrained models that can perform just certain parts of what your full system needs to do. You can use these pretrained models and compose them together with layers initialized from scratch. Other times you may want to freeze certain layers to prevent them from forgetting their prior knowledge [1].
An example of both these use cases is given in Figure 37.3. In this example we imagine we are making a system to detect cars in street images. We have four modules that work together to achieve this. The featurize module converts the input image \(\mathbf{x}\) into a feature map (for example, this could be DINO [2], which we saw in Section 31.3.2). This module is pretrained and frozen; the idea is we have a good generic feature extractor that will work for many problems, and we do not need to update it for each new problem we encounter. Next we have two modules that take these feature maps as input and extract different kinds of useful information from them: (1) depth estimator predicts the depth map of the image (geometry), (2) dense classifier predicts a class label per-pixel (semantics). In our example, these two models are pretrained on generic images but we need to finetune them to work on the kind of street images we will be applying our detector to. Finally, given the depth and class predictions, we have a final module, detector, that searches for the image region that has the geometry and semantics of a car. This module outputs a bounding box \(\mathbf{y}\) indicating where it thinks the car is.
We will use the symbol  to indicate a frozen module and the symbol
to indicate a frozen module and the symbol  to indicate a module that is updated during the adaptation phase.
to indicate a module that is updated during the adaptation phase.
Within a single layer, it is also possible to update just a subspace of the full weight matrix. This can be an effective way to save memory (fewer weight gradients to track during backpropagation) or to regularize the amount of adaptation you are performing. One popular way to do so is to apply a low-rank update to the weight matrix [3].
37.3.2 Heads and Probes
As discussed previously, a model can be adapted by changing some or all of its parameters, or by adding entirely new modules to the computation graph. One important kind of new module is a read out module that takes some features from the computation graph as input and produces a new prediction as output. When these modules are linear, they are called linear probes. These modules are relatively lightweight (few parameters) and can be optimized with tools from linear optimization (where there are often closed form solutions). Because of this, linear probes are very popular as a way of repurposing a neural net to perform a new task. These modules are also useful as a way of assessing what kind of knowledge each feature map in the original network represents, in the sense that if a feature map can linearly classify some attribute of the data, then that feature maps knows something about that attribute. In this usage, linear probes are probing the knowledge represented in some layer of a neural net.
37.4 Learning from a Teacher
When we first encountered supervised learning in chapter Chapter 9, we described it as learning from examples. You are given a dataset of example inputs and their corresponding outputs and the task is to infer the relationship that can explain these input-output pairs:
![]()
This kind of learning is like having a very lazy teacher, who just gives you the answer key to the homework questions but does not provide any explanations and won’t answer questions. Taking that analogy forward, could we learn instead from a more instructive teacher?
One way of formalizing this setting is to consider the teacher as a well-trained model \(t: \mathcal{X} \rightarrow \mathcal{Y}\) that maps input queries to output answers. The student (the learner) observes both data \(\{x^{(i)}\}^N_{i=1}\) and has access to the teacher model \(t\). The student can learn to imitate the teacher’s outputs or can learn to match how the teacher processes the queries, matching intermediate activations of the teacher model.
![]()
Learning from examples can be considered a special case of learning from a teacher. It is the case where the teacher is the world and our only access to the teacher is observing outputs from it, that is, the examples \(y\) that match each input \(x\).
37.4.1 Knowledge distillation
Knowledge distillation is a simple and popular algorithm for learning a classifier from a teacher. We assume that the teacher is a well-trained classifier that outputs a \(K-1\)-dimensional probability mass function (pmf), \(t: \mathcal{X} \rightarrow \vartriangle^{K-1}\) (see Section 9.7.3). The student, a model \(f_{\theta}: \mathcal{X} \rightarrow \vartriangle^{K-1}\), simply tries to imitate the teacher’s output pmf: for each input \(x\) that the student sees, its goal is to output the same pmf vector as the teacher outputs for \(x\). The full algorithm is given in the diagram below.
![]()
Notice that this learning problem is very similar to softmax regression on labeled data, and a diagram comparing the two is given in Figure 37.4. The difference is that in knowledge distillation the targets are not one-hot (like in standard label prediction problems) but rather are more graded. The teacher outputs a probability vector that reflects the teacher’s belief as to the class of the input, rather than the ground truth class of the input. These beliefs may assign partial credit to classes that are similar to the ground truth, and this can actually make the teacher more informative than learning from ground truth labels.
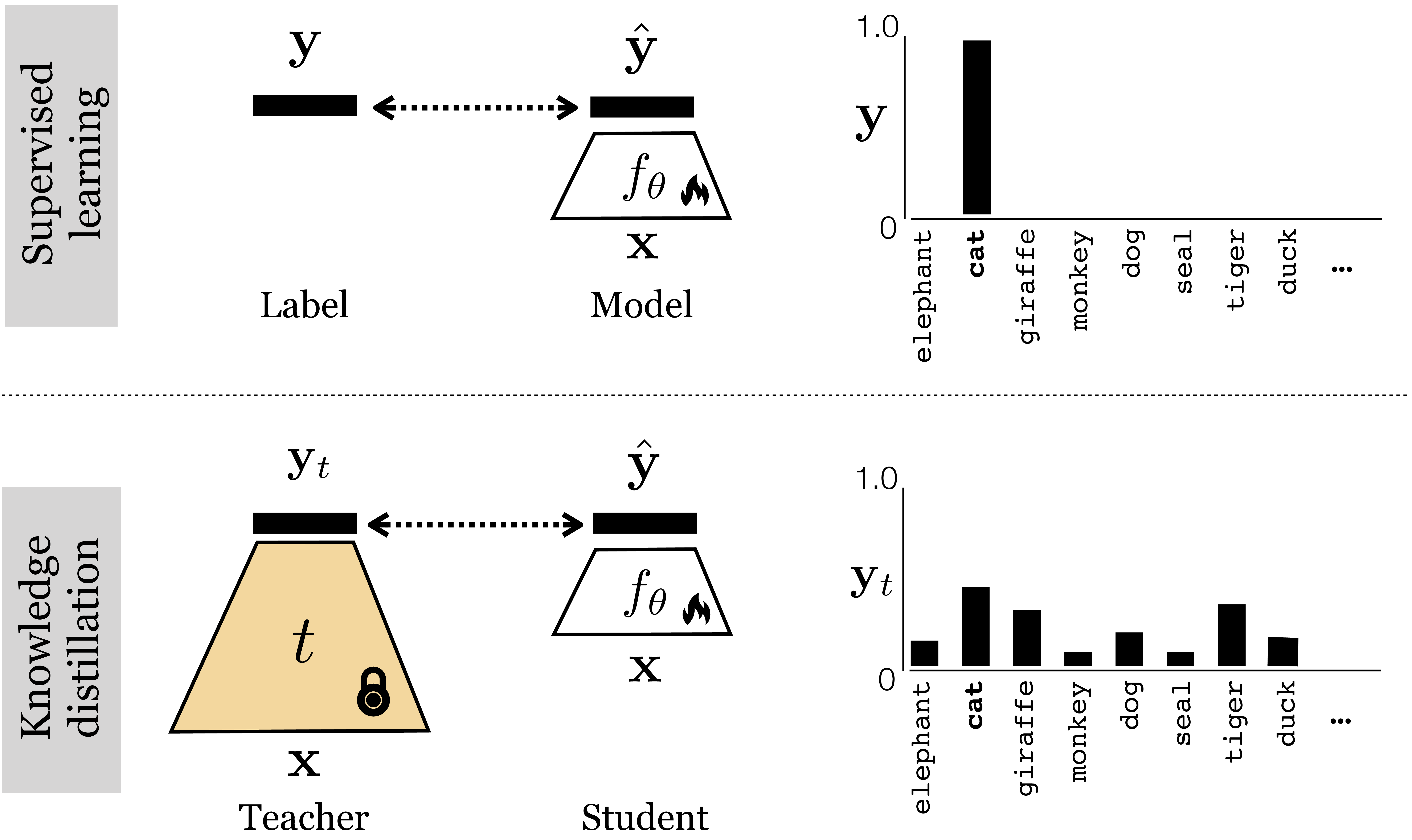
Think of it this way: the ground truth label for a domestic cat is “domestic cat” but the pmf vector output by a teacher, looking at a domestic cat, is more like “this image looks 90 percent like a domestic cat, but also 10 percent like a tiger.” That would be rather informative if the domestic cat in the image is a particularly large and fearsome looking one. The student not only gets to learn that this image is showing a domestic cat but also that this particular domestic cat is tiger-like. That tells the student something about both the class “domestic cat” and the class “tiger.” In this way the teacher can provide more information about the image than a one-hot label would, and in some cases this extra information can accelerate student learning [6].
37.5 Prompting
Prompting edits the input data to solve a new problem. Prompting is very popular in natural language processing (NLP), where text-to-text systems can have natural language prompts prepended to the string that is input to the model. For example, a general-purpose language model can be prompted with [Make sure to answer in French, X], for some arbitrary input X. Then the output will be a French translation of whatever the model would have responded to when queried with X.
The same can be done for vision systems. First, prompting methods from NLP can be directly used for prompting the text inputs to vision-language models [7] (Section 51.3). Second, prompting can also be applied to visual inputs. Just like we can prepend a textual input with text, we can prepend a visual input with visual data, yielding a method that may be called visual prompting [8], [9], [10]. This can be done by concatenating pixels, tokens, or other visual formats to a vision model’s inputs. This requires a model that takes variable-sized inputs; luckily this includes most neural net architectures, such as convolutional neural nets (CNNs), recurrent neural nets (RNNs), and transformers. Or, we can combine the visual prompt with the input query in other ways, such as by addition.
Prompting is visualized in Figure 37.5, where \(\oplus\) represents concatenation, addition, or potentially other ways of mixing prompts and input signals.
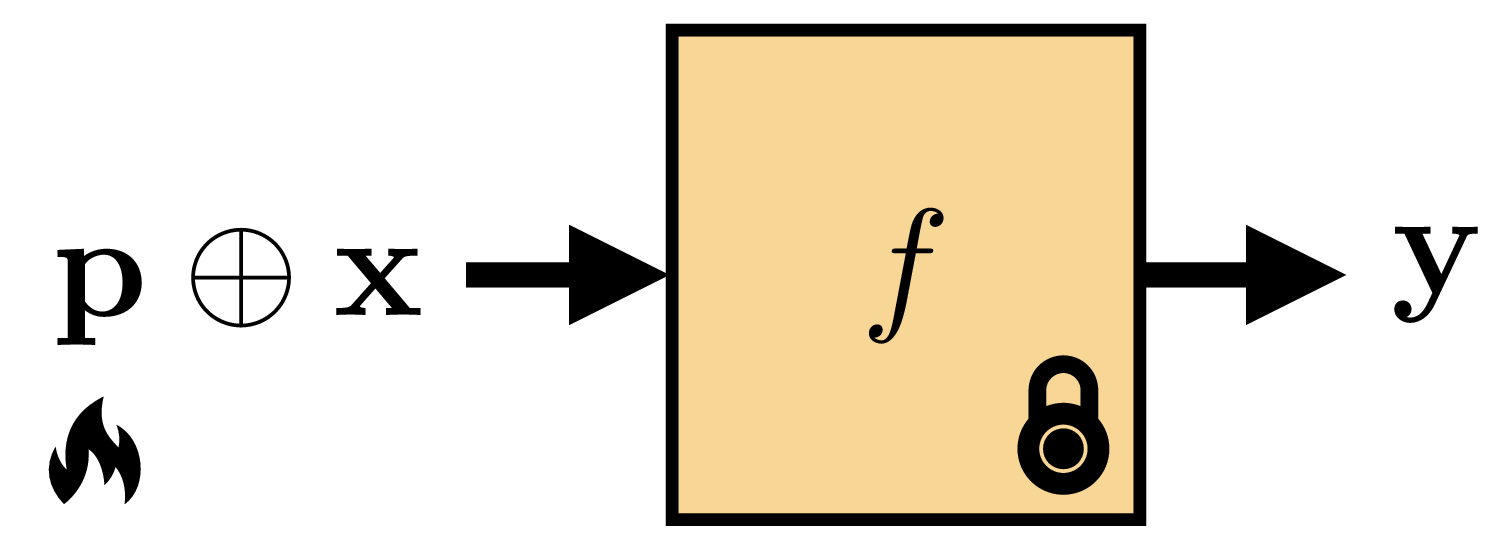
Let’s now look at several concrete ways of prompting a vision system. One simple way is to directly edit the input pixels, and this approach is shown in Figure 37.6:
Here, the prompt is an image \(\mathbf{p}\) that is added to the input image \(\mathbf{x}\). The prompt looks like noise, but it is actually an optimized signal that changes the model’s behavior. The top prompt was optimized to make the model predict the dog’s species and the bottom prompt was optimized to make the model predict the dog’s expression. Mathematically, this kind of prompting is very similar to the adversarial noise we covered in Section 35.6.1.
Because of its similarity to adversarial examples, early papers on prompting sometimes referred to it as adversarial reprogramming [11].
1 Here we require that the output space \(\mathcal{Y}\) is the same between the pretrained model and the prompted model. If we want to adapt to perform a task with a different output dimensionality then we can add a learned projection layer \(f^{\prime}\) after the pretrained \(f\), just like we did in Figure 37.2.
However, here we are not adding noise that hurts performance but instead adding noise that improves performance on a new task of interest. Given a set of \(M\) training examples that we would like to adapt to, \(\{\mathbf{x}^{(i)}, \mathbf{y}^{(i)}\}_{i=1}^M\), we learn a prompt via the following optimization problem: \[\begin{aligned} \mathop{\mathrm{arg\,min}}_{\mathbf{p}} \sum_{i=1}^M \mathcal{L}(f(\mathbf{x}^{(i)} + \mathbf{p}), \mathbf{y}^{(i)}) \end{aligned}\] where \(\mathcal{L}\) is the loss function for our problem.1
Rather than adding a prompt in pixel space, it is also possible to add a prompt to an intermediate feature space. Let’s look next at one way to do this. Jia, Tang, et al. [10] proposed to use a token as the prompt for a vision transformer architecture [12] (see chapter Chapter 26 for details on transformers). This new token is concatenated to the input of the transformer, which is a set of tokens representing image patches (Figure 37.7):
The token is a \(d\)-dimensional code vector and this vector is optimized to change the behavior of the transformer to achieve a desired result, such as increased performance on a new dataset or task. The attention mechanism works as usual except now all the input tokens also attend to the prompt. The prompt thereby modulates the transformation applied to the input tokens on the first layer, and this is how it affects the transformer’s behavior.
It is also possible to train a model to be promptable, so that at test time it adapts better to user prompts. An advantage of this approach is that we can train a model to understand human-interpretable prompts. For example, we could train the model so that its behavior can be adapted based on text instructions or based on user-drawn strokes (a representative example of both of these use cases can be found in [13]). In fact, we have already seen many such systems in this book: any system that interactively adapts to user inputs can be considered a promptable system. In particular, many promptable systems use the tools of conditional generative modeling (chapter Chapter 34 to train systems can are conditioned on user text instructions (e.g., [14], [15], which we cover in chapter Section 51.3.
37.6 Domain Adaptation
Often, the data we train on comes from a different distribution, or domain, than the data we will encounter at test time. For example, maybe we have trained a recognition system on internet photos and now we want to deploy the system on a self-driving car. The imagery the car sees looks very different than everyday photos you might find on the internet. Domain adaptation refers to methods for adapting the training domain to be more like the test domain, or vice versa. The first option is to adapt the test data, \(\{\mathbf{x}_{\texttt{test}}^{(i)},\mathbf{y}_{\texttt{test}}^{(i)}\}_{i=1}^N\) to look more like the training data. Then \(f\) should work well on both the training data and the test data. Or we can go the other way around, adapting the training data to look like the test data, before training \(f\) on the adapted training data. In either case, the trick is to make the distribution of test and train data identical, so that a method that works on one will work just as well on the other.
Commonly, we only have access to labels at training time, but may have plentiful unlabeled inputs \(\{\mathbf{x}^{\prime}_i\}_{i=1}^N\) at testing time. This setting is sometimes referred to as unsupervised domain adaptation. Here we cannot make use of test labels but we can still align the test inputs to look like the training inputs (or vice versa). One way to do so is to use a generative adversarial network (GAN; chapter Chapter 32 that translates the data in one domain to look identically distributed as the data in the other domain, as has been explored in e.g., [16], [17], [18]. A simple version of this algorithm is given in algorithm Algorithm 37.2.
You may notice that domain adaptation is very similar to prompting. Both edit the model’s inputs to make the model perform better. However, while prompting’s objective is to improve or steer model performance, domain adaptation’s objective is to make the inputs look more familiar. This means domain adaptation is applicable even when we don’t have access to the model or even know what the task will be.
37.7 Generative Data
Generative models (chapter Chapter 32) produce synthetic data that looks like real data. Could this ability be useful for transfer learning? At first glance it may seem like the answer is no: Why use fake data if you have access to the real thing?
However, generative data (i.e., synthetic data sampled from a generative model) is not just a cheap copy of real data. It can be more data, and it can be better data. It can be more data because we can draw an unbounded number of samples from a generative model. These samples are not just copies of the training datapoints but can interpolate and remix the training data in novel ways (chapter Chapter 32). Generative models can also produce better data because the data comes coupled with a procedure that generated it, and this procedure has structure that can be exploited to understand and manipulate the data distribution.
One such structure is latent variables (chapter Chapter 33). Suppose you have generated a training set of outdoor images with a latent variable generative model. You want to train an object classifier on this data. You notice that the images never show a cow by a beach, but you happen to live in northern California where the cows love to hang out on the coastal bluffs. How can you adapt your training data to be useful for detecting these particular cows? Easy: just edit the latent variables of your model to make it produce images of cows on beaches. If the model is pretrained to produce all kinds of images, it may have the ability to generate cows on beaches with just a little tweaking.
It is currently a popular area of research to use large, pretrained generative models as data sources for many applications like this [19], [20], [21]. In this usage, you are transferring knowledge about data, to accelerate learning to solve a new problem. The function being learned can be trained from scratch, but it is leveraging the generative model’s knowledge about what images look like and how the world works.
37.8 Other Kinds of Knowledge that Can Be Transferred
This chapter has covered a few different kinds of knowledge that can be pretrained and transferred. We have not aimed to be exhaustive. As an exercise, you can try the following: (1) download the code for your favorite learning algorithm, (2) pick a random line, (3) and figure out how you can pretrain whatever is being computed on that line. Maybe you picked the line that defines the loss function; that can be pretrained! The term for this is a learned loss (e.g., [22]). Or maybe you picked the line optim.SGD... that defines the optimizer: the optimizer can also be pretrained. This is called a learned optimizer (e.g., [23]). It’s currently less common to adapt modules like these (they are usually just pretrained and then held fixed), but in principle there is no reason why you can’t. Maybe you, reader, can figure out a good way to do so.
37.9 A Combinatorial Catalog of Transfer Learning Methods
Many of the methods we introduced previously follow a similar format:
Pretrain one component of the system.
Adapt that component and/or other components.
In table Table 32.1, we present the relationship these methods by framing them all as empirical risk minimization with different components optimized during pretraining and/or during adaptation.
| Method | Learning | Inference |
|---|---|---|
| Generative data | \(\arg\min_{\textcolor{{rgb}{0.8, 0.0, 0.2}}{\theta}} \mathbb{E}_{\textcolor{pretrained_color}{x},\textcolor{pretrained_color}{y}}[\mathcal{L}(f_{\textcolor{adapted_color}{\theta}}(\textcolor{pretrained_color}{x}), \textcolor{pretrained_color}{y})]\) | \(f_{\textcolor{adapted_color}{\theta}}(x)\) |
| Distillation | \(\arg\min_{\textcolor{adapted_color}{\theta}} \mathbb{E}_{x}[\mathcal{L}(f_{\textcolor{adapted_color}{\theta}}(x), \textcolor{pretrained_color}{t}(x))]\) | \(f_{\textcolor{adapted_color}{\theta}}(x)\) |
| Prompting | \(\arg\min_{\textcolor{adapted_color}{\epsilon}} \mathbb{E}_{x,y}[\mathcal{L}(f_{\textcolor{pretrained_color}{\theta}}(x \oplus \textcolor{adapted_color}{\epsilon}), y)]\) | \(f_{\textcolor{pretrained_color}{\theta}}(x \oplus \textcolor{adapted_color}{\epsilon})\) |
| Finetuning | \(\arg\min_{\textcolor{both_color}{\theta}} \mathbb{E}_{x,y}[\mathcal{L}(f_{\textcolor{both_color}{\theta}}(x), y)]\) | \(f_{\textcolor{both_color}{\theta}}(x)\) |
| Probes / heads | \(\arg\min_{\textcolor{adapted_color}{\phi}} \mathbb{E}_{x,y}[\mathcal{L}(h_{\textcolor{adapted_color}{\phi}}(f_{\textcolor{pretrained_color}{\theta}}(x)), y)]\) | \(h_{\textcolor{adapted_color}{\phi}}(f_{\textcolor{pretrained_color}{\theta}}(x))\) |
| Learned loss | \(\arg\min_{\textcolor{adapted_color}{\theta}} \mathbb{E}_{x,y}[\textcolor{pretrained_color}{\mathcal{L}}(f_{\textcolor{adapted_color}{\theta}}(x), y)]\) | \(f_{\textcolor{adapted_color}{\theta}}(x)\) |
| Learned optimizer | \(\textcolor{pretrained_color}{\arg\min}_{\textcolor{adapted_color}{\theta}} \mathbb{E}_{x,y}[\mathcal{L}(f_{\textcolor{adapted_color}{\theta}}(x), y)]\) | \(f_{\textcolor{adapted_color}{\theta}}(x)\) |
37.10 Sequence Models from the Lens of Adaptation
There is one more important class of adaptation algorithms: any model of a sequence that updates its behavior based on the items in the sequence it has already seen. We can consider such models as adapting to the earlier items in the sequence. CNNs, transformers, and RNNs all have this ability, among many other models, because they can all process sequences and model dependences between earlier items in the sequence and later decisions. However, the ability of sequence models to handle adaptation is clearest with RNNs, which we will focus on in this section.
RNNs update their hidden states as they process a sequence of data. These changes in hidden state change the behavior of the mapping from input to output. Therefore, RNNs adapt as they process data. Now consider that learning is the problem of adapting future behavior as a function of past data. RNNs can be run on sequences of frames in a movie or on sequences of pixels in an image. They can also be run on sequences of training points in a training dataset! If you do that, then the RNN is doing learning, and learning such an RNN can be considered metalearning. For example, let’s see how we can make an RNN do supervised learning. Supervised learning is the problem of taking a set of examples \(\{\mathbf{x}^{(i)},\mathbf{y}^{(i)}\}_{i=1}^N\) and inferring a function \(f: \mathbf{x} \rightarrow \mathbf{y}\). Without loss of generality, we can define an ordering over the input set, so the learning problem is to take the sequence \(\{\mathbf{x}^{(1)}, \mathbf{y}^{(1)}, \ldots, \mathbf{x}^{(n)}, \mathbf{y}^{(n)}\}\) as input and produce \(f\) as output.
The goal of supervised learning is that after training on the training data, we should do well on any random test query. After processing the training sequence \(\{\mathbf{x}^{(1)}, \mathbf{y}^{(1)}, \ldots, \mathbf{x}^{(n)}, \mathbf{y}^{(n)}\}\), an RNN will have arrived at some setting of its hidden state. Now if we feed the RNN a new query \(\mathbf{x}^{(n+1)}\), the mapping it applies, which produces an output \(\mathbf{y}^{(n+1)}\), can be considered the learned function \(f\). This function is defined by the parameters of the RNN along with its hidden state that was learned from the training sequence. Since we can apply this \(f\) to any arbitrary query \(\mathbf{x}^{(n+1)}\), what we have is a learned function that operates just like a function learned by any other learning algorithm; it’s just that in this case the learning algorithm was an RNN.
Another name for this kind of learning, which is emergent in a sequence modeling problem, is in-context learning.
37.11 Concluding Remarks
Transfer learning and adaptation are becoming increasingly important as we move to ever bigger models that have been pretrained on ever bigger datasets. Until we have a truly universal model, which can solve any problem zero-shot, adaptation will remain an important topic of study.