30 Representation Learning
30.1 Introduction
In this book we have seen many ways to represent visual signals: in the spatial domain versus frequency domain, with pyramids and filter responses, and more. We have seen that the choice of representation is critical: each type of representation makes some operations easy and others hard. We also saw that deep neural networks can be thought of as transforming the data, layer by layer, from one representation into another and another. If representations are so important, why not set our objective to be “come up with the best representation possible.” In this chapter, we will try to do exactly that.
This chapter is primarily an investigation of objectives. We will identify different objective functions that capture properties of what it means to be a good representation. Then we will train deep nets to optimize these objectives, and investigate the resulting learned representations.
30.2 Problem Setting
Before diving in, let us present the basic problem statement and the notation we will be using throughout this chapter.
The goal of representation learning is to learn to map from datapoints, \(\mathbf{x} \in \mathcal{X}\), to abstract representations, \(\mathbf{z} \in \mathcal{Z}\), as schematized in Figure 30.1:
We call this mapping an encoding and learn an function \(f: \mathcal{X} \rightarrow \mathcal{Z}\). Typically both \(\mathbf{x}\) and \(\mathbf{z}\) are high-dimensional vectors, and \(\mathbf{z}\) is called a vector embedding of \(\mathbf{x}\). The mapping \(f\) is trained so that \(\mathbf{z}\) has certain desirable properties: common desiderata include that \(\mathbf{z}\) be lower dimensional than \(\mathbf{x}\); that the distribution of \(\mathbf{z}\) values, that is, \(p(\mathbf{z})\), has a simple structure (such as being the unit normal distribution); and that the dimensions of \(\mathbf{z}\) be independent factors of variation, that is, the representation should be disentangled [1]. In this way \(\mathcal{Z}\) is a simpler, more abstracted, or better organized representational space than \(\mathcal{X}\), as reflected in the shapes in Figure 30.1.
30.3 What Makes for a Good Representation?
A good representation is one that makes subsequent problem solving easier. Below we discuss several desiderata of a good representation.
30.3.1 Compression
A good representation is one that is parsimonious and captures just the essential characteristics of the data necessary for tasks of human interest. There are at least three senses in which compressed representations are desirable.
Compressed representations require less memory to store.
Compression is a way to achieve invariance to nuisance factors. Depending on what the representation will be used for, nuisances might include camera noise, lighting conditions, and viewing angle. If we can factor out those nuisances and discard them from our representation, then the representation will be more useful for tasks like object recognition where camera and lighting may change without affecting the semantics of the observed object.
Compression is an embodiment of Occam’s razor: among competing hypotheses that all explain the data equally well, the simplest is most likely to be true. As we will see below, and in the next chapter, many representation learning algorithms seek simple representations from which you can regenerate the raw data (e.g., autoencoders). Such representations explain the data in the formal sense that they assign high likelihood to the data. This is the same sense to which the idea of Bayesian Occam’s razor applies Section 11.3.2; see [2] for a mathematical treatment of this idea. Therefore, we can state Occam’s razor for representation learning: among two representations that fit the data equally well, give preference to the more compressed.
This version of Occam’s razor is also known as the minimum description length principle [3].
Many representation learning algorithms capture these goals by penalizing or constraining the complexity of the learned representation. Such a penalty must be paired with some other objective or else it will lead to a degenerate solution: just make the representation contain nothing at all. Usually we try to compress the signal in certain ways while preserving other aspects of the information it carries. Autoencoders and contrastive learning, which we will describe subsequently, are two representation learning algorithms based on the idea of compression.
30.3.2 Prediction
The whole purpose of having a visual system is to be able to take actions that achieve desirable future outcomes. Predicting the future is therefore very important, and we often want representations that act as a good substrate for prediction.
The idea of prediction can be generalized to involve more than just predicting the future. Instead we may want to predict the past (i.e., given when I’m seeing today, what happened yesterday?), or we may want to predict gaps in our measurements, a problem known as imputation. Filling in missing pixels in a corrupted image is an example of imputation, as is superresolving a movie to play at a higher framerate. We may even want to perform more abstract kinds of predictions, like predicting what some other agent is thinking about (a problem called theory of mind). In general, prediction can refer to the inference of any arbitrary property of the world given observed data. Facilitating the prediction of important world properties—the future, the past, mental states, cause and effect, and so on—is perhaps the defining property of a good representation.
Most representation learning algorithms in vision are about learning compressed encodings of the world that are also predictive of the future (and therefore a good substrate for decision making). Beyond just compression and prediction, some works have explored other goals, including that a representation be disentangled [1], interpretable [4], and actionable [5] (you can use it as an effective substrate for control). All these goals—compression, prediction, interpretability, and so on—are not in contrast to each other but rather overlap; for example, more compressed representations may be simpler and hence easier for a human to interpret.
30.3.3 Types of Representation Learners
Representation learning algorithms are mostly differentiated by the objective function they optimize, as well as the constraints on their hypothesis space. We explore a variety of common objectives in the following sections, and summarize how these relate to the core principles of compression and prediction in Table 30.1.
| Learning Method | Learning Principle | Short Summary |
|---|---|---|
| Autoencoding | Compression | Remove redundant information |
| Contrastive | Compression | Achieve invariance to viewing transformations |
| Clustering | Compression | Quantize continuous data into discrete categories |
| Future prediction | Prediction | Predict the future |
| Imputation | Prediction | Predict missing data |
| Pretext tasks | Prediction | Predict abstract properties of your data |
30.4 Autoencoders
Autoencoders are one of the oldest and most common kinds of representation learners [6], [7]. An autoencoder is a function that maps data back to itself (hence the “auto”), but via a low-dimensional representational bottleneck, as shown in Figure 30.2:
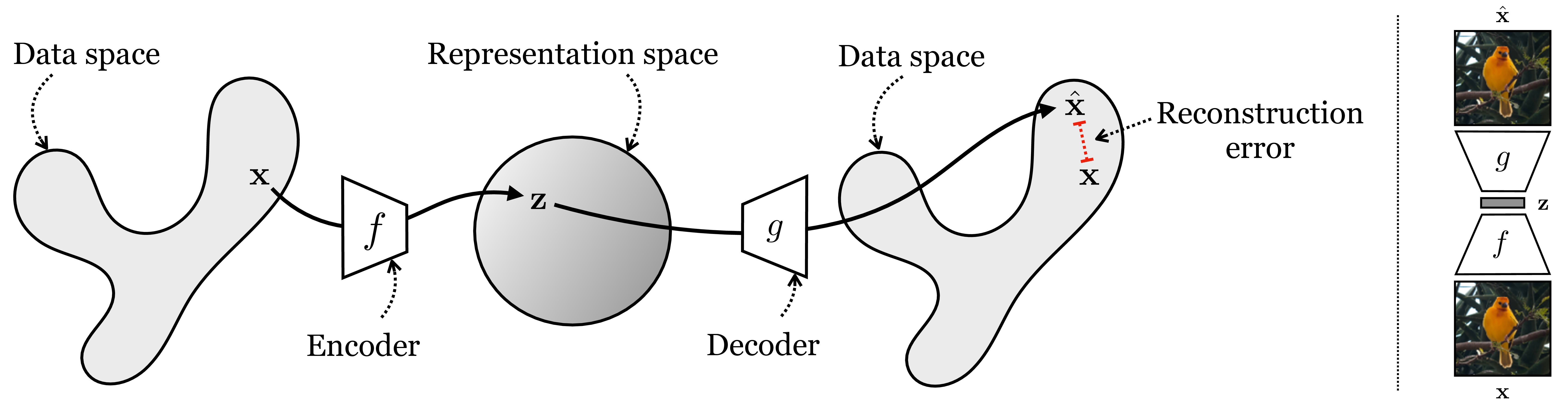
On the right of this figure is an example of an autoencoder applied to an image. At first glance this might not seem very useful: the output is the same as the input! The key trick is to impose constraints on the intermediate representation \(\mathbf{z}\), so that it becomes useful. The most common constraint is compression: \(\mathbf{z}\) is a low-dimensional, compressed representation of \(\mathbf{x}\).
To be precise, an autoencoder \(F\) consists of two parts, an encoder \(f\) and a decoder \(g\), with \(F = g \circ f\). The encoder, \(f: \mathbb{R}^N \rightarrow \mathbb{R}^M\), maps high-dimensional data \(\mathbf{x} \in \mathbb{R}^N\) to a vector embedding \(\mathbf{z} \in \mathbb{R}^M\). Typically, the key property is that \(M < N\), that is, we have performed dimensionality reduction (although autoencoders can also be constructed without this property, in which case they are not doing dimensionality reduction but instead may place other explicit or implicit constraints on \(\mathbf{z}\)). The decoder, \(g: \mathbb{R}^M \rightarrow \mathbb{R}^N\) performs the inverse mapping to \(f\), and ideally \(g\) is exactly the inverse function \(f^{-1}\). Because it may be impossible to perfectly invert \(f\), we use a loss function to penalize how far we are from perfect inversion, and a typical choice is the squared error reconstruction loss, \(\mathcal{L}_{\texttt{recon}}(\hat{\mathbf{x}}, \mathbf{x}) = \left\lVert\hat{\mathbf{x}} - \mathbf{x}\right\rVert_2^2\).
Then the learning problem is: \[f^*,g^* = \mathop{\mathrm{arg\,min}}_{f,g} \mathbb{E}_{\mathbf{x}} \left\lVert g(f(\mathbf{x})) - \mathbf{x}\right\rVert_2^2 \tag{30.1}\]
The idea is to find a lower dimensional representation of the data from which we are able to reconstruct the data. An autoencoder is fine with throwing away any redundant features of the raw data but is not happy with actually losing information. The particular loss function determines what kind of information is preferred when the bottleneck cannot support preserving all the information and a hard choice has to be made. The \(L_2\) loss decomposes as \(\left\lVert g(f(\mathbf{x})) - \mathbf{x}\right\rVert_2^2 = \sqrt{\sum_i (g(f(\mathbf{x}))_i - x_i)^2}\), that is, a sum over individual pixel errors. This means that it only cares about matching each individual pixel intensity \(g(f(\mathbf{x}))_i\) to the ground truth \(x_i\) and does not directly penalize patch-level statistics of \(\mathbf{x}\) (i.e., statistics \(\phi(\mathbf{x})\) that do not factorize as a sum \(\sum_i \psi_i(x_i)\) over per-pixel functions \(\psi_i\) for any possible set of functions \(\{\psi_i\}\)). Autoencoders can also be constructed using loss functions that penalize higher-order statistics of \(\mathbf{x}\), and this allows, for example, penalizing errors in the reconstruction of edges, textures, and other perceptual structures beyond just pixels [8].
The learning diagram for the basic \(L_2\) autoencoder looks like this:

Autoencoders may not seem like much at first glance, but they actually appear all over the place, and many methods in this book can be considered to be special kinds of autoencoders, if you squint. Two examples: the steerable pyramid from Chapter 23 is an autoencoder, and the CycleGAN algorithm from Chapter 32 is also an autoencoder. See if you can find more examples.
The optimizer is arbitrary but a typical choice would be gradient descent. The functional form of \(f\) and \(g\) are typically deep neural nets. The output is a learned data encoder \(f\). We also get a learned decoder \(g\) as a byproduct, which has its own uses, but, for the purpose of representation learning, is usually discarded and only used as scaffolding for training what we really care about, namely \(f\).
Closely related to autoencoders are other dimensionality reduction algorithms like principle components ananlysis (PCA). In fact, an \(L_2\) autoencoder, for which both \(f\) and \(g\) are linear functions, learns an \(M\)-dimensional embedding that spans the same subspace as a PCA projection to \(M\)-dimensions [9].
30.4.1 Experiment: Do Autoencoders Learn Useful Representations?
It is clear from the above that autoencoders will learn a compressed representation of the data, but do they learn a useful representation? Of course the answer to this question depends on what we will use the representation for. Let’s explore how autoencoders work on a simple data domain, consisting just of colored circles, triangles, and squares. The data consists of 64,000 images, samples of which are shown in Figure 30.4.

Each shape has a randomized size, position, and rotation. Each shape’s color is sampled from one of eight color classes (orange, green, purple, etc.) plus a small random perturbation.
For the autoencoder architecture we use a convolutional encoder and decoder, each with six convolutional layers interspersed with relu nonlinearities and a 128-dimensional bottleneck (i.e., \(M=128\)). We train this autoencoder for 20,000 steps of stochastic gradient descent, using the Adam optimizer [10] with a batch size of 128.
After training, does this autoencoder obtain a good representation of the data? To answer this question, we need ways of evaluating the quality of a representation. There are many ways and indeed how to evaluate representations is an open area of research. But here we will stick with a very simple approach: see if the nearest neighbors, in representational space, are meaningful.
We can test this in two ways: (1) for a given query, visualize the images in the dataset whose embeddings are nearest neighbors to the query’s embedding, and (2) measure the accuracy of a one-nearest-neighbor classifier in embedding space. Below, in Figure 30.5, we show both these analyses.
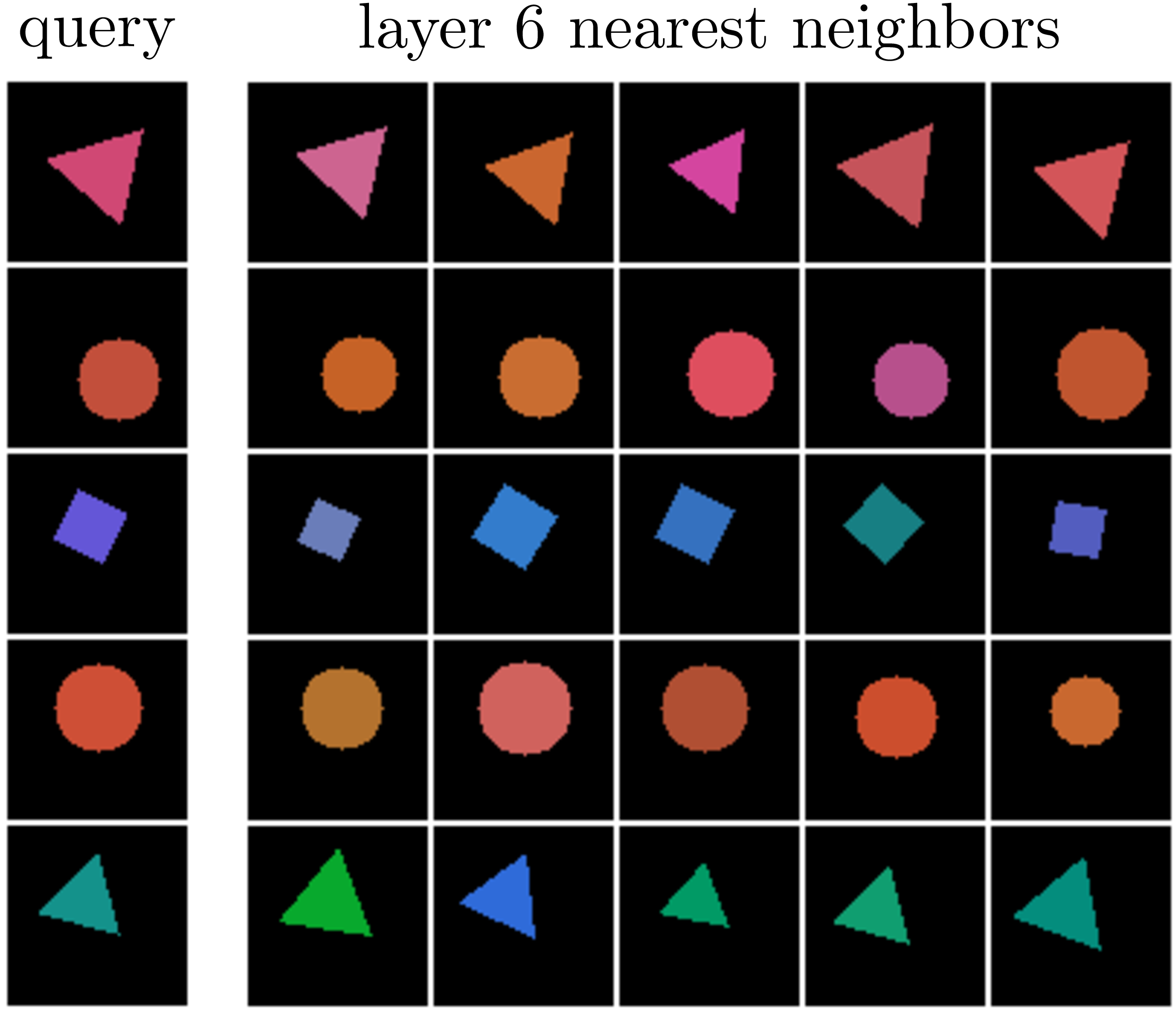
Recall that every layer of a neural net can be considered as an embedding (representation) of the data. On the left we show the nearest neighbors to a set of query images, using the layer 6 embeddings of the data as the feature space in which to measure distance (i.e., nearness). Since we have a six-layer encoder, layer 6 is the bottleneck layer, the output of the full encoder \(f\). Notice that the neighbors are indeed similar to the queries in terms of their colors, shapes, positions, and rotations; it seems the autoencoder produced a meaningful representation of the data!
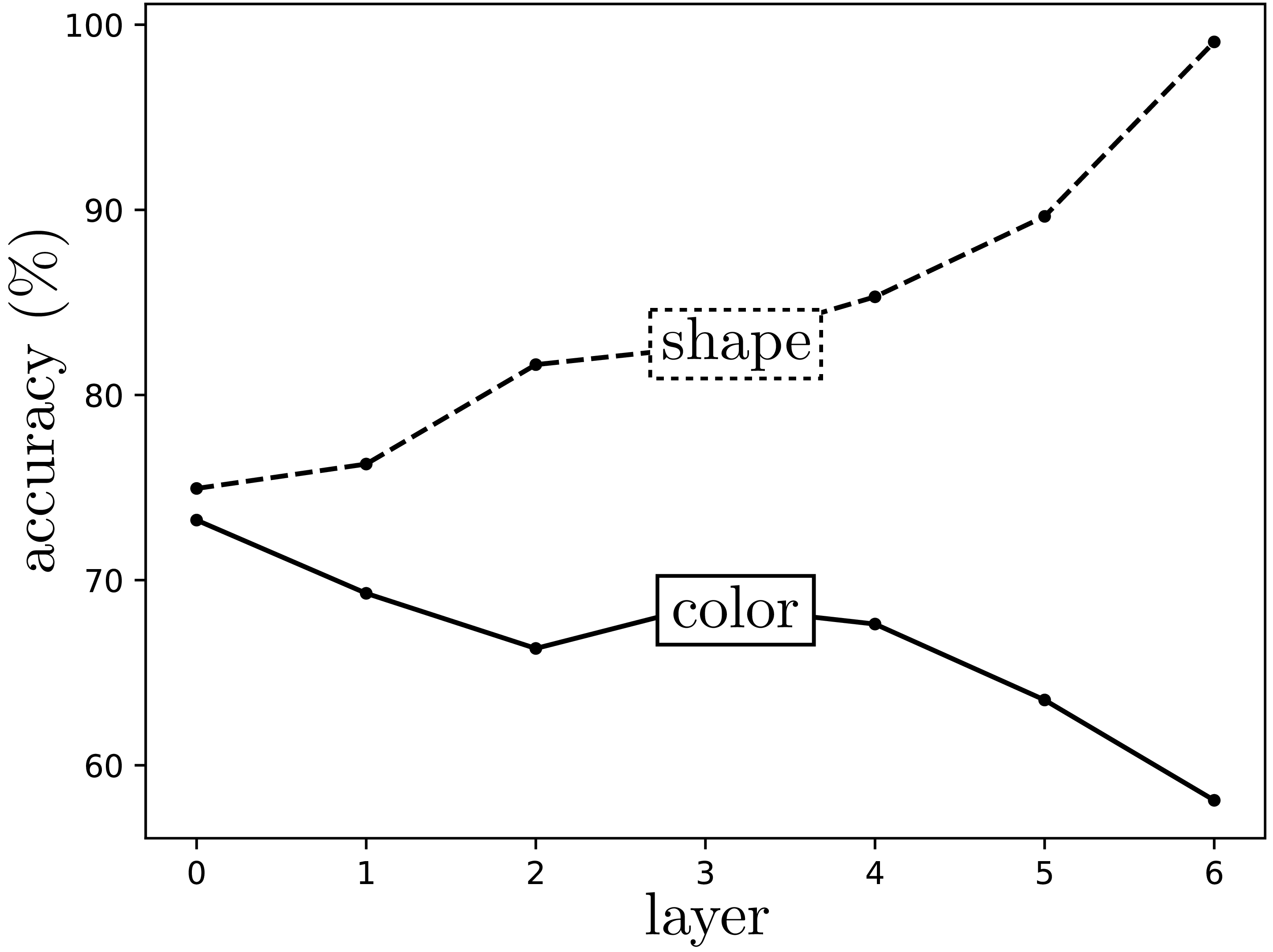
Next we will probe a bit deeper, and ask, how effective are these embeddings at classifying key properties of the data? On the right we show the accuracy of a one-nearest-neighbor color classifier (between the eight color classes) and a shape classifier (circle vs. triangle vs. square) applied on embedding vectors at each layer of the autoencoder’s encoder. The zeroth layer corresponds to measuring distance in the raw pixel space; interestingly, the color classifier does its best on this raw representation of the data. That’s because the pixels are a more or less direct representation of color. Color classification performance gets worse and worse as we go deeper in the encoder. Conversely, shape is not explicit in raw pixels, so measuring distance in pixel-space does not yield good shape nearest neighbors. Deeper layers of the encoder give representations that are increasingly sensitive to shape similarity, and shape classification performance gets better. In general, there is no one representation that is universally the best. Each is good at capturing some properties of the data and bad at capturing others. As we go deeper into an autoencoder, the embeddings tend to become more abstracted and therefore better at capturing abstract properties like shape and worse at capturing superficial properties like color. For many tasks—object recognition, geometry understanding, future prediction—the salient information is rather abstracted compared to the raw data, and therefore for these tasks deeper embeddings tend to work better.
30.5 Predictive Encodings
We have already seen many kinds of predictive learning, indeed almost any function can be thought of as making a prediction. In predictive representation learning, the goal is not to make predictions per se, but to use prediction as a way to train a useful representation. The way to do this is first encode the data into an embedding \(\mathbf{z}\), then map from the embedding to your target prediction. This gives a composition of functions, just like with the autoencoder, that can be trained with a prediction task and yield a good data encoder. The prediction task is a pretext task for learning good representations.
Neuroscientists think the brain also uses prediction to better encode sensory signals, but focus on a different part of the problem. The idea of predictive coding states that the sensory cortex only transmits the difference between its predictions and the actual observed signal [11]. This chapter presents how to learn a representation that can make good predictions in the first place. Predictive coding focuses on one thing you can do with such a representation: use it to compress future signals by just transmitting the surprises.
Different kinds of prediction tasks have been proposed for learning good representations, and depending on the properties you want in your representation different prediction tasks will be best. Examples include predicting future frames in a video [12] and predicting the next pixel in an image given a sequence of preceding pixels [13]. It is also possible to use an image’s semantic class as the prediction target. In that case, the prediction problem is identical to training an image classifier, but the goal is very different. Rather than obtaining a good classifier at the end, our goal is instead to obtain a good image encoding (which is predictive of semantics) [14]. These three examples are visualized below (Figure 30.6).
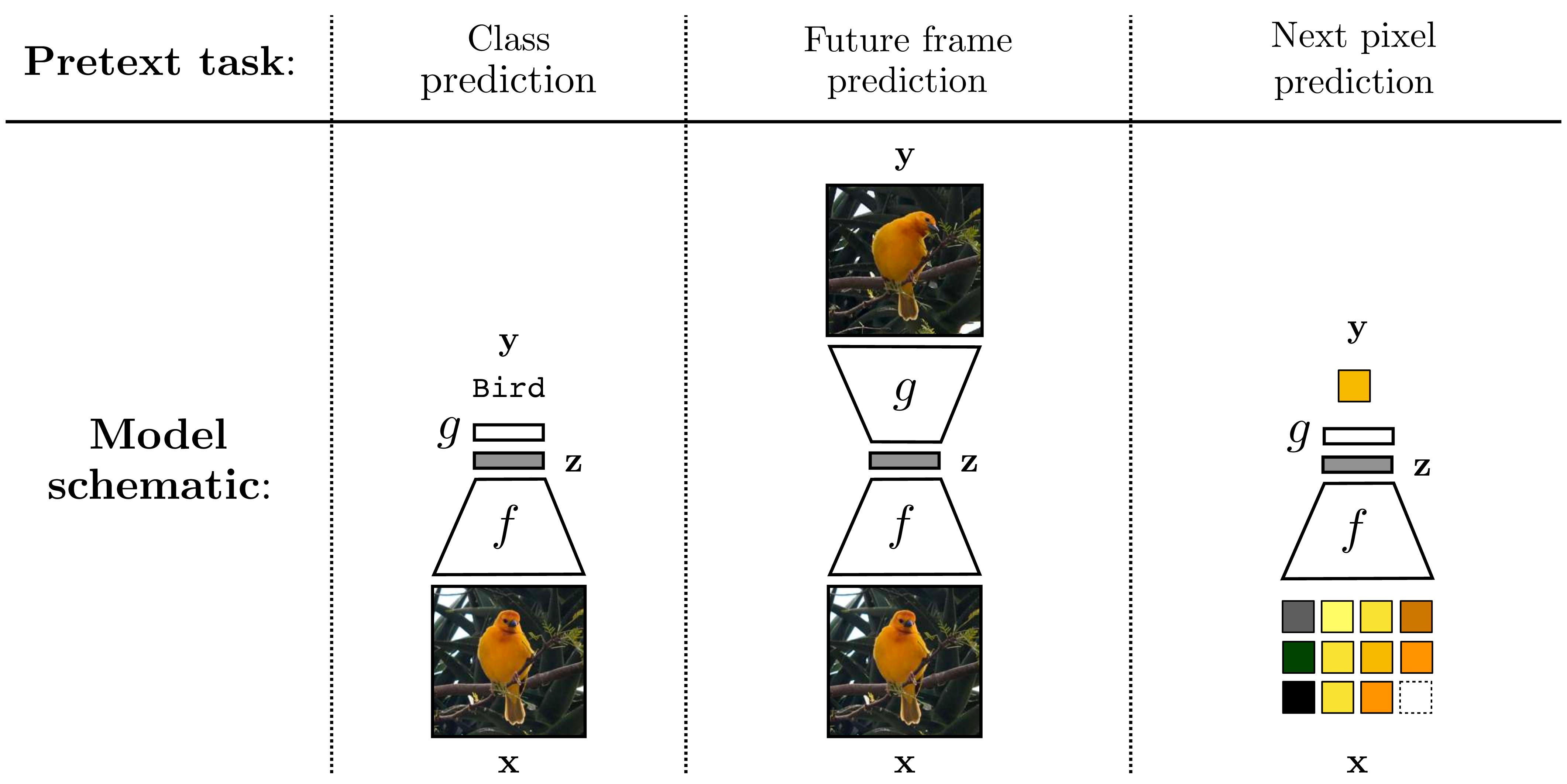
These tasks look a lot like supervised learning. We avoid calling it “supervised” because that connotes that we have examples of input-output pairs on the target task. Here that would be input data and exemplar output representations. But we don’t have that. The supervision in this setup is a pretext task that we hope induces good representations.
Let us now describe the predictive learning problem more formally. Let \(\mathbf{y}\) be the prediction target. Then predictive representation learning looks like this:

where \(D\) is some distance function, for example, \(L_2\). Just like with the autoencoder, \(f\) and \(g\) are usually neural nets but may be any family of functions; often \(g\) is just a single linear layer. Unlike with autoencoders, there is no standard setting for the relative dimensionalities of \(N\), \(M\), and \(K\); instead it depends on the prediction task. If the task is image classification, then \(N\) will be the (large) dimensionality of the input pixels, \(M\) will usually be much lower dimensional, and \(K\) will be the number of image classes (to output \(K\)-dimensional class probability vectors).
30.5.1 Object Detectors Emerge from Scene-Level Supervision
The real power of these pretexts tasks lies not in solving the tasks themselves but in acquiring useful image embeddings \(\mathbf{z}\) as a byproduct of solving the pretext task. The amazing thing that ends up happening is that \(z\)-space may have emergent structure that was not explicit in either the raw training data nor the pretext task. As a case study, consider the work of [15]. They trained a convolutional neural net (CNN) to perform scene classification, which asks whether the image shows a living room, bedroom, kitchen, and so on. The net did wonderfully at that task, but that wasn’t the point. The researchers instead peeled apart the net and looked at which input images were causing different neurons within the net to fire. What they found was that there were neurons, on hidden layers in the net, that fired selectively whenever the input image was of a specific object class. For example, one particular neuron would fire when the input was a staircase, and another neuron would fire predominantly for inputs that were rafts. The subsequent images (Figure 30.7) show four of the top images that activate these two particular neurons. These particular neurons are on convolutional layers, so really each is a filter response; the highlighted regions indicate where the feature map for that filter exceeds a threshold.

What this shows is that object detectors, that is, neurons that selectively fire when they see a particular object class, emerge in the hidden layers of a CNN trained only to perform scene classification. This makes sense in retrospect—how else would the net recognize scenes if not first by identifying their constituent objects?—but it was quite a shock for the community to see it for the first time. It gave some evidence that the way we humans parse and recognize scenes may match the way CNNs also internally parse and recognize scenes.
30.6 Self-Supervised Learning
Predictive learning is great when we have good prediction targets that induce good representations. What if we don’t have labeled targets provided to us? Instead we could try to cook up targets out of the raw data itself; for example, we could decide that the top right pixel’s color will be the “label” of the image. This idea is called self-supervision. It looks like this:

where \(V_1\) and \(V_2\) are two different functions of the full data tensor \(\mathbf{X}\). For example, \(V_1\) might be the left side of the image \(\mathbf{X}\) and \(V_2\) could be the right side, so the pretext task is to predict the right side of an image from its left side. In fact, several of the examples we gave previously for predictive learning are of the self-supervised variety: supervision for predicting a future frame, or a next pixel, can be cooked up just by splitting a video into past and future frames, or splitting an image into previous and next pixels in a raster-order sequence.
30.7 Imputation
Imputation is a special case of self-supervised learning, where the prediction targets are missing elements of the input data. For example, predicting missing pixels is an imputation problem, as is colorizing a black and white photo (i.e., predicting missing color channels). Figure 30.8 gives several examples of these imputation tasks.
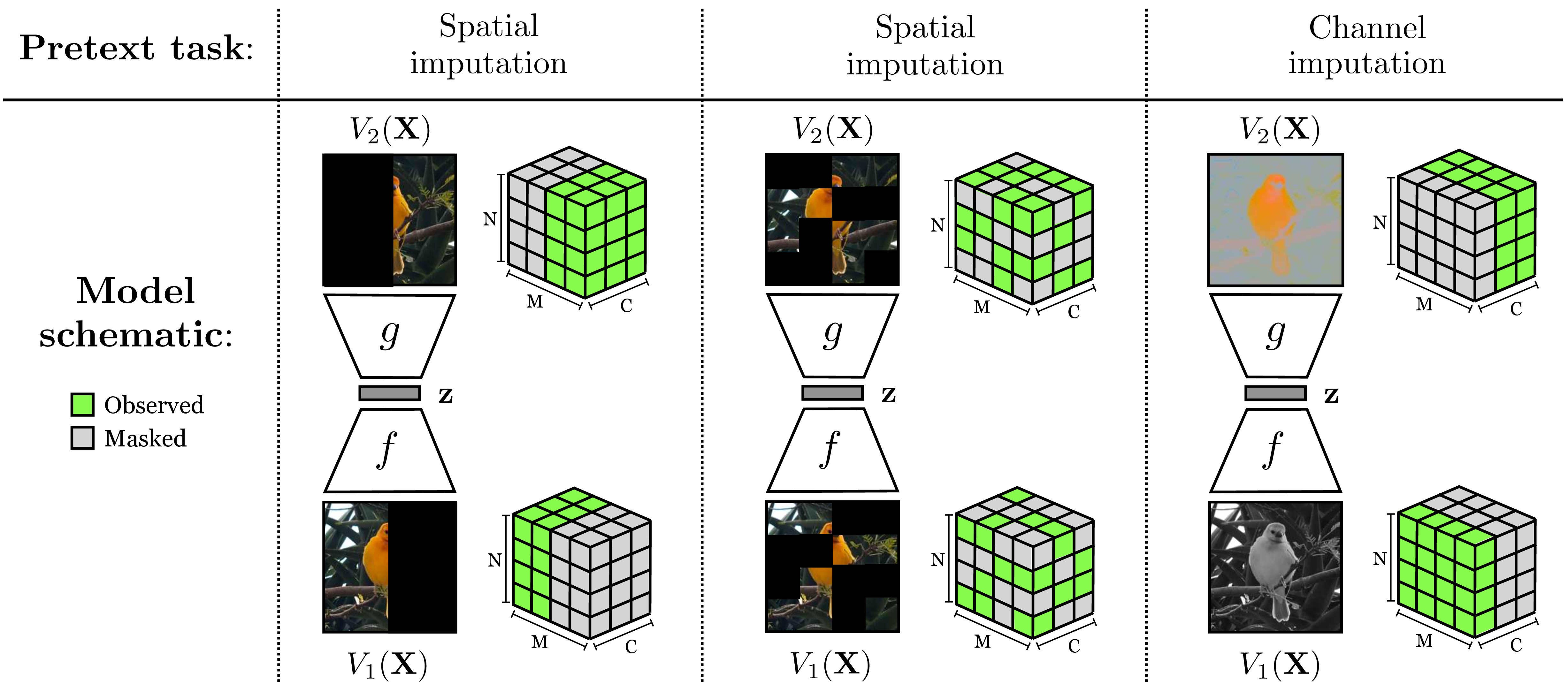
Imputation—whether over spatial masks or missing channels—can result in effective visual representations [16], [17], [18], [19], [20], [21]. Notice that predicting future frames and next pixels (our examples from Figure 30.6) are also imputation problems.
Above we described how object detectors emerge as a byproduct of training a net to perform scene classification. What do you think emerges as a byproduct of training a net to perform colorization?
It may surprise you to find that the answer is object detectors once again! This certainly surprised us when we saw the results in Figure 30.9, which are taken from [19].

In fact, object detectors emerge in CNNs for just about any reasonable pretext task: scene recognition, colorization, inpainting missing pixels, and more. What may be going on is that these things we call “objects” are not just a peculiarity of human perception but rather map onto some fundamentally useful structure out there in the world, and any visual system tasked with understanding our world would arrive at a similar representation, carving up the sensory array into objects and other kinds of perceptual groups. This idea will be explored in greater detail in the next chapter.
30.8 Abstract Pretext Tasks
Other varieties of self-supervised learning set up more abstract prediction problems, rather than just aiming to predict missing data. For example, we may try to predict if an image has been rotated 90 degrees [22], or we may aim to predict the relative position of two image patches given their appearance [23]. These pretext tasks can induce effective visual representations because solving them requires learning about semantic and geometric regularities in the world, such as that clouds tend to appear near the top of an image or that the trunk of a tree tends to appear below its branches.
30.9 Clustering
One way to compress a signal is dimensionality reduction, which we saw an example of previously with the autoencoder. Another way is to quantize the signal into discrete categories, an operation known also as clustering. Mathematically, clustering is a function \(f: \{\mathbf{x}^{(i)}\}_{i=1}^N \rightarrow \{1,\dots,k\}\), that is, a mapping from the members of a dataset \(\{\mathbf{x}^{(i)}\}_{i=1}^N\) to \(k\) integer classes (\(k\) can potentially be unbounded). Representing integers with one-hot codes, clustering is shown in Figure 30.10.
Another name for clustering, more common in the representation learning literature, is vector quantization.
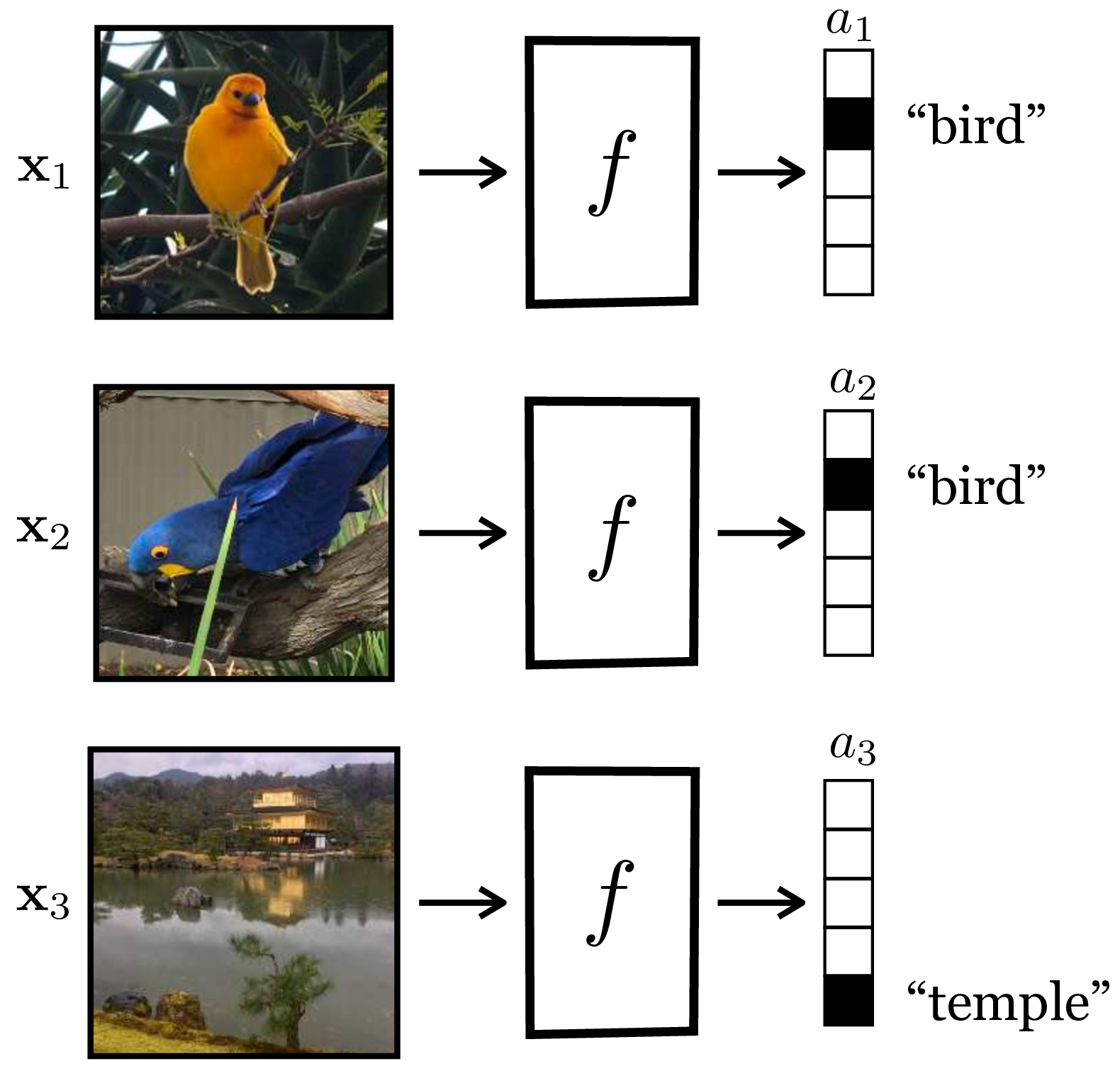
Clustering follows from the principle of compression: if we can well summarize a signal with just a discrete category label, then this summary can serve as a lighter weight and more abstracted substrate for further reasoning. You will already be familiar with clustering because we it in our natural language everyday. For example, consider the words “antelope,” “giraffe,” and “zebra.” Those words are discrete category labels (i.e., integers) that summarize huge conceptual sets (just think of all the individual lives and richly diverse personalities you are lumping together with the simple word “antelope”). Words, then, are clusters! They are mappings from data to integers, and clustering is the problem of making up new words for things.
Words, of course, are given additional structure when used in a language (grammar, connotations, etc.) beyond just being a set of clusters. The same kind of structure can be added on top of visual clusters.
Many clustering algorithms not only partition the data but also compute a representation of the data within each cluster; this representation is sometimes called a code vector. The most common code vector is the cluster center, \(\mu\), that is, the mean value of all datapoints assigned to the cluster. Clusters can also be represented by other statistics of the data assigned to them, such as the variance of this data or some arbitrary embedding vector, but this is less common. The set of cluster centers, \(\{\mu_i\}_{i=1}^k\), is a representation of a whole dataset. They summarize the main modes of behavior in the dataset.
30.9.1 \(K\)-Means
There are many types of clustering algorithm but we will illustrate the basic principles with just one example, perhaps the most popular clustering algorithm of them all, \(\mathbf{k}\)-means. \(K\)-means is a clustering algorithm that partitions the data into \(k\) clusters. Each datapoint \(\mathbf{x}^{(i)}\) is assigned to a cluster indexed by an integer \(a_i \in \{1, \ldots, k\}\). Each cluster is given a code vector \(\mathbf{z} \in \mathbb{R}^M\). The \(k\)-means objective is to minimize the distance between each datapoint and the code vector of the cluster it is assigned to:
\[ \begin{aligned} J_{\texttt{kmeans}} &= \sum_{i=1}^N \left\lVert\mathbf{z}_{a_i} - \mathbf{x}^{(i)}\right\rVert^2_2 \quad\quad \triangleleft \quad\text{$k$-means objective} \end{aligned} \] This way, the code vector assigned to each datapoint will be a good approximation to the value of that datapoint, and we will have a faithful, but compressed, representation of the dataset.
There are two free parameter sets to optimize over: the code vectors and the cluster assignments. The cluster assignments can be represented with a clustering function \(f: \{\mathbf{x}^{(i)}\}_{i=1}^N \rightarrow \{1,\dots,k\}\): \[\begin{aligned} a_i = f(\mathbf{x}^{(i)}) \end{aligned}\] We will represent the code vectors for each cluster with a function \(g: \{1,\ldots,k\} \rightarrow \mathbb{R}^M\), where the data dimensionality is \(M\): \[\begin{aligned} \mathbf{z}_{a_i} = g(a_i) \end{aligned}\] Both \(f\) and \(g\) can be implemented as lookup tables, since for both the input is a countable set. The \(k\)-means algorithm amounts to just filling in these two lookup tables.
Now we are ready to present the full \(k\)-means algorithm, viewed as a learning algorithm. As you will see below, the learning diagram looks almost the same as for an autoencoder! The key differences are (1) the bottleneck is discrete integers rather than continuous vectors, and (2) the optimizer is slightly different (we will delve into it subsequently).

To recap, there are two functions we are optimizing over: the encoder \(f\) and the decoder \(g\). The \(f\) is parameterized by a set of integers \(\{a_i\}_{i=1}^N\), \(a_i \in \{1,\ldots,k\}\), which specify the cluster assignment for each datapoint. The decoder \(g\) is parameterized by a set of \(k\) code vectors \(\{\mathbf{z}_j\}_{j=1}^k\), \(\mathbf{z}_j \in \mathbb{R}^{M}\), one for each cluster, so we have \(F(\mathbf{x}^{(i)}) = g(f(\mathbf{x}^{(i)})) = g(a_i) = \mathbf{z}_{a_i}\). The \(g\) is differentiable with respect to its parameters but \(f\) is not, because the parameters of \(f\) are discrete variables. This means that gradient descent will not be a suitable optimization algorithm (the gradient \(\frac{\partial f}{\partial a_i}\) is undefined). Instead, we will use the optimization strategy described next.
30.9.1.1 Optimizing \(k\)-means
\(K\)-means uses an optimization algorithm called block coordinate descent. This algorithm splits up the optimization parameters into multiple subsets (blocks). Then it alternates between fully minimizing the objective with respect to each block of parameters. In \(k\)-means there are two parameter blocks: \(\{a_i\}_{i=1}^N\) and \(\{\mathbf{z}_j\}_{j=1}^k\). So, we need to derive update rules that find the minimizer of the \(k\)-means objective with respect to each block. It turns out there are simple solutions for both:
\[\begin{aligned} a_i &\leftarrow \mathop{\mathrm{arg\,min}}_{j \in \{1,\ldots,k\}} \left\lVert\mathbf{z}_j - \mathbf{x}^{(i)}\right\rVert_2^2 \quad\quad \triangleleft\quad\text{Assign datapoint to nearest cluster} \end{aligned} \tag{30.2}\]
\[\begin{aligned} \mathbf{z}_j &\leftarrow \frac{1}{N}\sum_{i=1}^N \mathbb{1}(a_i = j)\mathbf{x}^{(i)} \quad\quad \triangleleft\quad\text{Set code vector to cluster center} \end{aligned} \tag{30.3}\]
These steps are repeated until a fixed point is reached, which occurs when all the datapoints that are assigned to each cluster are closest to that cluster’s code vector.
Why are these the correct updates? Equation 30.2 is straightforward: it’s just a brute force enumeration of all \(k\) possible assignments, from which we select the one that minimizes the \(k\)-means objective for that datapoint, given the current set of code vectors \(\{\mathbf{z}_j\}_{j=1}^k\).
Equation 30.3 is slightly trickier. It finds the optimal codes \(\{\mathbf{z}_j\}_{j=1}^k\) given the current set of assignments \(\{a_i\}_{i=1}^N\). To see why Equation 30.3 is optimal, first rewrite the \(k\)-means objective as follows:
\[\begin{aligned} J_{\texttt{kmeans}} &= \sum_{i=1}^N \left\lVert\mathbf{z}_{a_i} - \mathbf{x}^{(i)}\right\rVert^2_2\\ &= \sum_{j=1}^k \sum_{i=1}^N \mathbb{1}(a_i = j) \left\lVert\mathbf{z}_j - \mathbf{x}^{(i)}\right\rVert^2_2 \end{aligned}\]
Looking at one code vector (the \(j\)-th) in isolation, we are seeking:
\[\begin{aligned} \mathop{\mathrm{arg\,min}}_{\mathbf{z}_j} \sum_{i^{\prime} \text{ s.t. } a_{i^\prime}=j} \left\lVert\mathbf{z}_j - \mathbf{x}^{(i^{\prime})}\right\rVert^2_2 \end{aligned}\]
where \(i^{\prime}\) enumerates all the datapoints for which \(a_{i^\prime} = j\). Recall that the point that minimizes the sum of squared distances from a dataset is the mean of the dataset. This yields our update in Equation 30.3: just set each code to be the mean of all datapoints assigned to that code’s cluster.
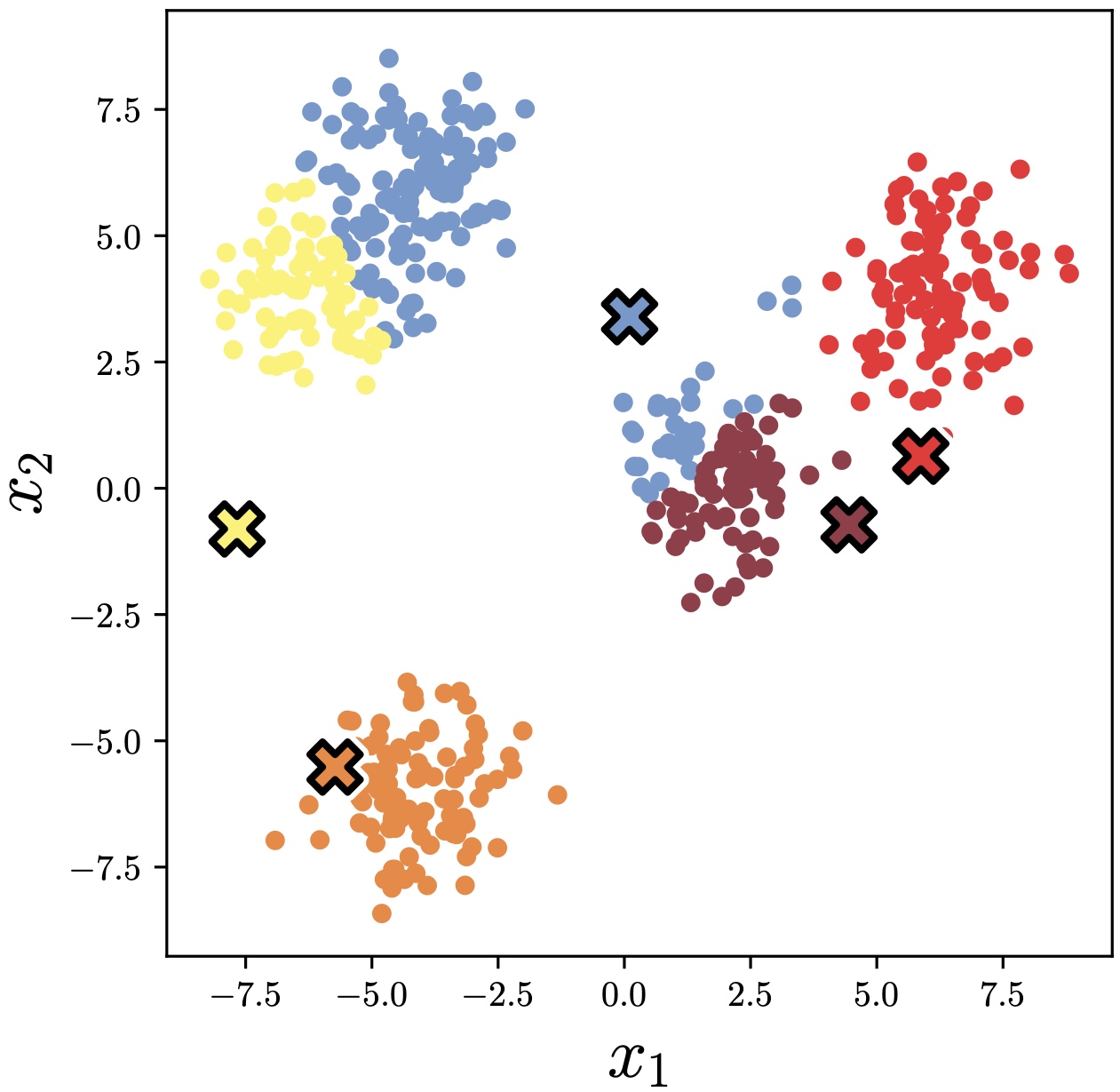
Now we can see where the name \(k\)-means comes from: the optimal code vectors are the cluster means. The algorithm is very simple: compute the cluster means given current data assignments; reassign each datapoint to nearest cluster mean; recompute the means; and so on until convergence. An example of applying this algorithm to a simple dataset of two-dimensional (2D) points is given in Figure 30.11.


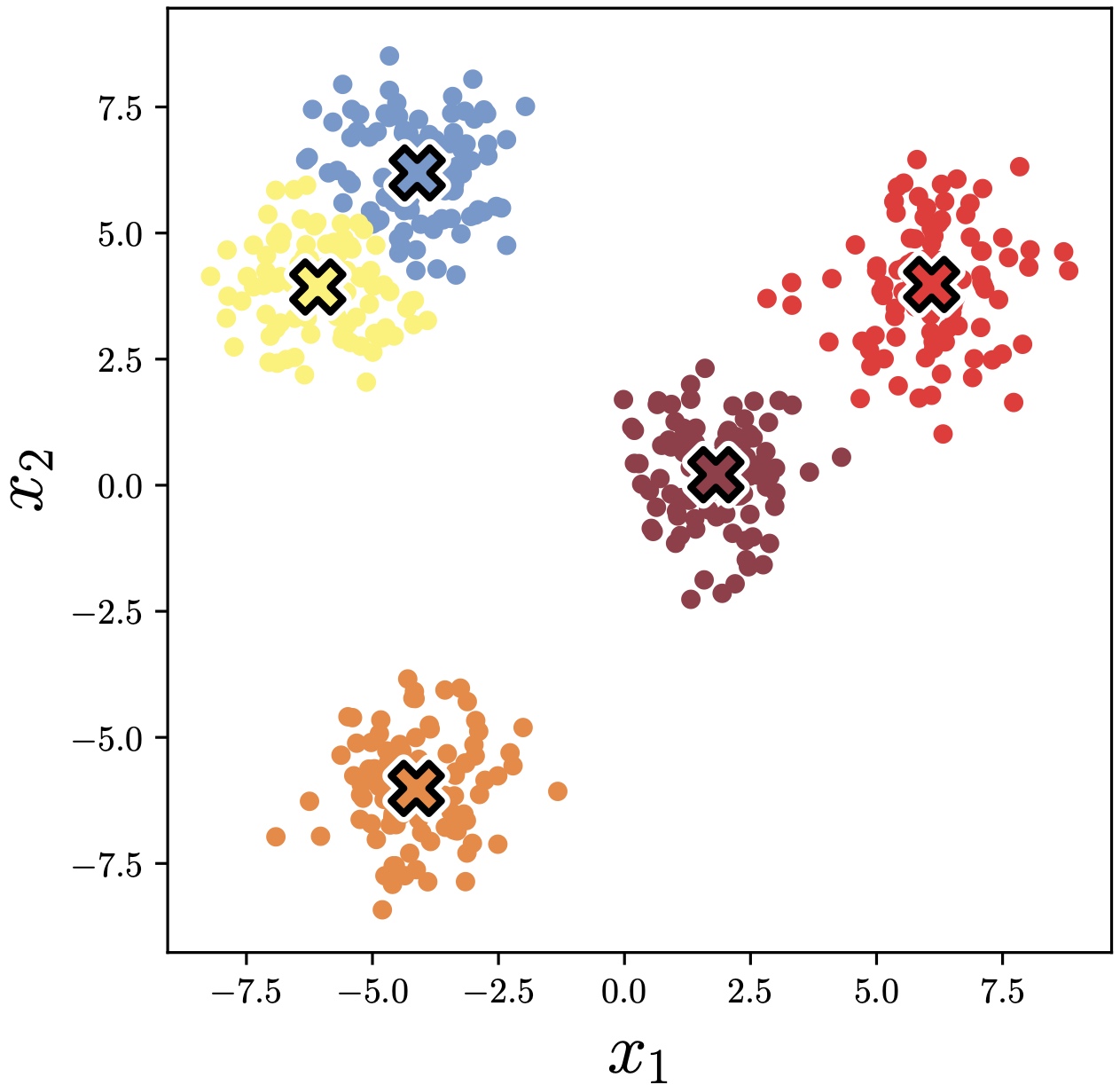
30.9.2 \(K\)-Means from Multiple Perspectives
This section has presented \(k\)-means as a representation learning algorithm. In other texts you may encounter other views on \(k\)-means, for example, as a way of interpreting your data or as a simple generative model. These views are all complementary and all simultaneously true. Here we showed that \(k\)-means is like an autoencoder with a discrete bottleneck. In the next chapters we will encounter generative models, including one called a Gaussian mixture model (GMM). \(K\)-means can also be viewed as a vanilla form of a GMM. Later we will show that another kind of autoencoder, called a variational autoencoder (VAE), is a continuous version of a GMM. So we have a rich tapestry of relationships: autoencoders and VAEs are continous versions of \(k\)-means and GMMs, respectively. GMMs and VAEs are formal probabilistic models that, respectively, extend \(k\)-means and autoencoders (which do not come with probabilistic semantics). This is just one set of connections that can be made. In this book, be on the lookout for more connections like this. It can be confusing at first to see multiple different perspectives on the same method: Which one is correct? But rarely is there a single correct perspective. It is useful to identify the delta between each new model you encounter and all the models you already know. Usually there is a small delta with respect to many things you already know, and rarely is there no meaningful connection between any two arbitrary models. As an exercise, try picking a random concept on a random page in this book (or, for a challenge, any book on your bookshelf). What is the delta between that concept and \(k\)-means, or between that concept and a different concept on any other random page? In our experience, it will often be surprisingly small (but sometimes it takes a lot of effort to see the connection).
30.9.3 Clustering in Vision
In vision, the problem of clustering is related to the idea of perceptual grouping, which we cover in detail in Chapter 31. We humans see the world as organized into different levels of perceptual structure: contours and surfaces, objects and events. These structures are groupings, or clusters, of related visual elements: a contour is a group of points that form a line, an object is a group of parts that form a cohesive, nameable whole, and so on. Algorithms like \(k\)-means, in a suitable feature space, can discover them.
30.10 Contrastive Learning
Dimensionality reduction and clustering algorithms learn compressed representations by creating an information bottleneck, that is, by constraining the number of bits available in the representation. An alternative compression strategy is to supervise what information should be thrown away. Contrastive learning is one such approach where a representation is supervised to be invariant to certain viewing transformations, resulting in a compressed representation that only captures the properties that are common between the different data views. Two different data views could correspond to two different cameras looking at the same scene or two different imaging modalities, such as color and depth, and we will see more examples subsequently.
Contrastive learning is actually more closely related to clustering than it may at first seem. Contrastive learning maps similar datapoints to similar embeddings. Clustering is just the extreme version of this where there are only \(k\) distinct embeddings and similar datapoints get mapped to the exact same embedding.
Learning invariant representations is classic goal of computer vision. Recall that this was one of the reasons we used convolutional image filters: convolution is equivariant with camera translation, and invariance can then be achieved simply by pooling over filter responses. CNNs, through their convolutional architecture, bake translation invariance into the hypothesis space. In this section we will see how to incentivize invariances instead through the objective function.
The idea is to simply penalize deviations from the invariance we want. Suppose \(T\) is a transformation we wish our representation to be invariant to. Then we may use a loss of the form \(\left\lVert f(T(\mathbf{x}))-f(\mathbf{x})\right\rVert_2^2\) to learn an encoder \(f\) that is invariant to \(T\). We call such a loss an alignment loss [24].
That seems easy enough, but you may have noticed a flaw: What if \(f\) just learns to output the zero vector all the time? Trivial alignment can be achieved when there is representational collapse, and all datapoints get mapped to the same arbitrary vector.
Contrastive learning fixes this issue by coupling an alignment loss with a second loss that pushes apart embeddings of datapoints for which we do not want an invariant representation. The supervision for contrastive learning comes in the form of positive pairs and negative pairs. Positive pairs are two datapoints we wish to align in \(z\)-space; if we wish for invariance to \(T\) then a positive pair should be constructed as \(\{\mathbf{x}, \mathbf{x}^{+}\}\) with \(\mathbf{x}^{+} = T(\mathbf{x})\). Negative pairs, \(\{\mathbf{x},\mathbf{x}^-\}\), are two datapoints that should be represented differently in \(z\)-space. Commonly, negative pairs are randomly constructed by sampling two datapoints independently and identically from the same data distribution, that is, \(\mathbf{x} \sim p_{\texttt{data}}(\mathbf{x})\) and \(\mathbf{x}^{-} \sim p_{\texttt{data}}(\mathbf{x})\). Given such data pairings, the objective is to pull together the positive pairs and push apart the negative pairs, as illustrated in Figure 30.12.
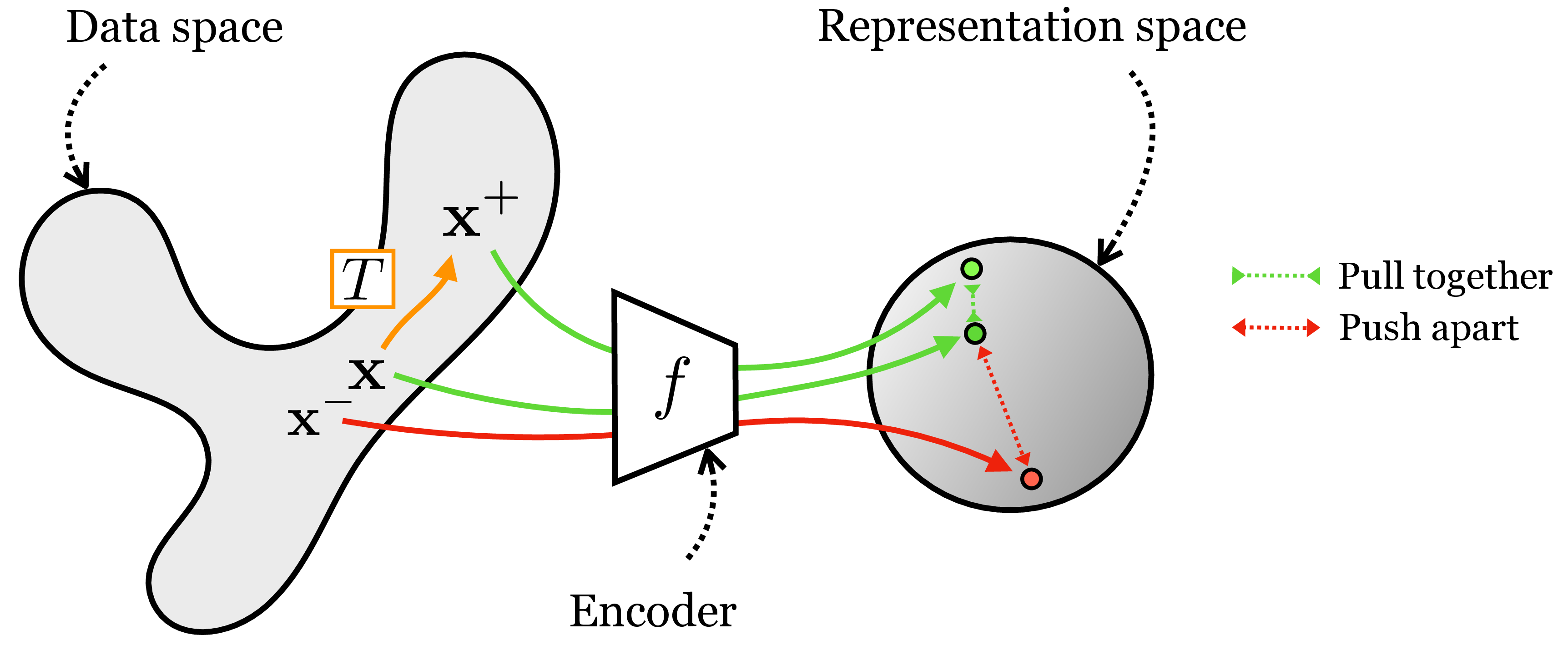
This kind of contrastive learning results in an embedding that is invariant to a transformation \(T\). Extending this to achieve invariance to a set of transformations \(\{T_1, \ldots, T_n\}\) is straightforward: just apply the same loss for each of \(T_1, \ldots, T_n\).
A second kind of contrastive learning is based on co-occurrence, where the goal is to learn a common representation of all co-occurring signals. This form of contrastive learning is useful for learning, for example, an audiovisual representation where the embedding of an image matches the embedding of the sound for that same scene. Or, returning to our colorization example, we can learn an image representation where the embedding of the grayscale channels matches the embedding of the color channels. In both these cases we are learning to align co-occurring sensory signals. This kind of contrastive learning is schematized in Figure 30.13.
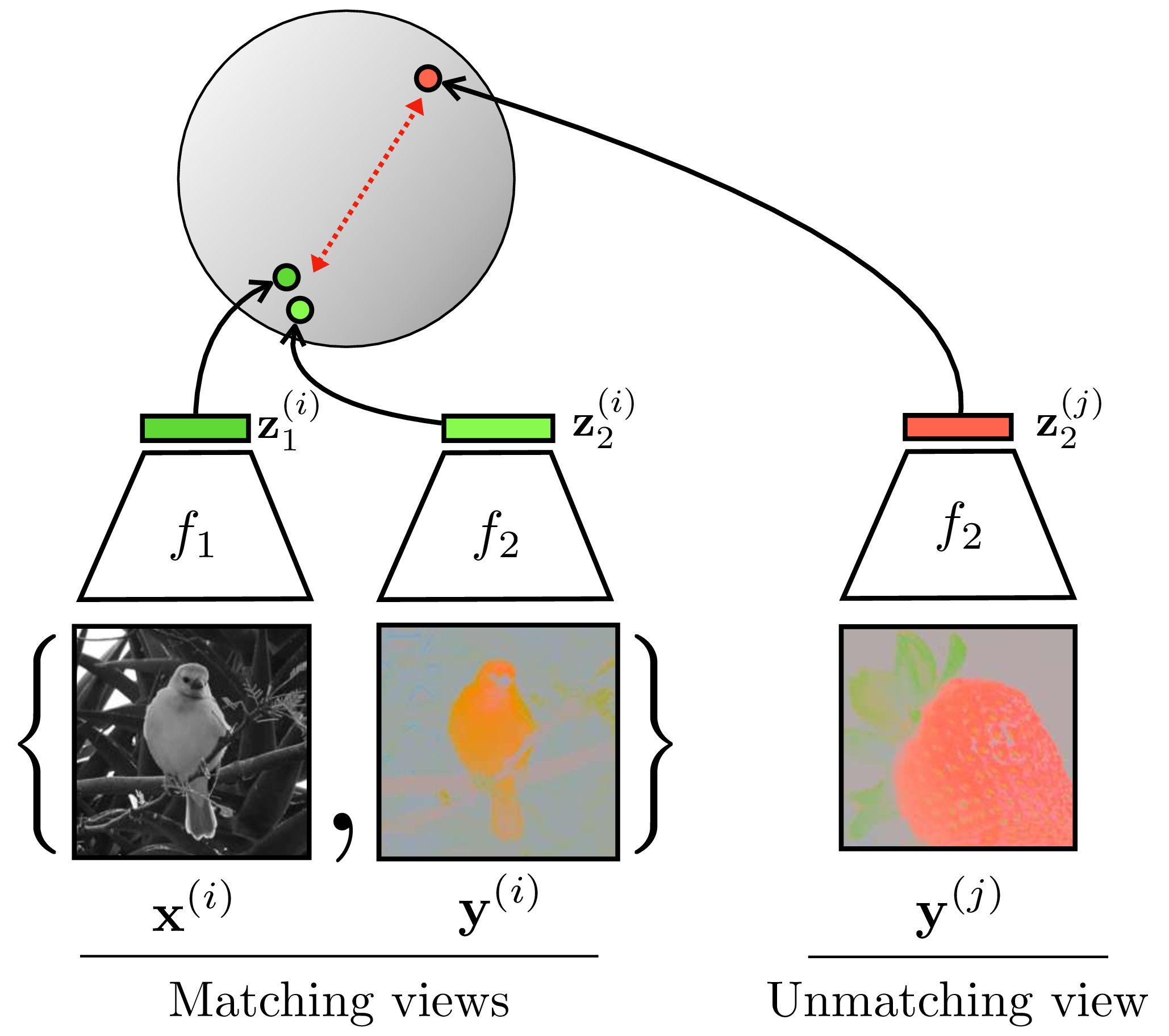
In Figure 30.13, we refer to the two co-occurring signals—color and grayscale—as two different views of the total data tensor \(\mathbf{X}\), just like we did in the previous sections: \(\mathbf{x} = V_1(\mathbf{X})\), \(\mathbf{y} = V_1(\mathbf{X})\). You can think of these views either as resulting from sensory co-occurrences or as two transformations of \(\mathbf{X}\), where the transformation in the color example is channel dropping. Thus, the two kinds of contrastive learning we have presented are really one and the same: any two signals can be considered transformations of a combined total signal, and any signal and its transformation can be considered two co-occurring ways of measuring the underlying world.
Nonetheless, it is often easiest to conceptualize these two approaches separately, and next we give learning diagrams for each:
![]()

In these diagrams, \(D\) is a distance function. Above we give just one simple form for the contrastive objective; many variations have been proposed. Three of the most popular are (1) Hadsell et al.’s “constrastive loss” [25] (an older definition of the term, now overloaded with our more general notion of a contrastive loss being the broader family of any loss that pulls together positive samples and pushes apart negative samples), (2) the triplet loss [26], and (3) the InfoNCE loss [27]. Hadsell et al.’s contrastive loss and the triplet loss add the concept of a margin to the vanilla formulation: they only push/pull when the distance is less than a specified amount \(m\) (called the margin), otherwise points are considered far enough apart (or close enough together). The InfoNCE loss is a variation that treats establishing a contrast as a classification problem: it tries to move points apart until you can classify the positive sample, for a given anchor, separately from all the negatives. The general formulation of these losses takes as input an anchor \(\mathbf{x}\), a positive example \(\mathbf{x}^+\), and one or more negative examples \(\mathbf{x}^-\). The positive and negative may be defined based on transformations, coocurrences, or something else. The full learning objective is to sum over many samples of anchors, positives, and negatives, producing a sampled set evaluated according to the losses as follows: \[\begin{aligned} \mathcal{L}(\mathbf{x}, \mathbf{x}^+, \mathbf{x}^-) &= \max(D(f(\mathbf{x}), f(\mathbf{x}^+)-m_{\texttt{pos}},0) - \nonumber \\ &\quad \max(m_{\texttt{neg}} - D(f(\mathbf{x}), f(\mathbf{x}^-),0) \quad \triangleleft \quad \text{Hadsell et al. ``contrastive''}\\ \mathcal{L}(\mathbf{x}, \mathbf{x}^+, \mathbf{x}^-) &= \max(D(f(\mathbf{x}), f(\mathbf{x}^+)) - D(f(\mathbf{x}), f(\mathbf{x}^-)) + m, 0) \quad\quad \triangleleft \quad \text{triplet}\\ \mathcal{L}(\mathbf{x}, \mathbf{x}^+, \{\mathbf{x}_i^-\}_{i=1}^N) &= -\log \frac{e^{f(\mathbf{x})^\mathsf{T}f(\mathbf{x}^+)/\tau}}{e^{f(\mathbf{x})^\mathsf{T}f(\mathbf{x}^+)/\tau} + \sum_i e^{f(\mathbf{x})^\mathsf{T}f(\mathbf{x}_i^-)/\tau}} \quad\quad\quad\quad\quad\quad\triangleleft \quad \text{InfoNCE} \end{aligned} \tag{30.4}\] Notice that the InfoNCE loss is a log softmax over a vector of scores \(f_1(\mathbf{x})^\mathsf{T}f_2(c)/\tau\) with \(c \in \{\mathbf{x}^+, \mathbf{x}_1^-, \ldots, \mathbf{x}_N^-\}\); you can therefore think of this loss as corresponding to a classification problem where the ground truth class is \(\mathbf{x}^+\) and the other possible classes are \(\{\mathbf{x}_1^-, \ldots, \mathbf{x}_N^-\}\) (refer to Chapter 9 to revisit softmax classification).
30.10.1 Alignment and Uniformity
Wang and Isola [24] showed that the contrastive loss (specifically the InfoNCE form) encourages two simple properties of the embeddings: alignment and uniformity. We have already seen that alignment is the property that two views in a positive pair will map to the same point in embedding point, that is, the mapping is invariant to the difference between the views. Uniformity comes from the negative term, which encourages embeddings to spread out and tend toward an evenly spread, uniform distribution. Importantly, for this to work out mathematically, the embeddings must be normalized, that is, each embedding vector must be a unit vector. Otherwise, the negative term can push embeddings toward being infinitely far apart from each other. Fortunately, it is standard practice in contrastive learning (and many other forms of representation learning) to apply \(L_2\) normalization to the embeddings. The result is that the embeddings will tend toward a uniform distribution over the surface of the \(M\)-dimensional hypersphere, where \(M\) is the dimensionality of the embeddings. See theorem 1 in [24] for a formal statement of this fact.
A result of this analysis is we may explicit decompose contrastive learning into one loss for alignment and another for uniformity, with the following forms: \[\begin{aligned} \mathcal{L}_{\texttt{align}}(f;\alpha) &= \mathbb{E}_{(\mathbf{x},\mathbf{x}^+) \sim p_{\texttt{pos}}} [\left\lVert f(\mathbf{x}) - f(\mathbf{x}^+)\right\rVert_2^{\alpha}]\\ \mathcal{L}_{\texttt{unif}}(f;t) &= \log \mathbb{E}_{\mathbf{x} \sim p_{\texttt{data}}, \, \mathbf{x}^- \sim p_{\texttt{data}}} [e^{-t\left\lVert f(\mathbf{x}) - f(\mathbf{x}^-)\right\rVert_2^2}]\\ \mathcal{L}(f;\alpha,t,\lambda) &= \mathcal{L}_{\texttt{align}}(f;\alpha) + \lambda \mathcal{L}_{\texttt{unif}} \end{aligned}\] where \(p_{\texttt{pos}}\) is the distribution of positive pairs and \(\alpha\), \(t\), and \(\lambda\) are hyperparameters of the losses.
30.10.2 Experiment: Designing Embeddings with Contrastive Learning
Using the alignment and uniformity objective defined previously, we will now illustrate how one can design embeddings with desired invariances. We will use the shape dataset described in Section 30.4, and will use the same encoder architecture and optimizer as from that section (a CNN with six layers, Adam optimizer, 20,000 iterations of stochastic gradient descent, batch size of 128). In contrast to the autoencoder experiment, however, we will set the dimensionality of the embedding to \(M=2\), so that we can visualize it in a 2D plot.
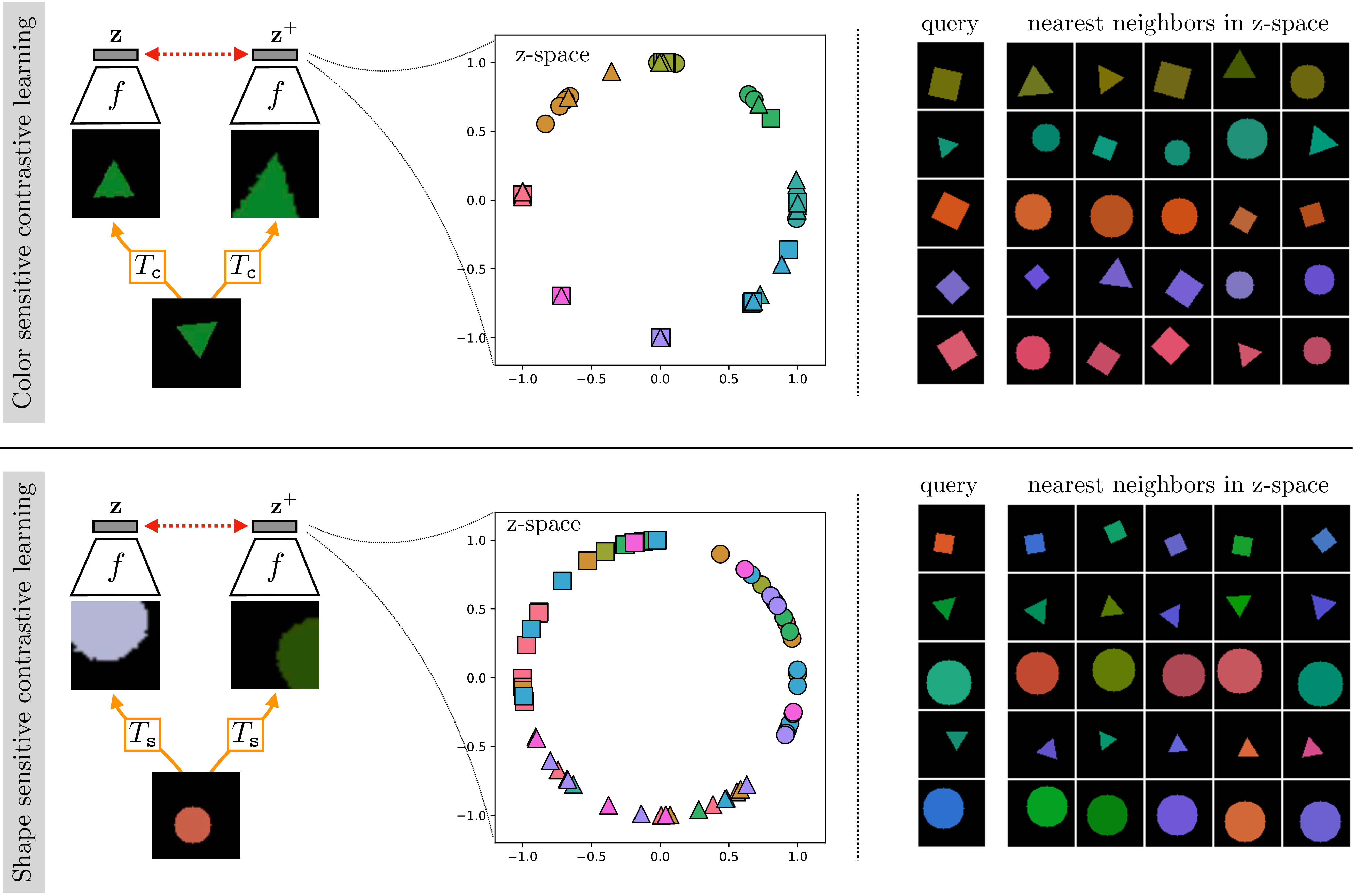
Suppose we wish to obtain an embedding that is sensitive to color and invariant to shape. Then we should choose a view transformation \(T_{\texttt{c}}\) that preserves color while changing shape. A simple choice that turns out to work is for \(T_{\texttt{c}}(\mathbf{x})\) to simply output a crop from the image \(\mathbf{x}\) (this transformation does not really change the object’s shape but still ends up resulting in shape-invariant embeddings because color is a much more obvious cue for the CNN to pick up on and use for solving the contrastive problem). The result of contrastive learning, using \(L_{\texttt{align}} + L_{\texttt{unif}}\) on data generated from \(T_{\texttt{c}}\) is shown on the top row of Figure 30.14. Notice that the trained \(f\) maps colors to be clustered into the color classes of this toy data, and that these classes become spread out more or less uniformly across the surface of a circle in embedding space (a one-dimensional hypersphere, because the embeddings are 2D and normalized).
We can repeat the same experiment but with a view transformation \(T_{\texttt{s}}\) designed to be invariant to color. To do so we simply use the same transformation as for \(T_{\texttt{c}}\) (i.e., cropping) plus add a random shift in hue, brightness, and saturation. Training on views generated from \(T_{\texttt{s}}\) results in the embeddings on the bottom row of Figure 30.14. Now the embeddings become invariant to color but cluster shapes and spread out the three shape types to be roughly uniformly spaced around the hypersphere.
30.11 Concluding Remarks
This chapter, like much of this book, is about representations. Different representations make different problems easy, or hard. It is important to remember that every representation involves a set of tradeoffs: a good representation for one task may be a bad representation for another task. One of the current goals of computer vision research is to find general-purpose representations, and what this means is not that the representation will be good for all tasks but that it will be good for a wide variety of the tasks that humans care about, which is a very tiny subset of all possible tasks.