21 Downsampling and Upsampling Images
21.1 Introduction
Changing the resolution of an image, or a feature map, is an operation you are likely to do many times, hence it will be worth expending some time understanding all its subtleties. Whether it is for resizing a picture, or to change the dimensionality of a representation, changing the sample-rate of a signal is a common operation. Resizing an image might seem like a trivial operation and often it is carelessly applied, producing results that are far from optimal. As discussed in the previous chapter, aliasing reduces the quality of the image. Aliasing is a visual phenomenon whereby the appearance of an image can change drastically after subsampling. In the previous chapter we discussed the case when the input is a continuous signal and the output is its discretized image.
21.2 Example: Aliasing-Based Adversarial Attack
Aliasing in a system has consequences beyond the aesthetics of the final output. To illustrate the importance of aliasing when building vision systems in practice, let’s consider the following simple system [1]:
\[\begin{aligned} u[n,m] &= \ell_{\texttt{in}}\left[n,m\right] \circ \left[-1, 1 \right] & \quad\quad \triangleleft \quad \texttt{conv}\\ h[n,m] &= u[2n,2m] & \quad\quad \triangleleft \quad \texttt{decimation}\\ \ell_{\texttt{out}}[n,m] &= \max (0,h[n,m]) & \quad\quad \triangleleft \quad \texttt{relu} \end{aligned}\]
This system has three steps: the first step is a vertical edge filter (convolution of the input, \(\ell_{\texttt{in}}\), with a horizontal kernel, \([1, -1]\)). The next step is to reduce the resolution of the filter output by taking one pixel every two along each dimension (this operation is called decimation). Decimation takes an input, \(u\), with size \(N\times M\), and outputs, \(h\), with half the size \(N/2 \times M/2\). Finally, the third step is a relu nonlinearity.
A convolution followed by decimation is also called strided convolution in the neural networks literature.
As we will discuss in this chapter, the decimation step introduces aliasing. As illustrated in , an attacker could use aliasing in a system to infiltrate a signal hidden in the high-spatial frequencies that could change the output in unexpected ways. In this toy example, the construction of the attack is as follows. Let \(\ell_{\texttt{in}}\left[n,m\right]\) be the original image (e.g., a picture of a bird), and \(\ell_{\texttt{hidden}}\left[n,m\right]\) be the hidden image (e.g., a picture of a stop sign). The attack \(z \left[n,m\right]\) is given by \[\label{equation:aliasing-attack} z \left[n,m\right] = (-1)^n(-1)^m \ell_{\texttt{hidden}}\left[n,m\right]\]
The attacked input image is \(\ell_{\texttt{in}}\left[n,m\right]+ \epsilon z \left[n,m\right]\), where \(\epsilon\) is the chosen adversarial strength. In this example we used \(\epsilon=0.05\). As we can see in , the attacked input image is indistinguishable from the original input, \(\ell_{\texttt{in}}\left[n,m\right]\), and yet their outputs are completely different. The culprit for this bizarre effect is the strided convolution that samples the output for one pixel every two. An attacker with knowledge about it is able to construct a perturbation focused on manipulating the surviving samples (pixels at even rows and columns); the output at the discarded samples (pixels at an odd row or column) do not matter, or may even serve as extra degrees of freedom that can be used to make the attack less noticeable.
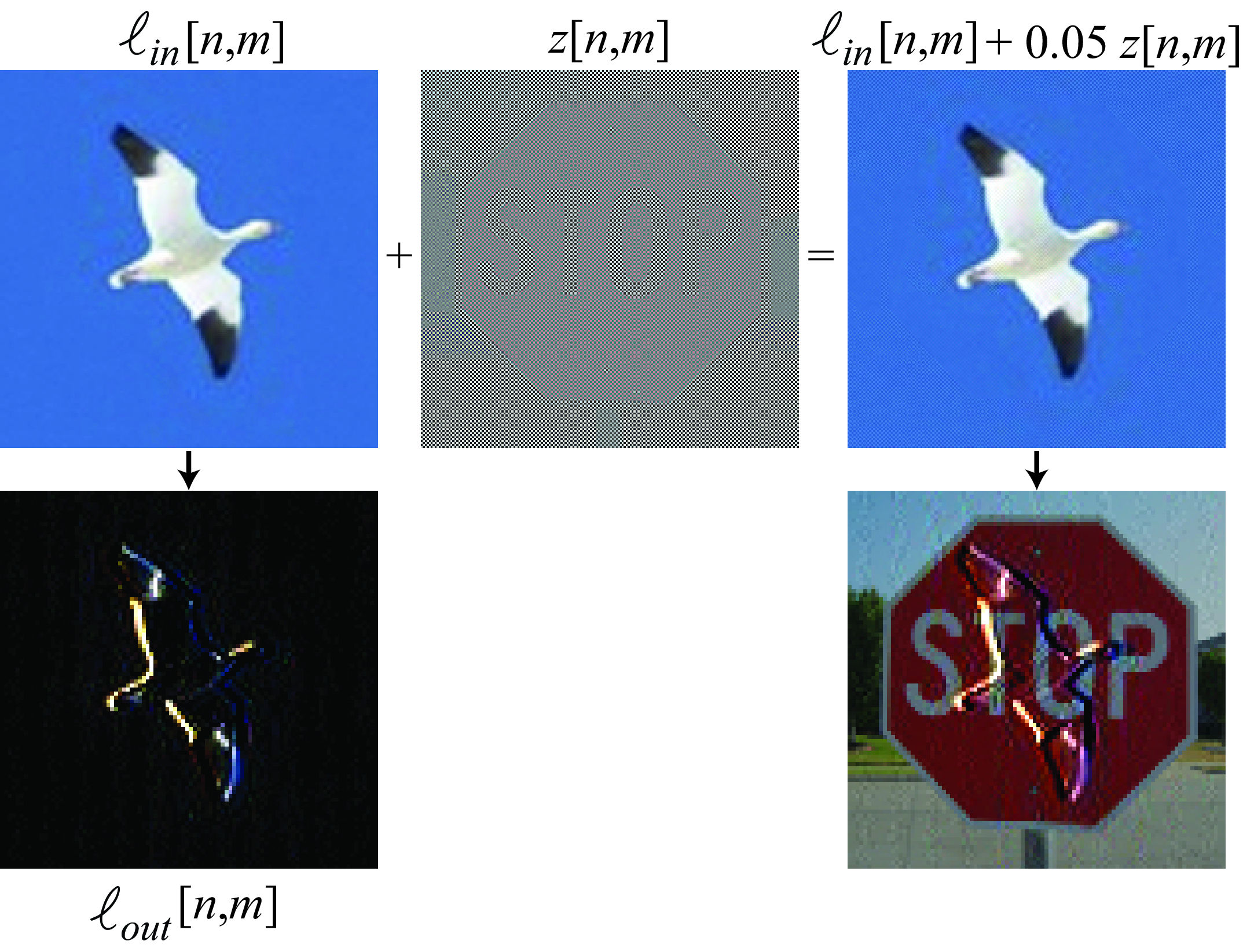
In this chapter we will study aliasing when manipulating image resolution and how to reduce it.
21.3 Downsampling
Downsampling is an operation that consists of reducing the resolution of an image. When we reduce the resolution, some information will be lost; specifically fine image details will be lost. But carelessly removing pixels will produce a greater loss of information than necessary. The goal of this chapter will be to study how downsampling has to be done to minimize the amount of information lost.
21.3.1 Decimation
Image decimation consists of changing the resolution of an image by dropping samples. Decimation of an image of size \(N \times M\) by a factor of \(k\), where \(N\) and \(M\) are divisible by \(k\), results in a lower resolution image of size \(N/k \times M/k\): \[\ell_{\downarrow k} \left[n,m\right] = \ell\left[kn, km\right]\] It is common to use the notations \(\ell_{\downarrow k} \left[n,m\right] = \ell\left[n,m\right] \downarrow k = \ell\left[kn,km\right]\) to denote the decimation operator by a factor \(k\). Decimation could be different across each dimension, but for the analysis here we will assume that both dimensions are treated equally, as it is usually done.
Decimation is often drawn using the following block:
Decimation is a linear operation therefore we can write it as a matrix. In the one-dimensional (1D) case, for a signal of length 8, subsampling by a factor of 2 can be described by the following linear operator: \[\mathbf{D}_2 = \left[ \begin{array}{cccccccc} 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0\\ 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0\\ 0 & 0 & 0 & 0 & 1 & 0 & 0 & 0\\ 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 \end{array} \right]\]
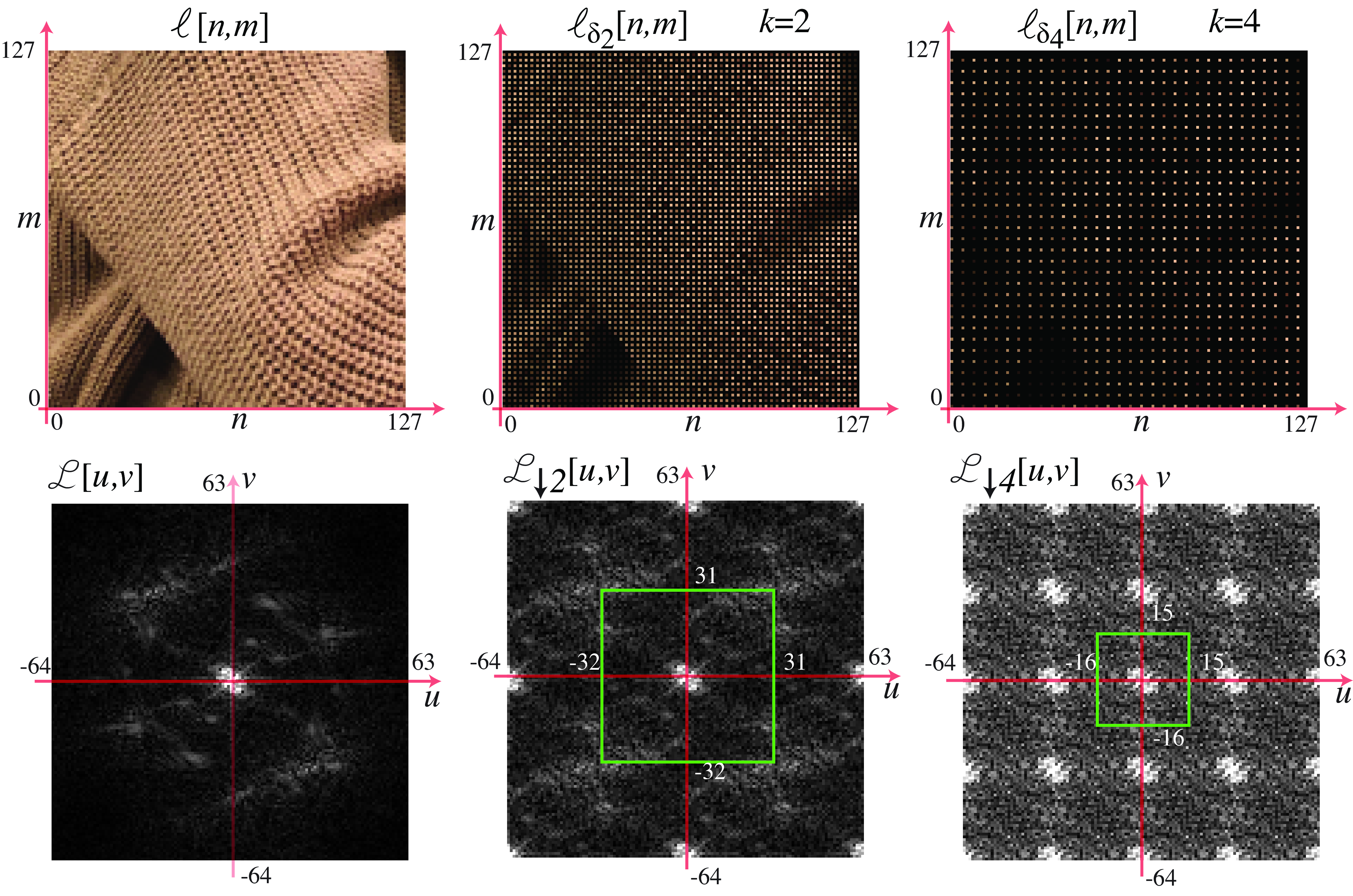
Figure 21.2 shows an example of a picture and two decimated images with factors \(k=2\) and \(k=4\). For visualization purposes, the images are scaled so that they occupy the same area.

As we downsample the image, we lose details in the texture such as the orientation of the knitting, and it becomes harder to see the overall shape. Just reducing resolution by a factor of 4 results in an almost unintelligible image. The loss of information is due to the reduced resolution, but most important, in this example, additional information is lost due to aliasing. Aliasing has introduced new texture features in the subsampled image that are not present in the original image and that could have been avoided.
How can we reduce the resolution of an image while preserving as many details as possible?
21.3.2 Decimation in the Fourier Domain
As we did before for the continuous case, analyzing how the decimation operator affects the signal in the Fourier domain can be very revealing. In this section we compute the relationship between the Fourier transform (FT) of the original image, \(\ell\) and the sampled one, \(\ell_{\downarrow k}\). We will use the finite length discrete Fourier transform (DFT). If the DFT of \(\ell\left[n,m\right]\) is \(\mathscr{L}\left[u,v\right]\), the DFT of the sampled image, \(\ell\left[kn,km\right]\) (with size \(N/k \times M/k\)), is: \[ \mathscr{L}_{\downarrow k} \left[u,v\right] = \sum_{n=0}^{N/k-1} \sum_{m=0}^{M/k-1} \ell\left[kn,km\right] \exp{ \left( -j2\pi \frac{nu}{N/k} \right)} \exp{ \left( -j2\pi \frac{mv}{M/k} \right)} \tag{21.1}\] as before, we can define an image, \(\ell_{\delta_k} \left[n,m\right]\), of same size as the input image, \(N \times M\), where we set to zero the samples that will be removed in the decimation operation: \[\begin{aligned} \ell_{\delta_k} \left[n,m\right] &= \ell\left[n,m\right] \sum_{s=0}^{N/k-1} \sum_{r=0}^{M/k-1} \delta \left[n - sk \, ,m - rk \right] \\ &= \ell\left[n,m\right] \delta_k \left[n,m\right]\end{aligned} \tag{21.2}\] where \(\delta_k \left[n,m\right]\) is the discrete version of the delta train.
Using \(\ell_{\delta_k}\) we can rewrite equation (Equation 21.1), with a change of the summation indices, as: \[\mathscr{L}_{\downarrow k} \left[u,v\right] = \sum_{n=0}^{N-1} \sum_{m=0}^{M-1} \ell_{\delta_k} \left[n,m\right] \exp{ \left( -j2\pi \frac{nu}{N} \right)} \exp{ \left( -j2\pi \frac{mv}{M} \right)}\]
Therefore, the DFT of \(\ell\left[kn,km\right]\) is the DFT of \(\ell_{\delta_k} \left[n,m\right]\), which is the product of two signals, equation (Equation 21.2). The first term is \(\ell\left[n,m\right]\), and the second term is a discrete delta train (also called the Kronecker comb): \[\delta_k \left[n,m\right] = \sum_{s=0}^{N/k-1} \sum_{r=0}^{M/k-1} \delta \left[n - sk \, ,m - rk \right]\]
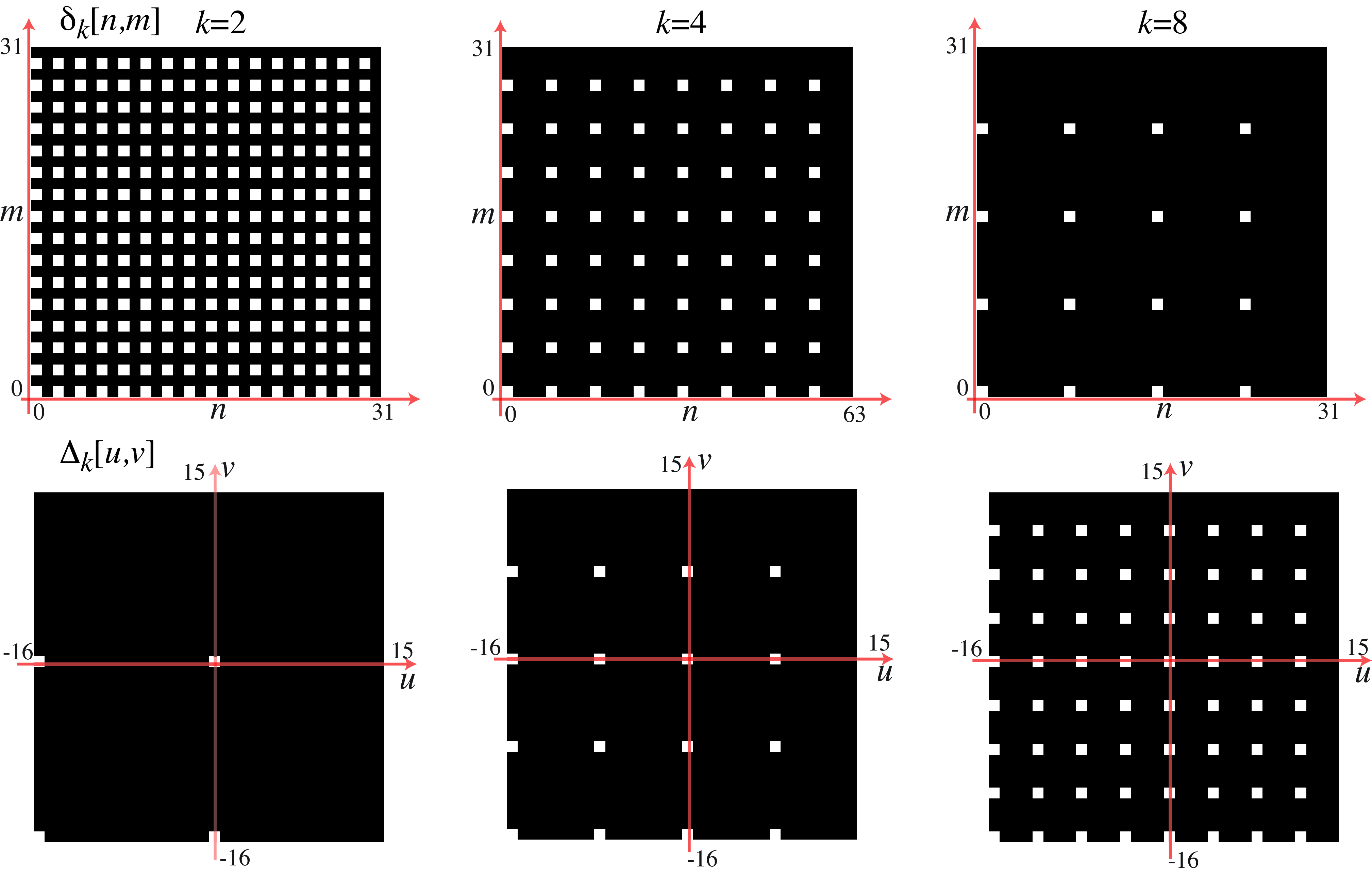
The DFT of the discrete delta train, when \(M\) and \(N\) are divisible by \(k\), is: \[\Delta_k \left[u,v\right] = \frac{NM}{k^2} \sum_{s=0}^{k-1} \sum_{r=0}^{k-1} \delta \left[u - s\frac{N}{k} \, ,v - r\frac{M}{k} \right]\]
This definition is valid for frequencies inside the interval \([u,v] \in [0,N-1]\times[0,N-1]\). Outside of that interval, we will have its periodic extension.
Figure 21.3 shows \(\delta_k \left[n,m\right]\) and its Fourier transform, \(\Delta_k \left[u,v\right]\), in the bottom, for images size of \(32 \times 32\) pixels. For the FT we plot signals using an interval that puts the frequency \([0,0]\) in the center.
Now we are ready to write the DFT of \(x_{\delta_k} \left[n,m\right]\). This is the DFT of the product of two images, equation (Equation 21.2), so we can apply the dual of the circular convolution theorem for finite length discrete signals (where both signals are extended periodically): \[\begin{aligned} \mathscr{L}_{\downarrow k} \left[u,v\right] &= \frac{1}{NM} \mathscr{L}\left[u,v\right] \circ \Delta_k \left[u,v\right] \\ \nonumber &= \frac{1}{k^2} \sum_{s=0}^{k-1} \sum_{r=0}^{k-1} \mathscr{L}\left[u - s\frac{N}{k} \, ,v - r\frac{M}{k} \right] \end{aligned} \tag{21.3}\]
The DFT of the sampled image by a factor \(k\) is the superposition of \(k \times k\) shifted copies of the DFT of the original image. Each copy is centered on one of the deltas in \(\Delta_k \left[u,v\right]\).
The images in Figure 21.4 show \(\ell_{\delta_k} \left[n,m\right]\) and \(\mathscr{L}_{\downarrow k} \left[u,v\right]\). The original image, \(\ell\left[n,m\right]\), is \(128 \times 128\). The DFT of the sampled image, \(\ell_{\downarrow k} \left[n,m\right]\), is the inner window with size \(N/2k \times M/2k\) (shown as a green square).
In the case of \(k=2\), it is useful to see how the spectrum of the decimated signal is obtained. As shown from equation (Equation 21.3), the resulting spectrum is a sum of shifted versions of the original spectrum, \(\mathscr{L}\left[u,v\right]\), as shown in Figure 21.5. The image shows the four copies that are summed to obtain the decimated spectrum:

The first component is \(\mathscr{L}\left[u,v\right]\), the three other copies are shifted versions of \(\mathscr{L}\left[u,v\right]\). Shifting is equivalent to a circular shift as \(\mathscr{L}\left[u,v\right]\) is periodic in \(u\) and \(v\). All the spectral content inside the green box in the shifted copies will produce aliasing after decimation.
21.3.3 Aliasing in Matrix Form
We can provide another description of decimation and aliasing using the matrix form of the decimation and DFT operators. As decimation and the Fourier transform are linear operators, we can write them as matrices. This description will provide a different visualization for the same phenomena described in the previous section. For simplicity of the visualizations we will work with 1D signals, but the same can be extended to 2D.
Using matrices, we can write decimation as \(\boldsymbol\ell_{\downarrow 2} = \mathbf{D}_2 \boldsymbol\ell\). We use the Fourier matrices \(\mathbf {F}_{N}\) and \(1/N \mathbf {F}^{*}_{N}\) to denote the DFT and its inverse (which is the complex conjugate of the DFT) for signals of length \(N\). Using this notation, the relationship between the original spectrum \(\mathscr{L}\left[u\right]\) and the sampled version, \(\mathscr{L}_{\downarrow 2} \left[u\right]\), is: \[\mathscr{L}_{\downarrow 2} = \frac{1}{N} \mathbf{F}_{N/2} \mathbf{D}_2 \mathbf{F}^{*}_{N} \mathscr{L} \tag{21.4}\]
One interesting property of the Fourier matrix is that \(\mathbf{D}_2 \mathbf{F}_{N} = [\mathbf{F}_{N/2} ~|~ \mathbf{F}_{N/2}]\). The matrix \(\mathbf{D}_2\) selects all the odd rows of the matrix \(\mathbf{F}_{N}\) and ignores the even ones. Therefore, \[\begin{aligned} \frac{1}{N} \mathbf{F}_{N/2} \mathbf{D}_2 \mathbf{F}^{*}_{N} &= \frac{1}{N}\mathbf{F}_{N/2} [\mathbf{F^*}_{N/2} ~|~ \mathbf{F^*}_{N/2}] \\ &= \frac{1}{N} \frac{N}{2} [\mathbf{I}_{N/2} ~|~ \mathbf{I}_{N/2}] \\ &= \frac{1}{2} [\mathbf{I}_{N/2} ~|~ \mathbf{I}_{N/2}] \end{aligned} \]
where \(\mathbf{I}_{N/2}\) is the identity matrix of size \(N/2 \times N/2\). Replacing this result inside equation (Equation 21.4) gives the following relationship between the DFT of the original signal and the subsampled one: \[ \mathscr{L}_{\downarrow 2} = \frac{1}{2} [\mathbf{I}_{N/2} ~|~ \mathbf{I}_{N/2}] \mathscr{L} \] This equation is analogous to Equation 21.3 with \(k=2\) and for 1D signals.
In 1D, we can visualize these operators which helps to make the previous derivations intuitive. For 1D signals of length \(N=16\), equation Equation 21.4 has the visual form shown in Figure 21.6:
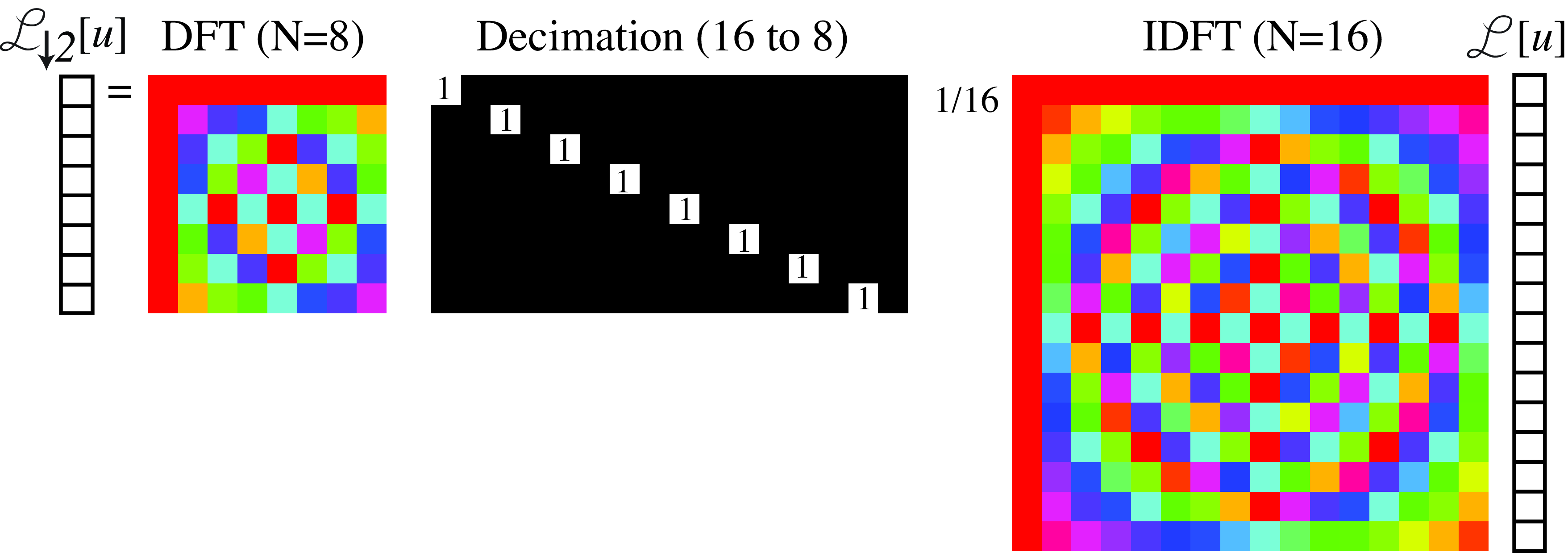
Note that for the matrices \(\mathbf{F}_{N}\) used here, we are not using the convention of putting the frequency 0 in the middle as this makes visualizations in matrix form easier.
The product between the decimation matrix and the inverse DFT, \(\mathbf{D}_2 \mathbf{F^*}_{16}\), is (Figure 21.7):

In Figure 21.7 we can see how the odd rows of \(\mathbf{F^*}_{16}\) gives a new sub matrix composed of two identical blocks. Interestingly, each of those two blocks are identical to \(\mathbf{F^*}_{8}\). A similar structure emerges also when applying \(\mathbf{D}_4\). Combining these last equations together, we get the final result:
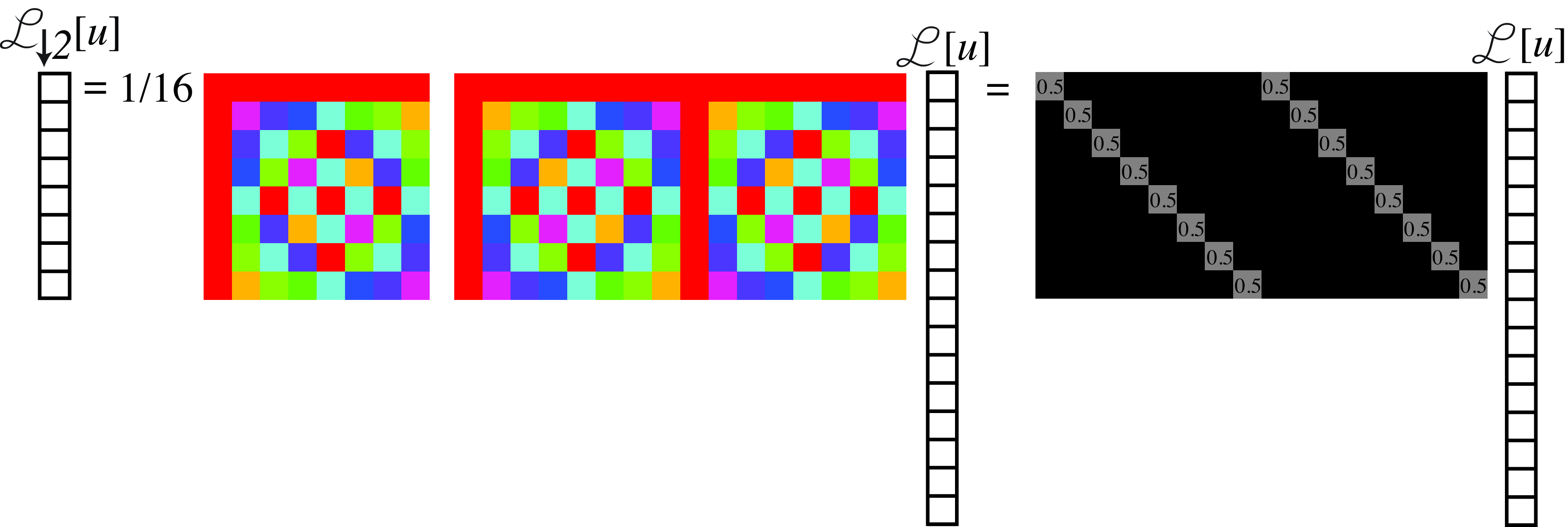
This last result shows visually how aliasing happens. Each component of the final DFT, \(\mathscr{L}_{\downarrow 2} \left[u\right]\), is the sum of two of the components of \(\mathscr{L}\left[u\right]\). For instance, \(\mathscr{L}_{\downarrow 2} \left[0\right] = 0.5 \mathscr{L}\left[0\right] + 0.5 \mathscr{L}\left[8\right]\). Both components are mixed in the final result.
In the next subsection we will discuss anti-aliasing filters. Anti-aliasing consists in setting to zero, before decimation, the \(N/k\) the spectral components that produce aliasing.
21.3.4 Anti-Aliasing Filters
Anti-aliasing filtering is an essential operation whenever we manipulate the resolution of an image. When decimating a signal of size \(N \times N\) with a scaling factor \(k\), aliasing is produced by all the content at frequencies that are above \(u,v > N/2k\). Therefore, to reduce aliasing, we have to remove any spectral content of the signal present at high spatial frequencies. We will do so by using an anti-aliasing filter that will blur the image before downsampling. Blurring removes high-spatial frequencies in the image.
The ideal anti-aliasing filter is a box in the Fourier domain with a cut-off frequency of \(L=N/(2k)\) (using the notation introduced in Chapter 20). The inverse Fourier transform of a box in the frequency domain, with width \(2L+1=N/k+1\), is the discrete sinc function of length \(N\) in the spatial domain: \[\frac{1}{N} \frac {\sin(\pi n (N/k+1)/N)} {\sin(\pi n/N)} \xrightarrow{\mathscr{F}} box_{N/2k} \left[ u \right]\]
In 2D, the ideal anti-aliasing filter is separable and is obtained by two consecutive 1D convolutions along each dimension. The discrete sinc is very similar to the continuous sinc described in Chapter 20. The discrete sinc is periodic, with period \(N\). The following plot (Figure 21.11) shows the anti-aliasing sinc for \(N=32\) and \(k=2\) and the magnitude of its Fourier transform:
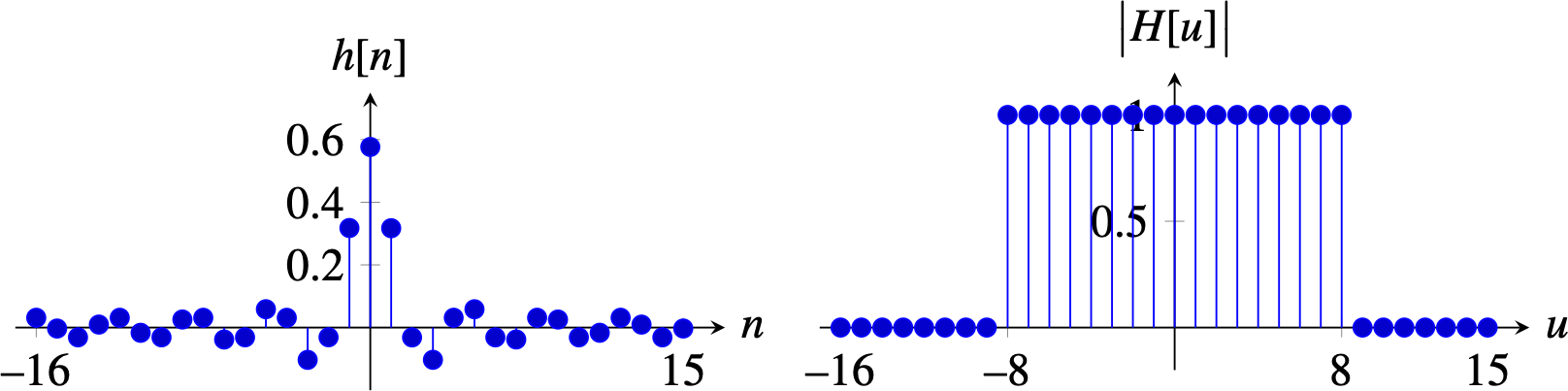
And for \(k=4\), the impulse response becomes wider and its Fourier transform has a lower cut-off frequency, \(N/2k = 4\):

One disadvantage of the ideal anti-aliasing filter is that the it requires convolving the image with a very large filter (as large as the image). We would like to use smaller filters to reduce the computational cost. One method to design anti-aliasing filters with a finite impulse response is to use a window, \(w [n]\), and to use as anti-aliasing filter the kernel \(w [n] h[n]\), where \(h[n]\) is the impulse response of the ideal anti-aliasing filter. Typical windows used are the rectangular, Hamming, Parzen, or Kaiser windows.
The rectangular window sets to zero all the values outside of the interval \(\left[-L, L\right]\). When \(L=5\), it gives a tap-11 filter (a filter with an impulse response of length 11) with the following profile:
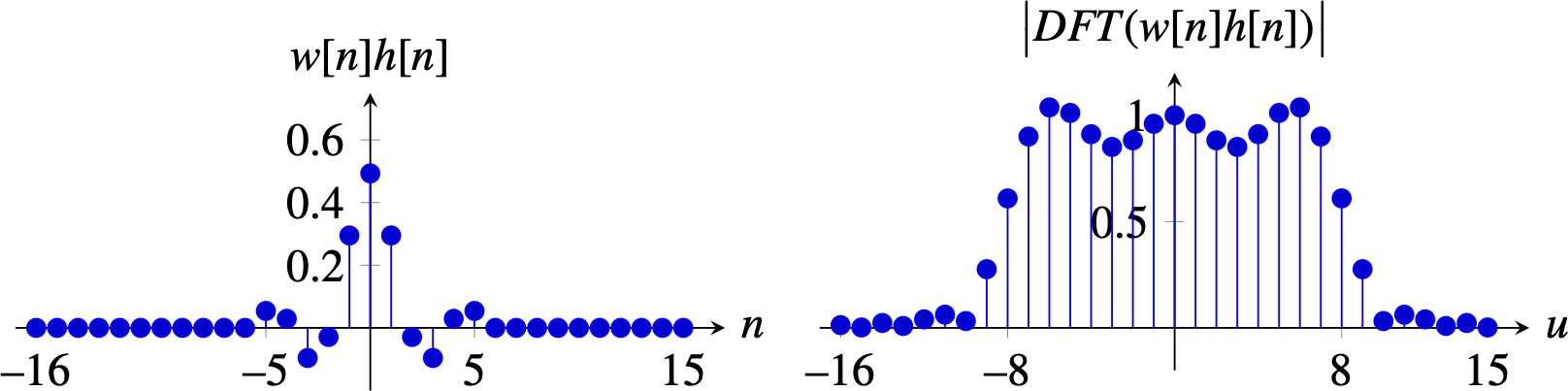
The Fourier transform of the windowed impulse response, \(w [n] h[n]\), is the convolution of Fourier transforms. The Fourier transform of the rectangular window is a sinc function. Therefore, the resulting Fourier transform is the convolution of the rectangle with the sinc function, which produces a smooth rectangle with some oscillations. Using other windows allows trading off the smoothing of the ideal rectangular form of the ideal low-pass filter and the oscillations.
The Hamming window is defined as: \[w \left[n\right] = \begin{cases} 0.54+0.46 \cos (\pi n/L) & \quad \text{if } n \in \left[-L, L\right] \\ 0 & \quad \text{otherwise }\\ \end{cases}\] The Hamming window (\(L=5\)) produces a smooth transfer function with oscillations of smaller amplitude in the Fourier domain: \[h = [1, 0.65, -2.45, -0.82, 8.8, 15, 8.8, -0.82, -2.45, 0.65, 1] / 29.36\]
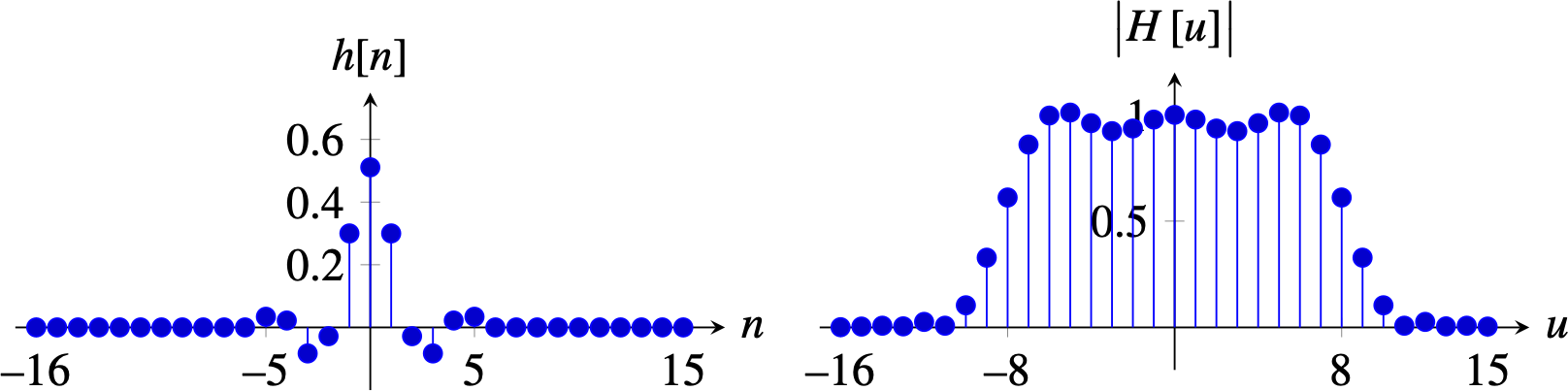
In practice, when we need very small anti-aliasing filters, binomial filters are a good choice. The binomial filter \(b_2\) has a DFT (length \(N\)) with a \(1+\cos(2\pi/N)\) profile. At the frequency \(N/4\) the gain is \(1/2\). Therefore, the spectral content responsible for aliasing will not be completely removed, but the attenuation is enough in most cases.
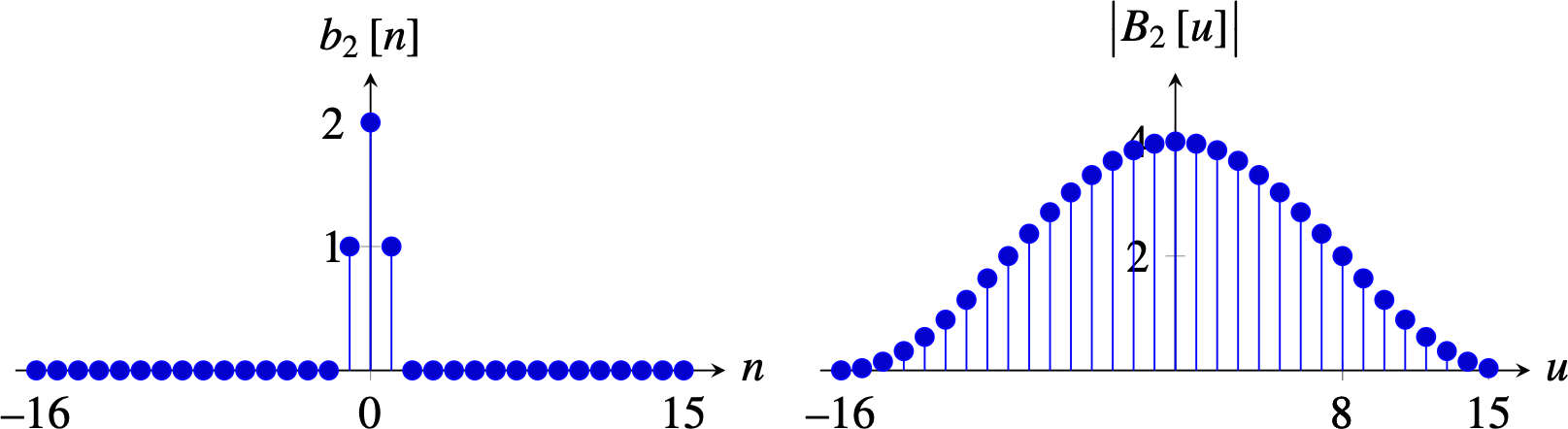
Or \(b_4 = [ 1, 4, 6, 4, 1]\), which attenuates the aliased frequencies even more, also results in an oversmoothed signal.
When implementing 2D anti-aliasing filters, we apply two consecutive 1D convolutions along each dimension. For efficiency, the anti-aliasing filter only needs to be computed on the samples that will be kept after downsampling (\(k\)-strided convolution). The necessary amount of attenuation of the aliasing frequencies will have to be decided based on each application.
In 2D, we can apply the binomial filter \(b_2\) on each dimension, \(\left[1,2,1\right]/4 \circ \left[1,2,1\right]^\mathsf{T}/4\).

The images in Figure 21.15 show the output of three different low-pass anti-aliasing filters. Note how the ideal low-pass filter introduces ringing artifacts in the output image (Figure 21.15[a]). Despite that it removes frequencies that will produce aliasing after downsampling, it does that at a high cost because it introduces undesired image structures, which is exactly what we want to prevent with the anti-aliasing filter. The Hamming windowed sinc (shown in Figure 21.15[b]) reduces the oscillation but there is still a halo present around edges. This is because there is still one oscillation on the filter impulse response. Figure 21.15 (c) shows the result applying am anti-aliasing binomial filter.
For most applications using a binomial filter (\(b_2\) or \(b_4\)) is enough because it reduces aliasing and it does not introduce undesired image structures.
21.3.5 Downsampling
We will call downsampling the sequence of applying an anti-aliasing filtering followed by decimation: \[\begin{aligned} z[n,m] &= \ell_{\texttt{in}}\left[n,m\right] \circ h_k \left[ n,m \right] & \quad\quad \triangleleft \quad \texttt{conv}\\ \ell_{\texttt{out}}[n,m] &= z[kn,km] & \quad\quad \triangleleft \quad \texttt{decimation} \end{aligned}\]
Figure 21.16 shows the results when using a binomial filter as the anti-aliasing filter followed by decimation by 2, and Figure 21.17 shows results for different downsampling factors.

In the anti-aliased downsampled images shown in Figure 21.17, fine details are gone while preserving the smooth details of the image. In fact, as shown in the images below, even at \(32 \times 32\), we can still see some of the orientations of the knitting pattern and the shading due to the three-dimensional shape.

As the convolution and downsampling are linear operators, sometimes it will be useful to write it as a matrix. For instance, for a 1D signal of length \(N=8\) samples, if we downsample it by a factor \(k=2\), then, using repeat padding for handling the boundary, and the binomial kernel as an anti-aliasing filter, we can write the downsampling operator as a matrix:
\[\mathbf{D}_2 = \frac{1}{4} \left[ \begin{array}{cccccccc} 3 & 1 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 1 & 2 & 1 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 1 & 2 & 1 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 1 & 2 & 1 \end{array} \right]\]
Downsampling by a factor \(k=2^n\) is usually done by a sequence of \(n\) stages of binomial filtering followed by downsampling by 2. Non-integer downsampling factors require an interpolation step instead of decimation.
21.4 Upsampling
Upsampling requires increasing the resolution of an image from a low resolution image. This is a very challenging task that requires recovering information that is not available on the low resolution image. The problem of making up new details will be called super-resolution. In this section we will focus on the simpler problem of creating an image that has \(k\) times more pixels along each dimension but that contains the same amount of information than the original lower-resolution image. That is, we will not require to the upsampling procedure to predict any of the missing high-resolution details.
Upsampling requires interpolating sample values. We want to obtain a new image \(\ell_{\texttt{out}}\) with more samples than the input image \(\ell_{\texttt{in}}\). In order to interpolate a new sample \(\ell_{\texttt{out}}(a,b)\), where \(a\) and \(b\) are continuous values, we can use different interpolations functions as we will discuss next.
21.4.1 Nearest Neighbor Interpolation
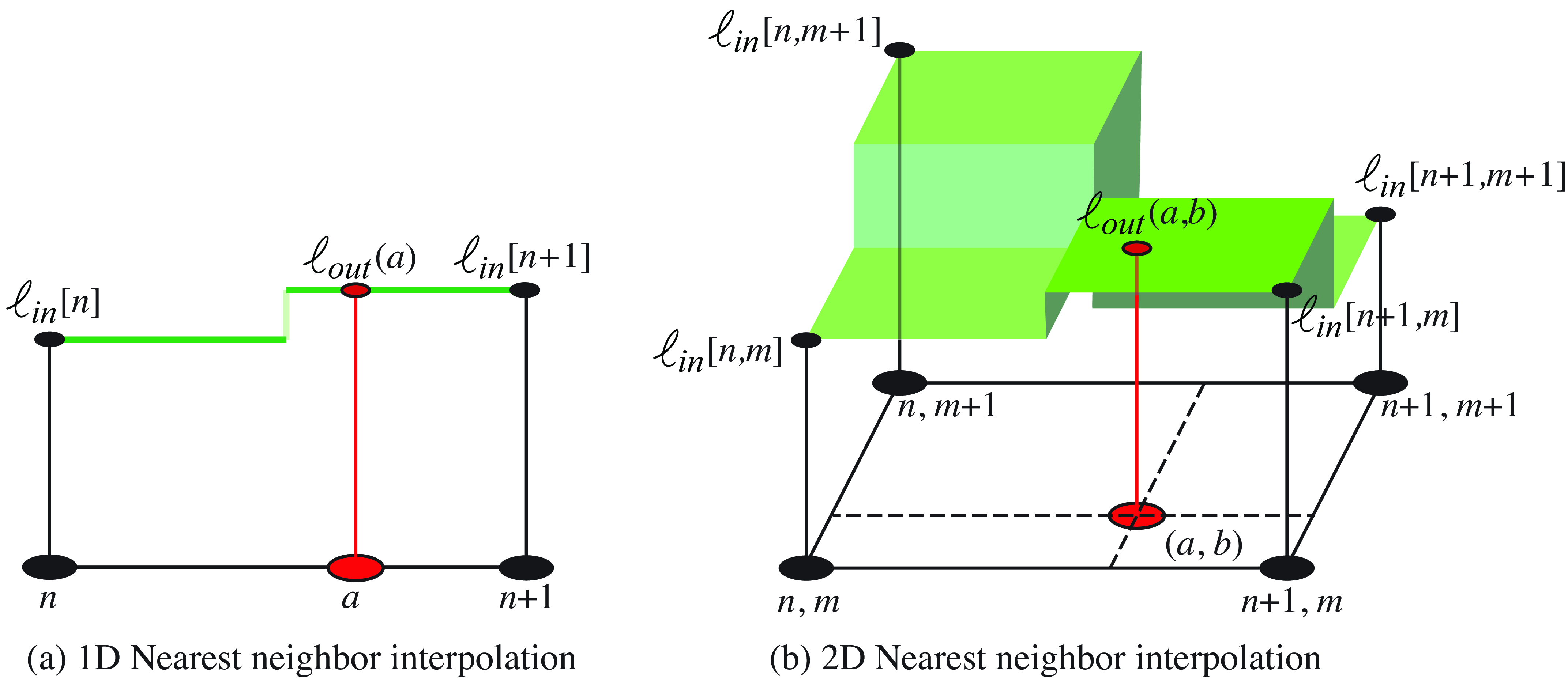
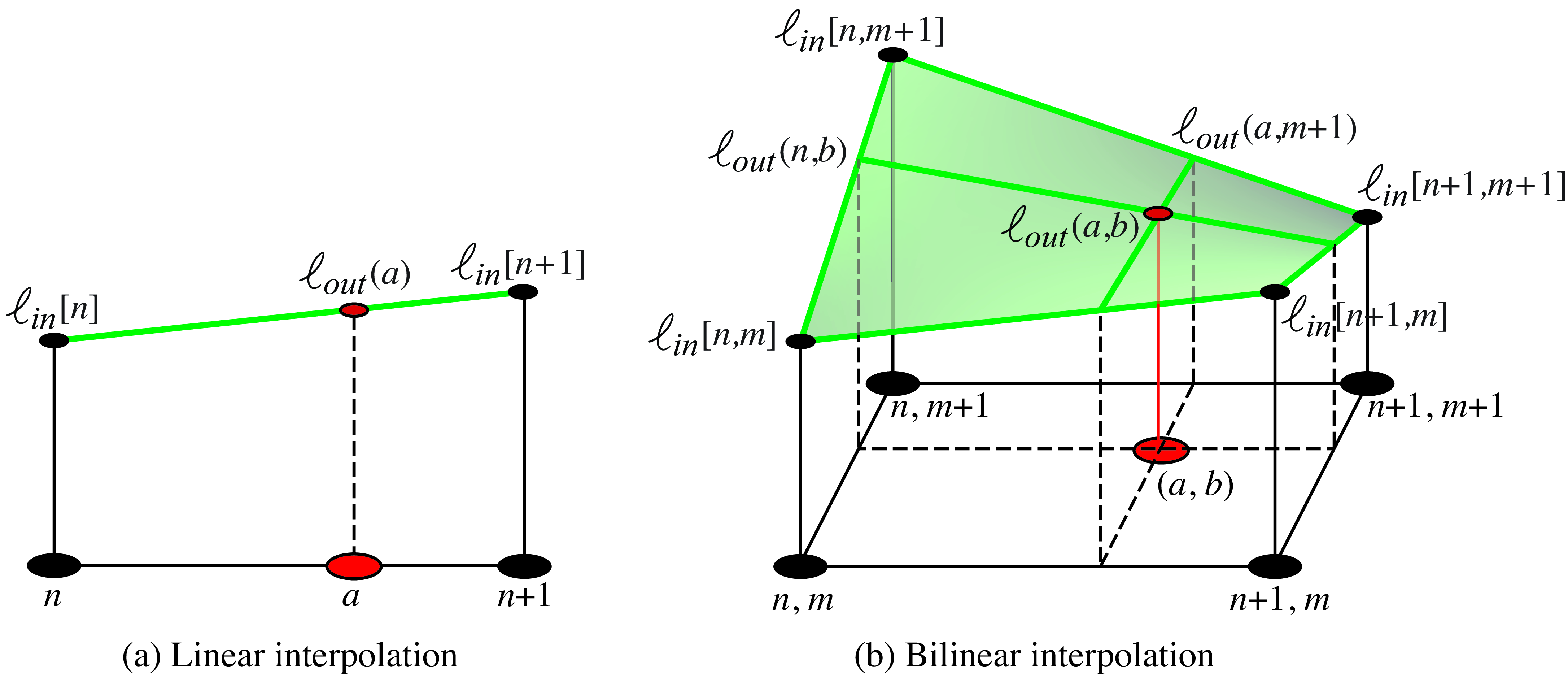
In nearest neighbor interpolation we assign to \(\ell_{\texttt{out}}(a,b)\) the closest value of the input \(\ell_{\texttt{in}}\): \[\ell_{\texttt{out}}(a,b) = \ell_{\texttt{in}}[ n, m ]\] where \(n-0.5<a<n+0.5\) and \(m-0.5<b<m+0.5\). Note that here we are treating \(\ell_{\texttt{out}}(a,b)\) as a continuous image. Nearest neighbor interpolation results in an image that is piecewise-constant. Figure 21.18 shows the nearest neighbor interpolation process graphically.
21.4.2 Linear and Bilinear Interpolation
For 1D signals, the value of \(\ell_{\texttt{out}}(a)\) is a result of linear interpolation between the two closest input values \(\ell_{\texttt{in}}[n]\) and \(\ell_{\texttt{in}}[n+1]\), where \(n<a<n+1\).
Interpolation is also a key operation when performing image warping.
For 2D signals, we have to interpolate the output value \(\ell_{\texttt{out}}(a,b)\) using four input samples: \(\ell_{\texttt{in}}[ n,m ]\), \(\ell_{\texttt{in}}[ n+1,m ]\), \(\ell_{\texttt{in}}[ n,m+1 ]\) and \(\ell_{\texttt{in}}[ n+1,m+1 ]\), where \(n<a<n+1\) and \(m<b<m+1\).
Bilinear interpolation consists of first applying linear interpolation to obtain \(\ell_{\texttt{out}}(a,m)\) and \(\ell_{\texttt{out}}(a,m+1)\) and then again applying linear interpolation between those two values to obtain \(\ell_{\texttt{out}}(a,b)\). The result is illustrated in Figure 21.19.
The linear (and bilinear) interpolations are linear operations. In the case when the upsampling factor \(k\) is an integer value, the resampling operator can be efficiently implemented as a sequence of two operations: expansion and interpolation. The interpolation operation, as it is linear and spatially stationary, can be efficiently implemented as a convolution.
21.4.3 Expansion
Expansion by a factor \(k\) consists in increasing the number of samples in the image by inserting \(k-1\) zeros between each sample on the horizontal dimension, and then on the vertical dimension. This will give us the image of size \(Nk \times Mk\). We will use the notation: \[\ell_{\uparrow k} \left[n,m\right] = \ell\left[n,m\right] \uparrow k\]
Expansion is a linear operator that is the transposed to the decimation operation and is defined as: \[\ell_{\uparrow k} \left[n,m\right] = \begin{cases} \ell\left[n/k,m/k\right] & \quad \text{if~} \text{mod} (n,k)=0 \text{~and~} \text{mod} (m,k)=0\\ 0 & \quad \text{otherwise }\\ \end{cases} \tag{21.5}\]
In the 1D case, for a signal of length 4, expanding by a factor of \(k=2\) can be described by the following linear operator: \[\mathbf{E}_2 = \left[ \begin{array}{cccc} 1 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0\\ 0 & 1 & 0 & 0\\ 0 & 0 & 0 & 0\\ 0 & 0 & 1 & 0\\ 0 & 0 & 0 & 0\\ 0 & 0 & 0 & 1\\ 0 & 0 & 0 & 0 \end{array} \right]\]
21.4.4 Interpolation Filters
When the upsampling factor \(k\) is an integer value, interpolation using the methods described in section Section 21.4.1 can be implemented using a convolution. The interpolation filters we will discuss here are separable, so the convolution kernel can be written as the product \(h\left[n,m\right] = h\left[n\right] h\left[m\right]\):
As we discussed before, there are different interpolation methods: nearest neighbor, bilinear, and so on. In this section we will study them by looking at the convolution kernel needed to implement each interpolation method.
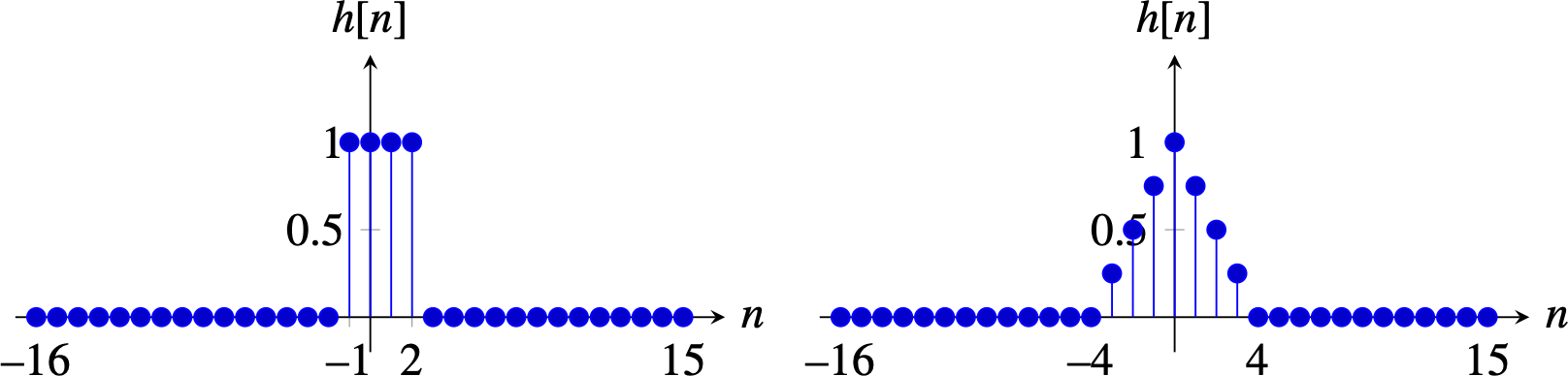
Nearest neighbor interpolation consists of assigning to each interpolated sample the value of the closest sample from the input signal. This can be done by convolving the expanded image from equation (Equation 21.5) with the kernel (if \(k\) is even): \[h \left[n\right] = \begin{cases} 1 & \quad \text{if } n \in \left[-k/2+1, k/2\right] \\ 0 & \quad \text{otherwise }\\ \end{cases}\] This is very fast as it only requires replicating samples. But it gives very low quality. For \(k=2\), the convolution kernel in 1D is \(h \left[n\right]=[1, 1]\)
Bilinear interpolation: As we discussed before, bilinear interpolation is done in two stages: first, linearly interpolate each sample with the two nearest neighbors across rows, and then do the same for the columns. This can also be written as a convolution with the kernel (if \(k\) is even):
\[h \left[n\right] = \begin{cases} (k-n)/k & \quad \text{if } n \in \left[-k, k\right] \\ 0 & \quad \text{otherwise }\\ \end{cases} \]
In the special case where \(k=2\), the 1D bilinear interpolation kernel reduces to the binomial filter \(h[n] = \left[1/2,1,1/2\right]\). And in 2D, for \(k=2\), the kernel is \(\left[1/2,1,1/2\right] \circ \left[1/2,1,1/2\right]^\mathsf{T}\). The binomial filter is not the best interpolation filter, but it is very efficient. When quality is important, there are better interpolation filters.
The plots in Figure 21.20 show the nearest neighbor and linear interpolation kernels for \(k=4\).
Other popular interpolation methods are the bicubic interpolation and the Lanczos interpolation.
21.4.5 Upsampling
Upsampling consists in the sequence of expansion followed by interpolation:
\[\begin{aligned} z \left[n,m\right] &= \ell_{\texttt{in}}\left[n,m\right] \uparrow k & \quad\quad \triangleleft \quad \texttt{expansion}\\ \ell_{\texttt{out}}[n,m] &= z \left[n,m\right] \circ h_k \left[n,m\right] & \quad\quad \triangleleft \quad \texttt{conv} \end{aligned}\]
Upsampling by a factor of 2 is done by inserting one 0 between each two samples (first for the horizontal dimension and then for the vertical one), and then interpolating between samples applying the binomial filter \(\left[1/2,1,1/2\right] \circ \left[1/2,1,1/2\right]^\mathsf{T}\).
Figure 21.21 shows the upsampling process for a color image. Each color channel is upsampled by a factor of \(k=2\) independently. The top row shows the input image, the expanded image by inserting zeros between samples, the binomial kernel and the resulting interpolated image. The bottom row shows the magnitude of DFTs of each corresponding image. Note that the binomial interpolation filter does not completely suppress the copies of the original DFT that appear when inserting new samples. Remember that the DFTs have the same number of samples as the corresponding input image. The DFT of the kernel is shown by zero padding the convolutional kernel to match the image size. Despite that this interpolation does correspond to an ideal interpolation filter (a sinc) the interpolated image looks reasonably good.

The upsampling operator is also a linear operation, therefore we can also write it in matrix form. For instance, for a 1D signal of length \(N=4\) samples, if we upsample it by a factor \(k=2\), then, using repeat padding for handling the boundary and the bilinear interpolation, we can write the upsampling operator as a matrix: \[\mathbf{U}_2 = \left[ \begin{array}{cccc} 1 & 0 & 0 & 0\\ 0.5 & 0.5 & 0 & 0\\ 0 & 1 & 0 & 0\\ 0 & 0.5 & 0.5 & 0\\ 0 & 0 & 1 & 0\\ 0 & 0 & 0.5& 0.5\\ 0 & 0 & 0 & 1\\ 0 & 0 & 0 & 1 \end{array} \right]\]
Multiplying this matrix by a signal of length 4, gives an output signal of length 8. The output samples at locations 1, 3, 5, 7, and 8 are copies of the input samples 1, 2, 3, and 4, while samples 2, 4, and 6 are computed as the average of two consecutive input samples. The last output sample is a copy of the last input sample because it corresponds to extending the input using repeat padding.
21.5 Concluding Remarks
Aliasing is a constant source of problems in many image processing pipelines. In computer vision, aliasing can introduce noise, spurious features and textures, and lack of translation invariance. In Chapter 24, we will discuss how aliasing affects the quality of some of the convolutional layers used in neural networks.
Some of the tools we discussed in this chapter will also be used in other settings, such as when building image pyramids (Chapter 23) and in geometry (Chapter 38).
Aliasing is often a source of image artifacts in generative image models. One example is generative adversarial networks (Chapter 32) where images are produced as a sequence of learned convolutions and upsampling stages. When the upsampling operations are done without paying attention to aliasing, the output images show a number of artifacts, as has been shown in [2]. Those artifacts can be removed by carefully implementing each stage to avoid aliasing.