42 Single View Metrology
42.1 Introduction
The goal of this chapter is to introduce a set of techniques that allows recovering three-dimensional (3D) information about the scene from a single image like the picture of the office we used before (Figure 42.1).

Single view metrology relies on understanding the geometry of the image formation process, the rules of perspective, and other visual cues present in the image to answer questions about the 3D structure of the scene. This is in contrast to other methods, like stereo vision, structure from motion or multiview geometry, which utilize multiple images to reconstruct 3D information. The reader should consult specialized monographs for a deeper analysis such as the book on multiview geometry by Hartley and Zisserman [1].
There are many scenarios where recovering 3D information from a single view is important. There are applications from which only one view is available, such as when looking at paintings or TV, when analyzing photographs, and so on. Even when we have stereo vision, stereo is only effective when the disparity is large enough which limits the range of distances for which stereo can be used reliably.
We could just start by diving into learning-based methods and train a huge neural network to solve the task, but that would be no fun (we will do it later, no worries). Instead, we will start by using a model based single-view metrology. There will be no learning involved. Instead we will derive cues for 3D estimation from first principles.
42.2 A Few Notes about Perception of Depth by Humans
The image in Figure 42.2, recreated from Mezzanotte and Biederman [2], displays a flat set of lines that elicit a powerful 3D perception. Even more striking is that we perceive far more than mere 3D geometric figures (which is already intriguing, considering we are looking at a flat piece of paper). We discern buildings, people, a car in the street, the sky between the structures, and even what appears to be the entrance to a movie theater on the left sidewalk. Yet, the sidewalk is simply one line!
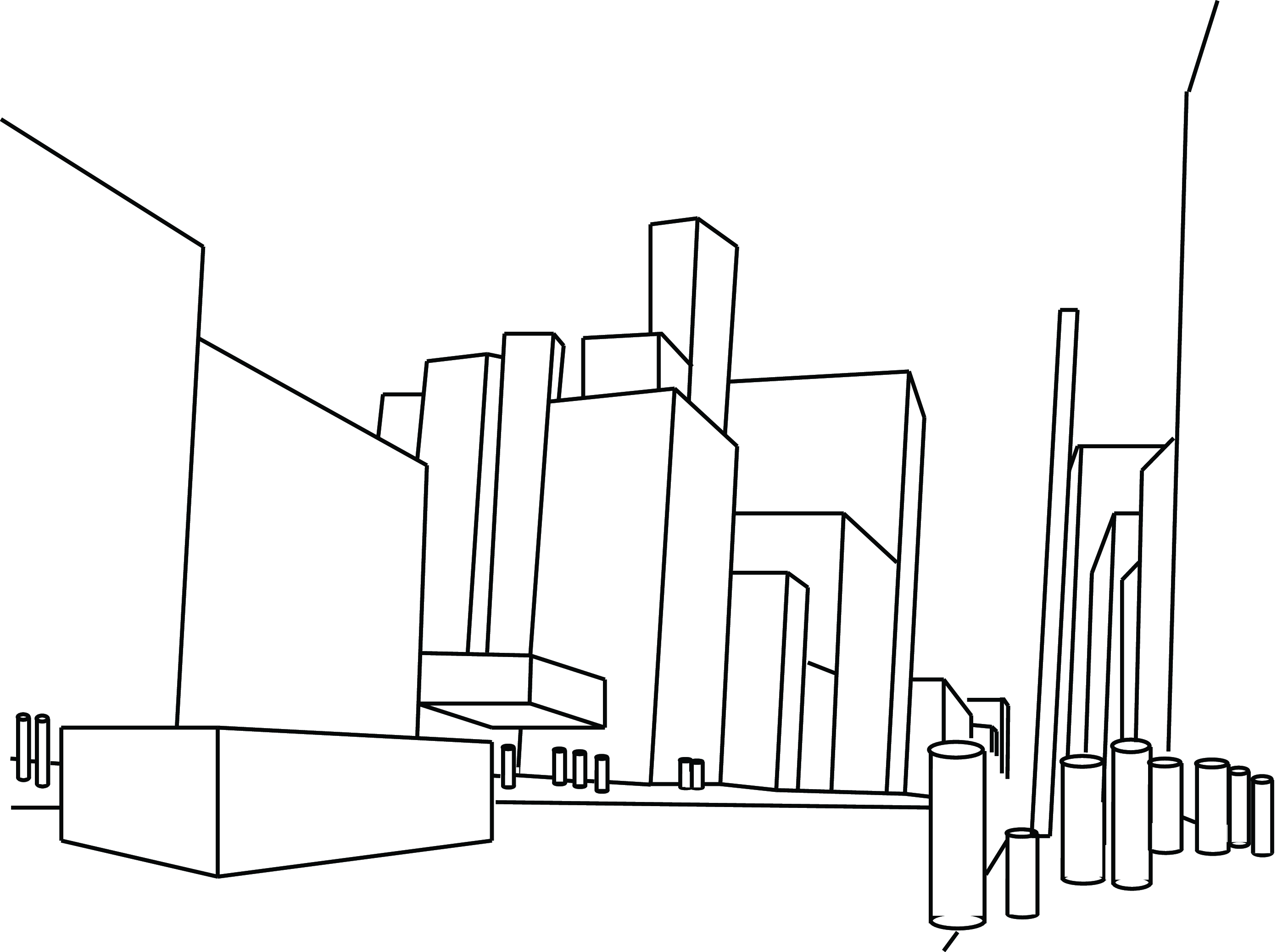
We perceive everything we see in the sketch as 3D, even when we know that it’s merely a 2D image. Our 3D processing is ingrained that we cannot easily switch off. That said, we are aware that it is just a collection of lines and geometric figures drawn on a flat piece of paper, but the 3D interpretation transforms the way in which we perceive the sketch. The influence of the 3D perceptual mechanisms is better appreciated when looking at visual illusions.
The Ames room was invented by Adelbert Ames, director of research at the Dartmouth Eye Institute, in 1946. Since then, illusions based on Ames’ ideas have been utilized by comedians to create amusing effects.
3D visual illusions are remarkably powerful. One captivating 3D illusion is the Ames room.
The Ames room is an irregular room constructed in such a way that when you look at it with one eye from a particular vantage point, the room appears to be perfectly rectangular. This is achieved by making the part of the wall that is farther away from the viewer larger so that it appears fronto-parallel.
Geometric description of the Ames room visual illusion.
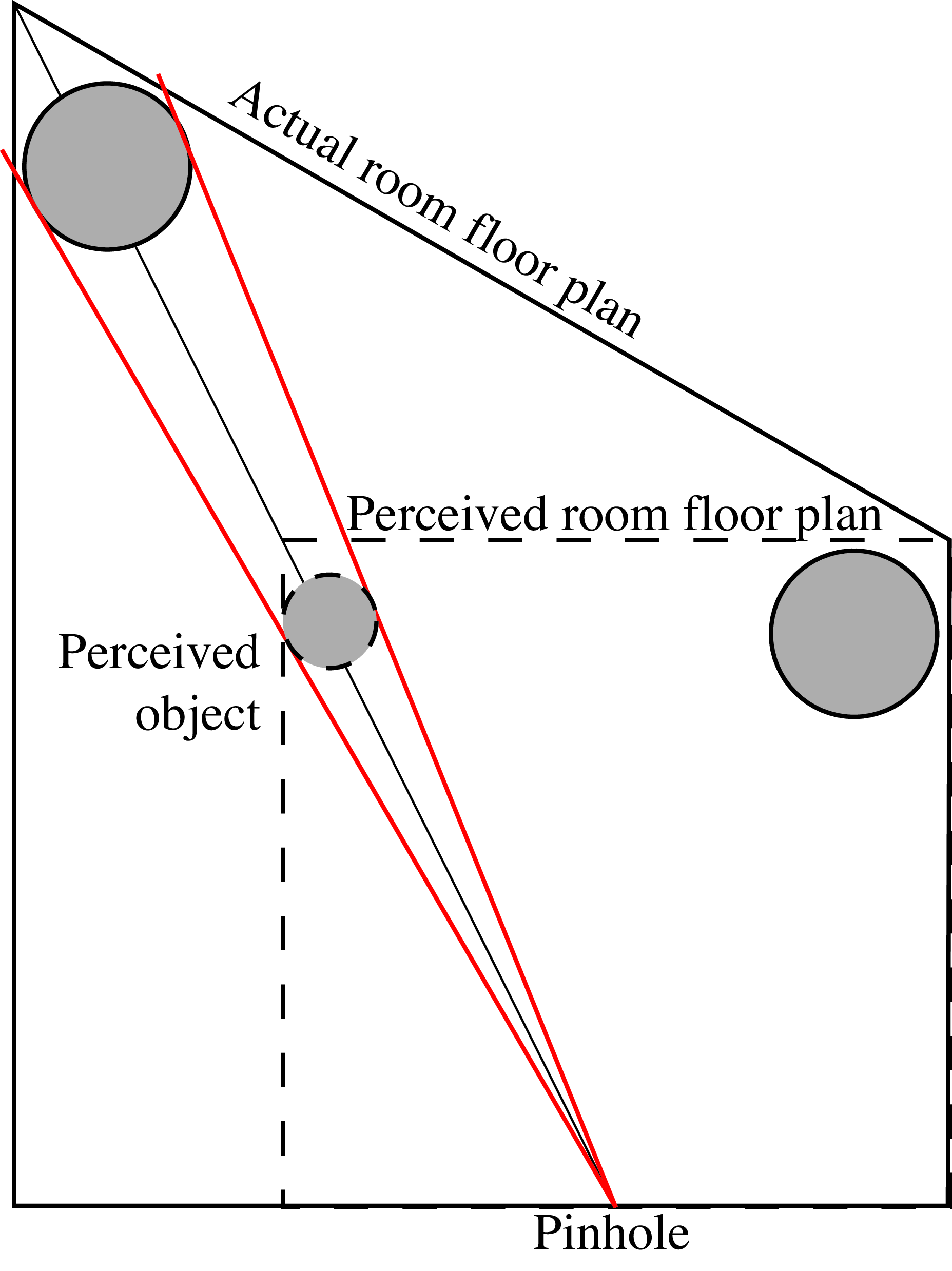
The best way to understand this illusion is by building it and experiencing it by yourself. You can find the instructions in Figure 42.3. When you look thought the aperture on the wall indicated by “cut” the room will appear square and smaller than it actually is, and it will seem as if you are looking inside the room from the middle of it despite that the opening is closer to the right wall.
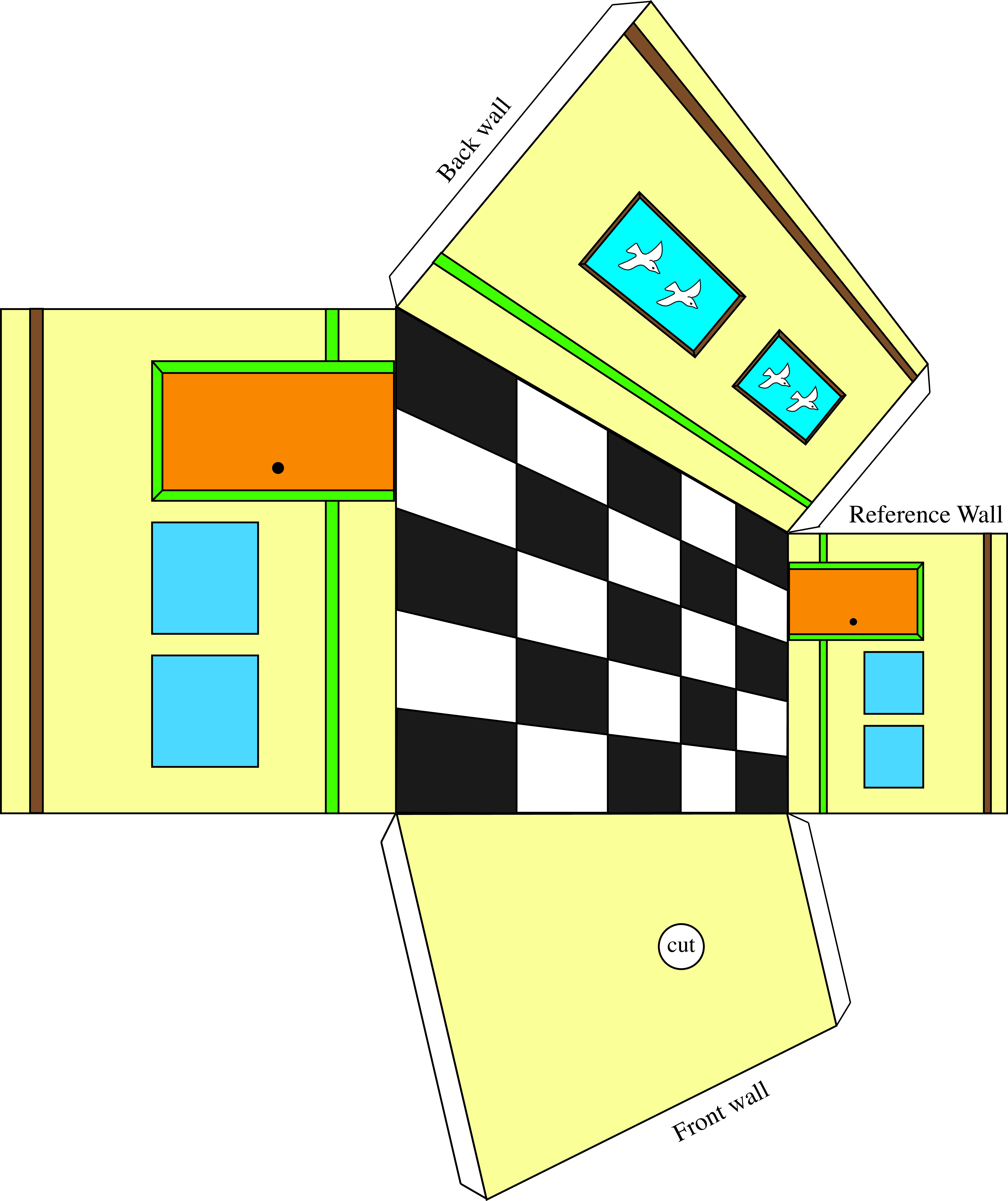
This illusion is especially remarkable when the room is large enough for people to walk in. You will notice that as people walk along the back wall, they appear to change in height. Your perception will disregard all of your (very strong) prior expectations about how that person should appear. Figure 42.4 illustrates this phenomenon with our cut-out version of the Ames room.


Clearly, a single image contains very strong cues about the 3D scene structure. In the following sections we will study linear perspective, arguably the most powerful among all pictorial cues used for 3D interpretation from a 2D image.
42.3 Linear Perspective
Linear perspective uses parallel and orthogonal lines, vanishing points, the ground plane and the horizon line to infer the 3D scene structure from a 2D image.
The discovery of linear perspective is attributed to the Italian architect Fillipo Brunelleschi in 1415.
As we will see in the following sections, linear perspective relies on a few assumptions about the scene and, as a consequence, linear perspective is not a general cue that is useful in all scenes, but it is very powerful in most human-made environments.
42.3.1 Projection of 3D Lines
In perspective projection, 3D lines project into 2D lines in the camera plane. Let’s start writing the parametric vector form of a 3D line using heterogeneous coordinates. We can parameterize a 3D line with a point, \(\mathbf{P}_0=[X_0, Y_0, Z_0]^\mathsf{T}\), and a direction vector, \(\mathbf{D} = [D_X, D_Y, D_Z]^\mathsf{T}\), as:
\[\mathbf{P}_t = \begin{bmatrix} X_0 + t D_x\\ Y_0 + t D_y\\ Z_0 + t D_z \end{bmatrix} \tag{42.1}\] The 3D point \(\mathbf{P}_t\) moves along a line when the independent variable \(t\) goes from \(-\infty\) to \(\infty\). A camera located in the world coordinates origin will observe a 2D line resulting from projecting the 3D line into the camera plane as shown in the sketch shown in Figure 42.5.
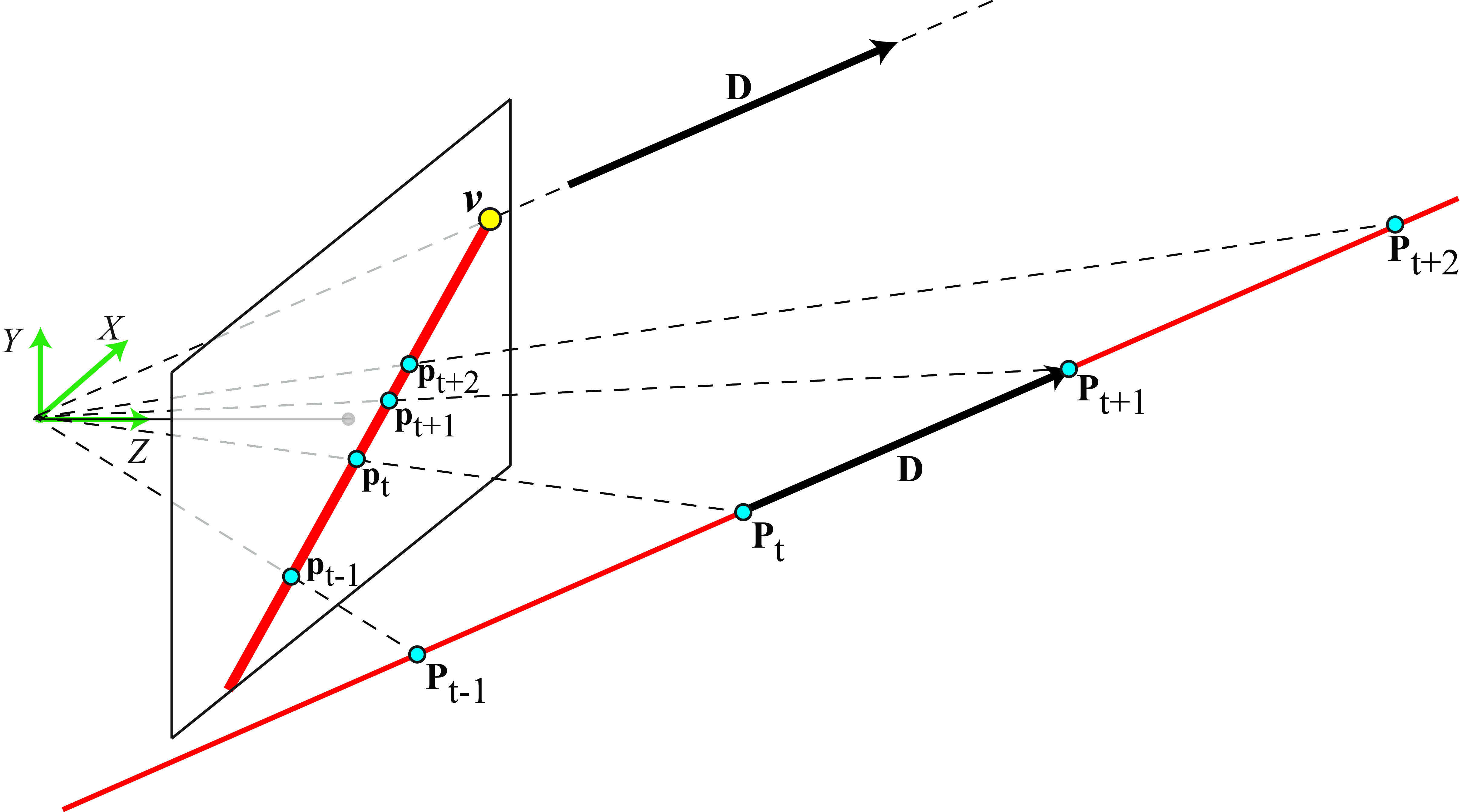
We can get the equation of the 2D line that appears in the image by using the perspective projection equations, resulting in: \[\mathbf{p}_t = \begin{bmatrix} x_t\\ y_t \end{bmatrix} = \begin{bmatrix} f \dfrac{ X_0 + t D_X}{Z_0 + t D_Z}\\[12pt] f \dfrac{ Y_0 + t D_Y}{Z_0 + t D_Z} \end{bmatrix} \tag{42.2}\]
42.3.2 Vanishing Points
Even though a line in 3D space extends infinitely, its 2D projection doesn’t. According to equation (Equation 42.2), in the limit when \(t\) goes to infinity, the line converges to a finite point called the vanishing point: \[\begin{aligned} \mathbf{v} = \lim_{t \to \infty} \mathbf{p}_t = \left [ \begin{array}{c} f \dfrac{D_X}{D_Z}\\[12pt] f \dfrac{D_Y}{D_Z} \end{array} \right ]\end{aligned} \tag{42.3}\] The vanishing point, \(\mathbf{v} = [v_x, v_y]^\mathsf{T}\), only depends on the direction vector, \(\mathbf{D}\), thus all parallel lines in 3D project into non-parallel 2D images that converge to the same vanishing point in the image. If \(D_Z = 0\) then the 3D line is parallel to the camera plane and the vanishing point is in infinite.
Figure 42.6 shows a set of parallel 3D lines and their 2D image projections. Each group of parallel lines converges to a different vanishing point. Lines that are parallel to the camera plane remain parallel as they converge to a vanishing point in infinity.
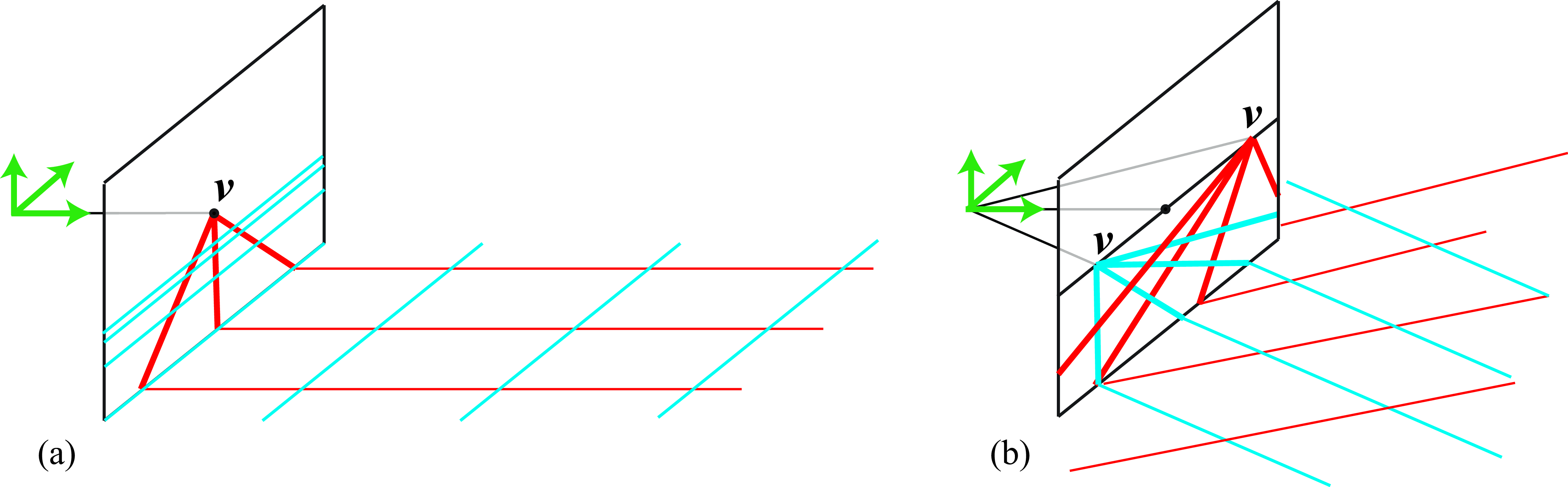
All the sets of parallel lines inside a plane converge to a set of co-linear vanishing points. These points lie along the plane’s horizon line.
Vanishing points are very useful to recover the missing depth of the scene as we will see later. The human visual system also makes use of vanishing points for 3D perception. Take, for example, the leaning tower visual illusion [3] as depicted in Figure 42.7. Here, a pair of identical images of the Leaning Tower of Pisa are placed side by side. Interestingly, despite being identical, they create an illusion of leaning with different angles. The image on the right appears to have a greater tilt than the one on the left. One explanation of this illusion is that the lines of each tower converge at a different vanishing point. If both towers were parallel in 3D, all the lines would converge to the same 2D vanishing point. As they do not, our brain interprets that the towers should have different 3D orientations. This process is automatic and we can not shut it down despite the fact that we know both images are identical.

Homogeneous coordinates offer an alternative way of working with vanishing points. Let’s start by writing the parametric vector form of a 3D line using homogeneous coordinates: \[\mathbf{P}_t = \begin{bmatrix} X_0 + t D_X\\ Y_0 + t D_Y\\ Z_0 + t D_Z\\ 1 \end{bmatrix} = \begin{bmatrix} X_0/t + D_X\\ Y_0 /t+ D_Y\\ Z_0/t + D_Z\\ 1/t \end{bmatrix} \tag{42.4}\] The first term is equivalent to the writing of the line in equation (Equation 42.1). As homogeneous coordinates are invariant to a global scaling, we can divide the vector by \(t\) which results in the second equality.In the limit \(t \to \infty\) the fourth coordinate of equation (Equation 42.4) converges resulting in: \[\mathbf{P}_\infty = \begin{bmatrix} D_X\\ D_Y\\ D_Z\\ 0 \end{bmatrix} = \begin{bmatrix} \mathbf{D}\\ 0 \end{bmatrix}\] Note that here we are representing a point at infinity with finite homogeneous coordinates. This is another of the advantages of homogeneous coordinates.
Homogeneous coordinates allow us to represent points at infinity with finite coordinates by setting the last element to 0.
The vanishing point, in homogeneous coordinates, is the result of projecting \(\mathbf{P}_\infty\) using the camera model, \(\mathbf{M}\): \[\mathbf{v} = \mathbf{M} \mathbf{P}_\infty = \mathbf{K} \begin{bmatrix} \mathbf{R} & \mathbf{T} \end{bmatrix} \begin{bmatrix} \mathbf{D}\\ 0 \end{bmatrix} = \mathbf{K} \mathbf{R} \mathbf{D} \tag{42.5}\] The last equality is obtained by using equation (Equation 39.9), and it shows that the vanishing point coordinates do not depend on camera translation. Only a camera rotation will change the location of the vanishing points in an image. If a scene is captured by two identical cameras translated from each other, their corresponding images will have the same vanishing points.
Both equation (Equation 42.3) and equation (Equation 42.5) are equivalent if we replace \(\mathbf{K}\) by the appropriate perspective camera model.
If instead of perspective projection, we have parallel projection, then all the vanishing points will project at infinity in the image plane.
42.3.3 Horizon Line
Any 3D plane becomes a half-plane in the image and has an horizon line. The horizon line is the line that passes by all the vanishing points of all the lines contained in the plane as shown in Figure 42.8.
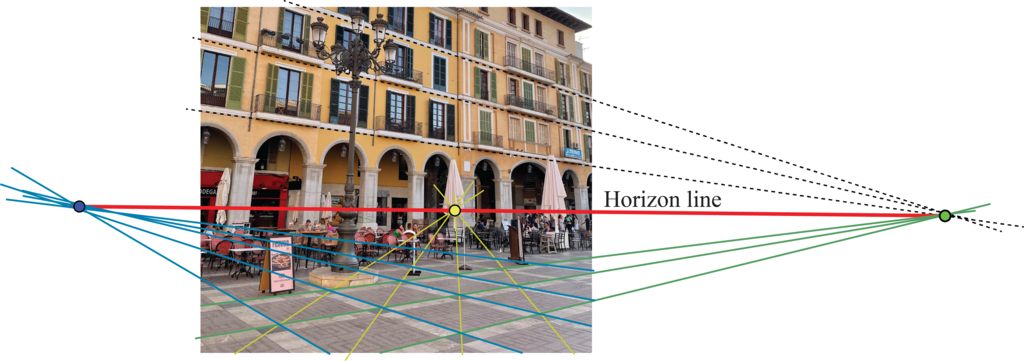
As parallel lines converge to the same vanishing point, parallel planes also have the same horizon line. In Figure 42.8, the lines in the building facade that are parallel to the ground also converge to a vanishing point that lies on the horizon line. In this particular examples, the lines in the facade also happen to be parallel to one of the axis of the floor tiles, converging to the same vanishing point on the right side of the figure.
The ground plane is a special plane because it supports most objects. This is different than a wall. Both are planes, but the ground has an ecological importance that a wall does not have. The point of contact between objects and the ground plane informs about its distance. The distance between the contact point and the horizon line is related to distance between the object and the camera. Objects further away have a contact point projecting onto a higher point in the image plane.
Figure 42.9 illustrates how to detect the horizon line using homogeneous coordinates. If lines \(\boldsymbol{l}_1\) and \(\boldsymbol{l}_2\), in homogeneous coordinates, correspond to the 2D projection of 3D parallel lines, we can obtain the vanishing point as their intersection (cross-product, \(\boldsymbol{l}_1 \times \boldsymbol{l}_2\)). If we now have another set of parallel lines, contained in the same plane, \(\boldsymbol{l}_3\) and \(\boldsymbol{l}_4\), we can get another vanishing point by computing their cross-product. Finally, the horizon line is the line that passes through both points that can be computed as the cross-product of the vanishing points in homogeneous coordinates.

42.3.4 Detecting Vanishing Points
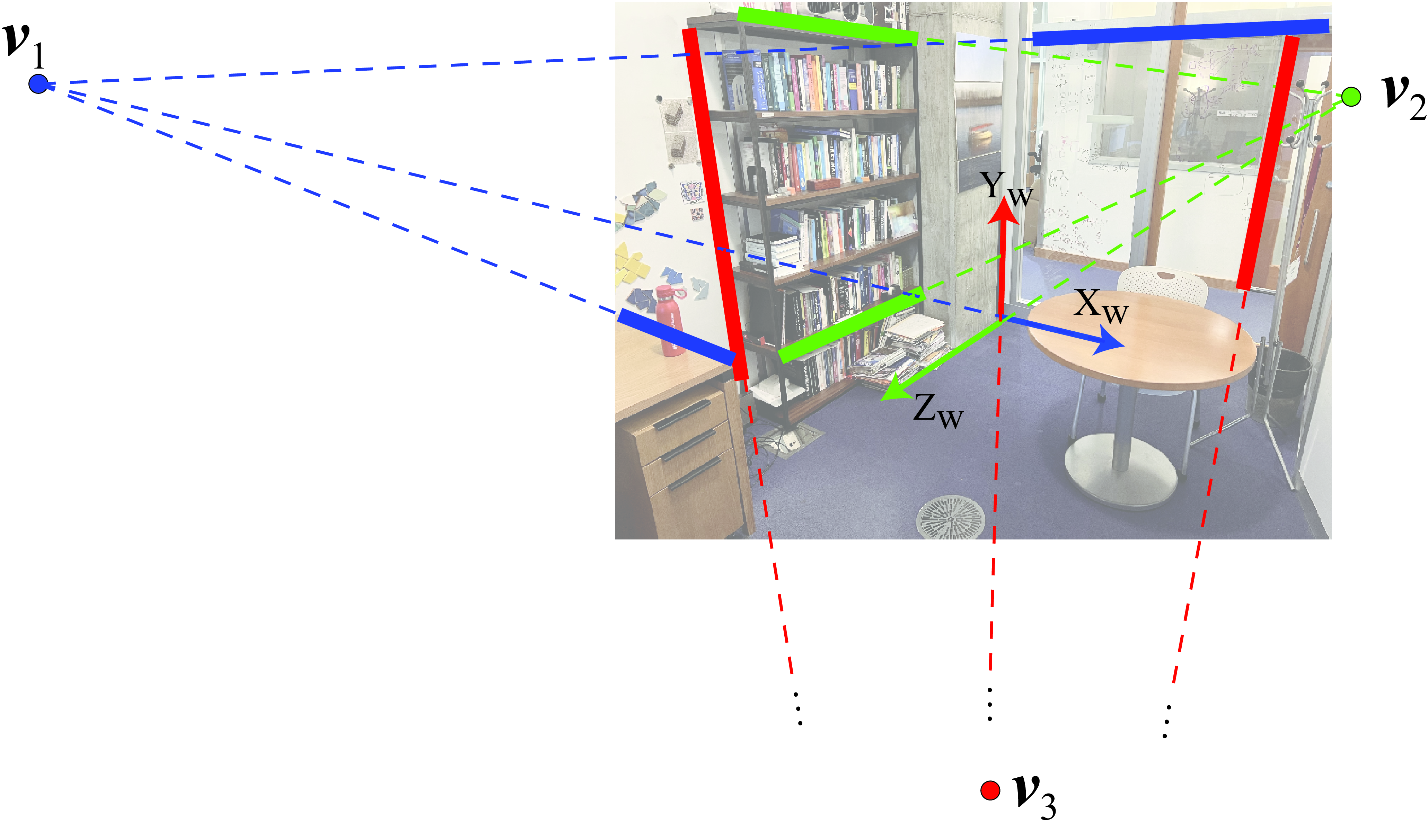
Figure 42.10 shows the office scene and three vanishing points computed manually. In this scene there are three dominant orientations along orthogonal directions. The three vanishing points are estimated by selecting pairs of long edges in the image corresponding to parallel 3D lines in the scene and finding their intersection.
Vanishing points can be extracted automatically from images by first detecting image edges and their orientations (like we did in chapter Chapter 2) and then using RANSAC (Section 41.3.2) to group the edges: every pair of edges will vote for a vanishing point and the point with the largest support will be considered a vanishing point.
There are also learning-based approaches for vanishing point detection using graphical models [4], or deep learning based approaches such as DeepVP [5] and NeurVPS [6].
42.4 Measuring Heights Using Parallel Lines
Let’s now use what we have seen up to now to measurement distances in the world from a single image. We will discuss in this section how to make those measurements using three vanishing points, or just the horizon line and one vanishing point. We will not use camera calibration or the projection matrix. For a deeper analysis we refer the reader to the wonderful thesis of A. Criminisi [7].
Before we can make any 3D measurements we need to study an important invariant of perspective projection: the cross-ratio.
42.4.1 Cross-Ratio
As we have discussed before, perspective projection transforms many aspects of the 3D world when projecting into the 2D image: angles between lines are not preserved, the relative lengths between lines is not preserved, parallel 3D lines do not project into 2D parallel lines in the image (unless they are also parallel to the camera plane), and so on. Fortunately, some geometric properties are preserved under perspective projection. For instance, straight lines remain straight. Are there other quantities that are preserved? The cross-ratio is one of those quantities.
The cross-ratio of four collinear points is defined by the expression: \[CR \left( \mathbf{P}_1,\mathbf{P}_2,\mathbf{P}_3,\mathbf{P}_4 \right) = \frac{\left| \mathbf{P}_3 -\mathbf{P}_1 \right| \left|\mathbf{P}_4 -\mathbf{P}_2 \right|} {\left| \mathbf{P}_3 -\mathbf{P}_2 \right| \left|\mathbf{P}_4 -\mathbf{P}_1 \right|}\] where \(\left| \mathbf{P}_i -\mathbf{P}_j \right|\) is the euclidean distance between points \(\mathbf{P}_i\) and \(\mathbf{P}_j\), using heterogeneous coordinates.
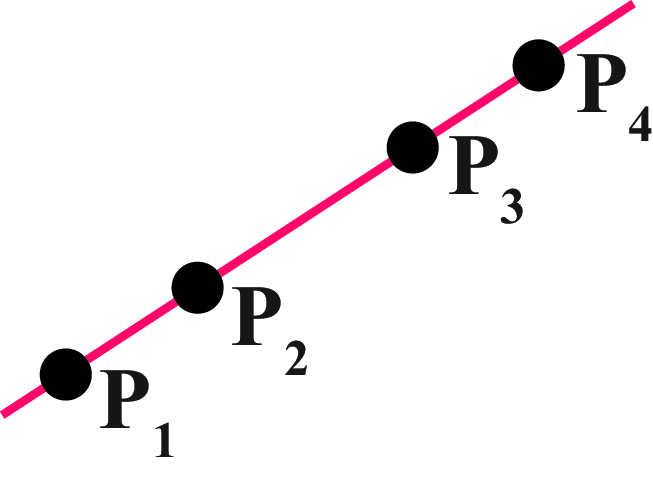
The cross-ratio is considered the most important projective invariant. Two sets of points \(\mathbf{P}\) and \(\mathbf{Q}\) related by a projective transformation, as shown in Figure 42.11, have the same cross-ratio (regardless of the choice of origin \(\mathbf{O}\) or scale factor). That is: \[CR(\mathbf{P}_1,\mathbf{P}_2,\mathbf{P}_3,\mathbf{P}_4) = CR(\mathbf{Q}_1,\mathbf{Q}_2,\mathbf{Q}_3,\mathbf{Q}_4)\]
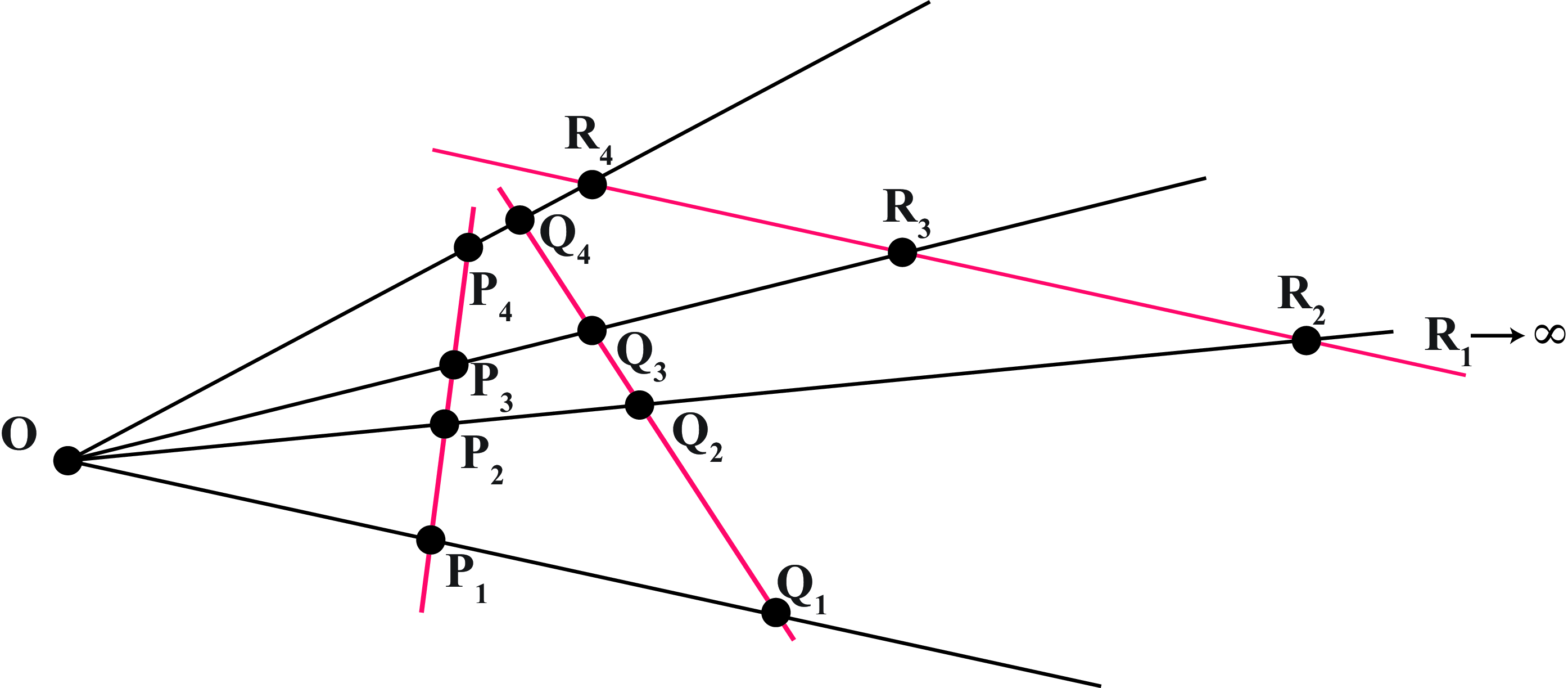
The order in which these points are considered matters in the calculation. There are \(4!=24\) possible orderings resulting in six different values. If two sets of points, related by a projection, have the same ordering, then their cross ratio will be preserved. We do not provide the proof for the cross-ratio invariant here.
When one of the points is at infinity, all the terms that contain that point are cancelled out (this can also be seen by taking a limit). In the case of the points \(\mathbf{R}\) from Figure 42.11 we get that cross-ratio is: \[CR(\mathbf{R}_1,\mathbf{R}_2,\mathbf{R}_3,\mathbf{R}_4) = \frac{\left| \mathbf{R}_4 -\mathbf{R}_2 \right| } { \left| \mathbf{R}_3 -\mathbf{R}_2 \right|}\] This value is equal to the cross-ratio of the points \(\mathbf{P}\) and \(\mathbf{Q}\).
To gain some intuition about the cross-ratio invariant, let’s look at an empirical demonstration. Figure 42.12 shows a ruler seen under different view points. The blue dots correspond to same ruler locations with \(P_1=0\) in, \(P_2=6\) in, \(P_3=8\) in, and \(P_4=10\) in (we are making these measurements in inches, but note that the units do not affect the cross-ratio as it is scale invariant). Using those measurements, the cross-ratio is: \((8 \times 4)/(2 \times 10) = 1.6\). The same cross-ratio is obtained if we measure the positions of the four points using image coordinates and measuring distances in the image plane.

42.4.2 Measuring the Height of an Object
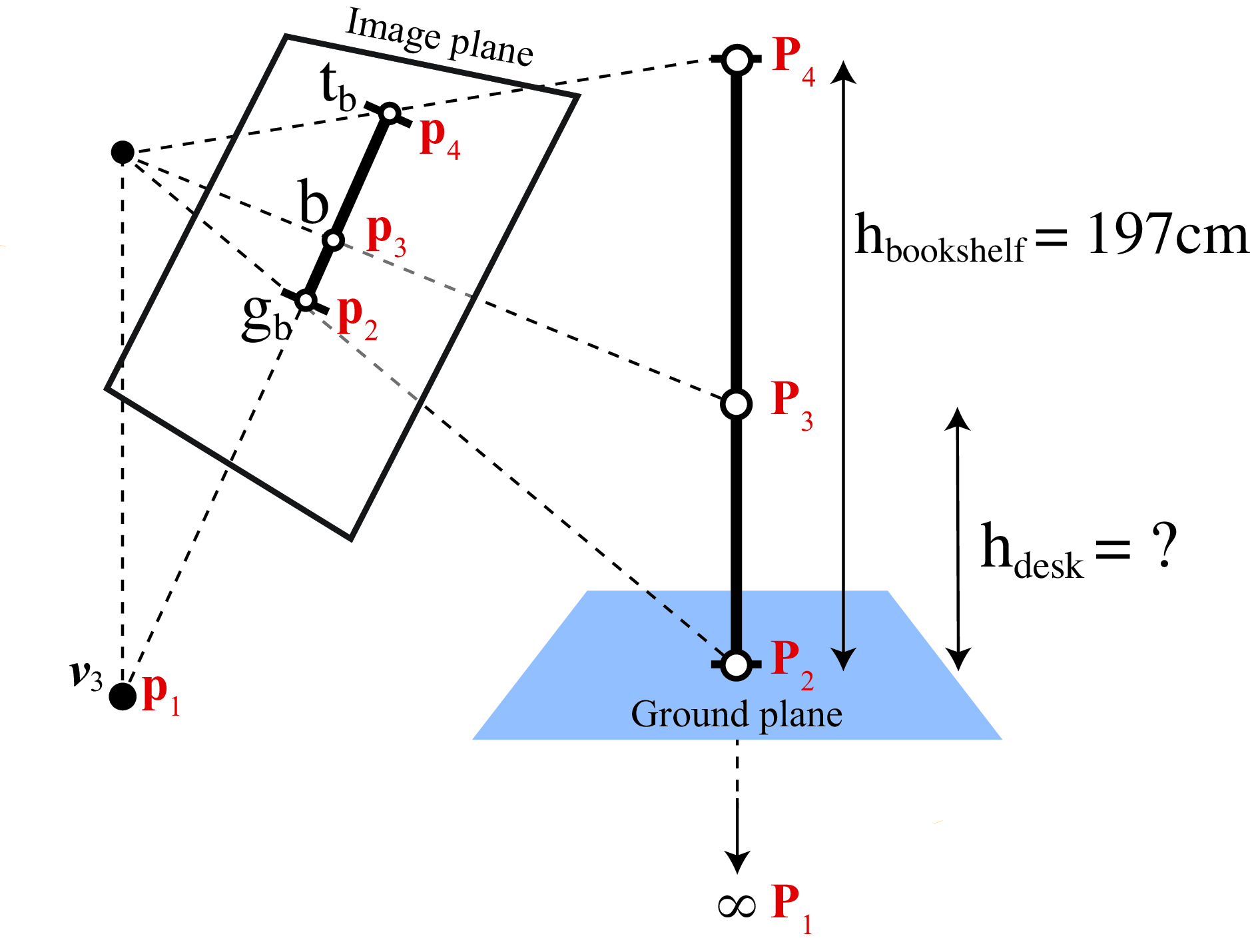
The problem we will address in this section is how to measure the height of one object given the height of a reference object in the scene. As shown in Figure 42.13, the height of the bookshelf is \(h_{\text{bookshelf}}=197\) cm (in this example we will make our measurements using centimeters, but again, the choice of units is not important as long as all the measurements are consistent). Can we use this information together with the geometry of the scene to estimate the height of the desk, \(h_{\text{desk}}\)?

Due to perspective projection, we can not directly compare the relative height of the desk with respect to the height of the bookshelf using distances measured over the image. In order to be able to compare 3D distances using 2D image distances both objects need to be put in correspondence first. The bookshelf height is the distance between the 3D points that correspond to the 2D locations of the bottom of the bookshelf, \(\mathbf{g}_b\), and the top of the bookshelf, \(\mathbf{t}_b\). Similarly, the desk height is the distance between the 3D points that correspond to \(\mathbf{g}_d\) and \(\mathbf{t}_d\). We can not use directly the points \(\mathbf{g}_b\) and \(\mathbf{t}_b\), and \(\mathbf{g}_d\) and \(\mathbf{t}_d\) as they are given in image coordinates. In order to be able to use distances in the image domain we need to first translate the points defining the desk height on top of the bookshelf, and then use the cross-ratio invariant to relate the ratio between image distances with the ratios of 3D heights.
In the rest, all the vectors refer to image coordinates in homogeneous coordinates. Let’s start by projecting the desk height onto the bookshelf. To do this we need to follow several steps:
Estimate the line that passes by the ground points \(\mathbf{g}_d\) and \(\mathbf{g}_b\). Using homogeneous coordinates, the line can be computed using the cross-product: \[\boldsymbol{l}_1 = \mathbf{g}_d \times \mathbf{g}_b\]
Compute the intersection of the line \(\boldsymbol{l}_1\) with the horizon line \(\mathbf{h}\) as: \[\mathbf{a} = \boldsymbol{l}_1 \times \mathbf{h}\] As the line \(\boldsymbol{l}_1\) is on the ground plane, the point \(\mathbf{a}\) is the vanishing point of line \(\boldsymbol{l}_1\).
Compute the line that passes by \(\mathbf{a}\) and the top of the desk \(\mathbf{t}_d\) as: \[\boldsymbol{l}_2 = \mathbf{a} \times \mathbf{t}_d\] Lines \(\boldsymbol{l}_1\) and \(\boldsymbol{l}_2\) are parallel on 3D and vertically aligned.
Finally we can compute where line \(\boldsymbol{l}_2\) intersects with the bookshelf in the image plane which in this case will also correspond to an intersection of the corresponding 3D lines. We first compute the line that connects the bottom and top points of the bookshelf \(\boldsymbol{l}_3 = \mathbf{g}_b \times \mathbf{t}_b\), and now we obtain the intersection with \(\boldsymbol{l}_2\) as: \[\mathbf{b} = \boldsymbol{l}_2 \times \boldsymbol{l}_3\]
We can write all the previous steps into a single equation: \[\mathbf{b} = (((\mathbf{g}_d \times \mathbf{g}_b) \times \mathbf{h}) \times \mathbf{t}_d) \times (\mathbf{g}_b \times \mathbf{t}_b)\] Point \(\mathbf{b}\) is the location where the top of the desk will be if we physically rearrange the furniture to bring the desk and the bookshelf into contact. The segment between points \(\mathbf{b}\) and \(\mathbf{g}_b\) is the projection of the desk height on the bookshelf. However, due to the foreshortening effect induced by perspective projection, we cannot simply rely on the ratio of image distances to estimate the desk’s true height. Instead, we will utilize the cross-ratio invariant to make this estimation.
As J. J. Gibson pointed out, the ground plane is very useful for all kinds of 3D scene measurements.
In order to use the cross-ratio invariant we need two sets of four colinear points related by a projective geometry. Figure 42.15 shows a sketch of the setup we have in Figure 42.14.
In the image plane, we have the four image points \(\mathbf{t}_b\), \(\mathbf{b}\), \(\mathbf{g}_b\) and \(\mathbf{v}_3\). Those four 2D image points correspond to the 3D locations given by the top of the bookshelf, desk height, ground and infinity (which is the location of the vertical vanishing point in 3D).
The rest of calculations requires computing distances between points, which only works when using heterogeneous coordinates (or homogeneous coordinates if the last component is equal to 1 for all points). The cross-ratio invariant between both sets of four points gives as the equality:
\[CR(\mathbf{P}_1,\mathbf{P}_2,\mathbf{P}_3,\mathbf{P}_4) = CR(\mathbf{p}_1,\mathbf{p}_2,\mathbf{p}_3,\mathbf{p}_4) \tag{42.6}\]
The left side of the equality corresponds to the distances between the 3D points and the right side to the distances of the image points measured in pixel units. As \(\mathbf{P}_1\) is in infinity (as it corresponds to the vanishing point), the left side ratio only has two terms, resulting in the ratio between the bookshelf and desk heights. To compute the hand side we need the coordinates of the corresponding four image points. Those are provided in Figure 42.14. Replacing all those values in equation (Equation 42.6) we obtain:
\[\frac{h_{\text{bookshelf}}}{h_{\text{desk}}} = \frac{\left| \mathbf{b} - \mathbf{v}_3 \right| \left| \mathbf{t}_b - \mathbf{g}_b \right| }{\left| \mathbf{b} - \mathbf{g}_b \right| \left| \mathbf{t}_b - \mathbf{v}_3 \right|}\]
The only unknown value in this equality is the height of the desk, \(h_{\text{desk}}\), which results in \(h_{\text{desk}} \simeq 73.1\) cm, which is close to the actual height of the desk (which is around 76 cm).
Projective invariants are measures that do not change after perspective projection. The cross-ratio is the most important projective invariant.
42.4.3 Height Propagation to Supported Objects
The method described in the previous section relies on using vertical lines in contact with the ground plane to propagate information from one point in space to another in order to make measurements. The method can not work if we can not establish the vertical projection of a point into the ground plane (or any other plane of reference). But once we have estimated the height of objects that are in contact with the ground, we can use them to propagate 3D information to other objects not directly on top of the ground. We can estimate the height of objects that are not in contact with the ground if they are on top of objects of known height. As an example, let’s estimate the red bottle’s height, which we can do after we estimated the height of the desk.
Figure 42.16 shows how to estimate the height of the bottle.
As before, we will project the bottle height on the reference line on the corner of the bookshelf. To do this we need to find two vertically aligned parallel 3D lines that connect the bottle’s top and bottom points with the bookshelf. The first line, \(\boldsymbol{l}_1\), is the line connecting the bottom of the bottle, \(\mathbf{g}_e\), and the point \(\mathbf{b}\). These two points are at the same height from the ground plane as \(\mathbf{b}\) corresponds to the top of the desk and \(\mathbf{g}_e\) is the point of the bottle that is in contact with the top of the desk. The intersection of the line \(\boldsymbol{l}_1\) with the horizon line \(\mathbf{h}\) give us point \(\mathbf{a}\). Connecting point \(\mathbf{a}\) with the top of the bottle, point \(\mathbf{t}_e\), gives us the second line, \(\boldsymbol{l}_2\). The intersection of this line with the reference bookshelf line is the point \(\mathbf{c}\). The distance between the point \(\mathbf{c}\) and the ground in 3D is the sum \(h_{\text{bookshelf}}+h_{\text{desk}}\). Writing everything into a compact equation results in: \[\mathbf{c} = (((\mathbf{g}_e \times \mathbf{b}) \times \mathbf{h}) \times \mathbf{t}_e) \times (\mathbf{g}_b \times \mathbf{t}_b)\] Note that this equation relies on having computed \(\mathbf{b}\) first.
Using the cross-ratio invariant we arrive to the following equation: \[h_{\text{bottle}} = h_{\text{bookshelf}} \frac{\left| \mathbf{c} - \mathbf{g}_b \right| \left| \mathbf{t}_b - \mathbf{v}_3 \right|}{\left| \mathbf{c} - \mathbf{v}_3 \right| \left| \mathbf{t}_b - \mathbf{g}_b \right| } - h_{\text{desk}}\] This last equation shows how the height of the bottle is estimated by propagating information from the ground via its supporting object, the desk. Learning based approaches that estimated 3D from single images will have to perform such propagation implicitly. The result that we get is \(h_{\text{bottle}} \simeq 27.6\) cm which is close to the real height of 25.5 cm.
This procedure highlights the importance of the correct parsing of the supported-by hierarchy between objects in the scene.
42.5 3D Metrology from a Single View
In the previous section we showed how to use a reference object to measure other objects. Let’s now discuss a more general framework to locate 3D points [7].
The office picture from Figure 42.17 shows the projection of the 3D coordinates frame into the image plane. The axes directions are aligned with the three dominant orthogonal orientations present in the scene and are aligned with the image vanishing points. We will show how can we use the world-coordinates in order to extract 3D object locations from a single image.
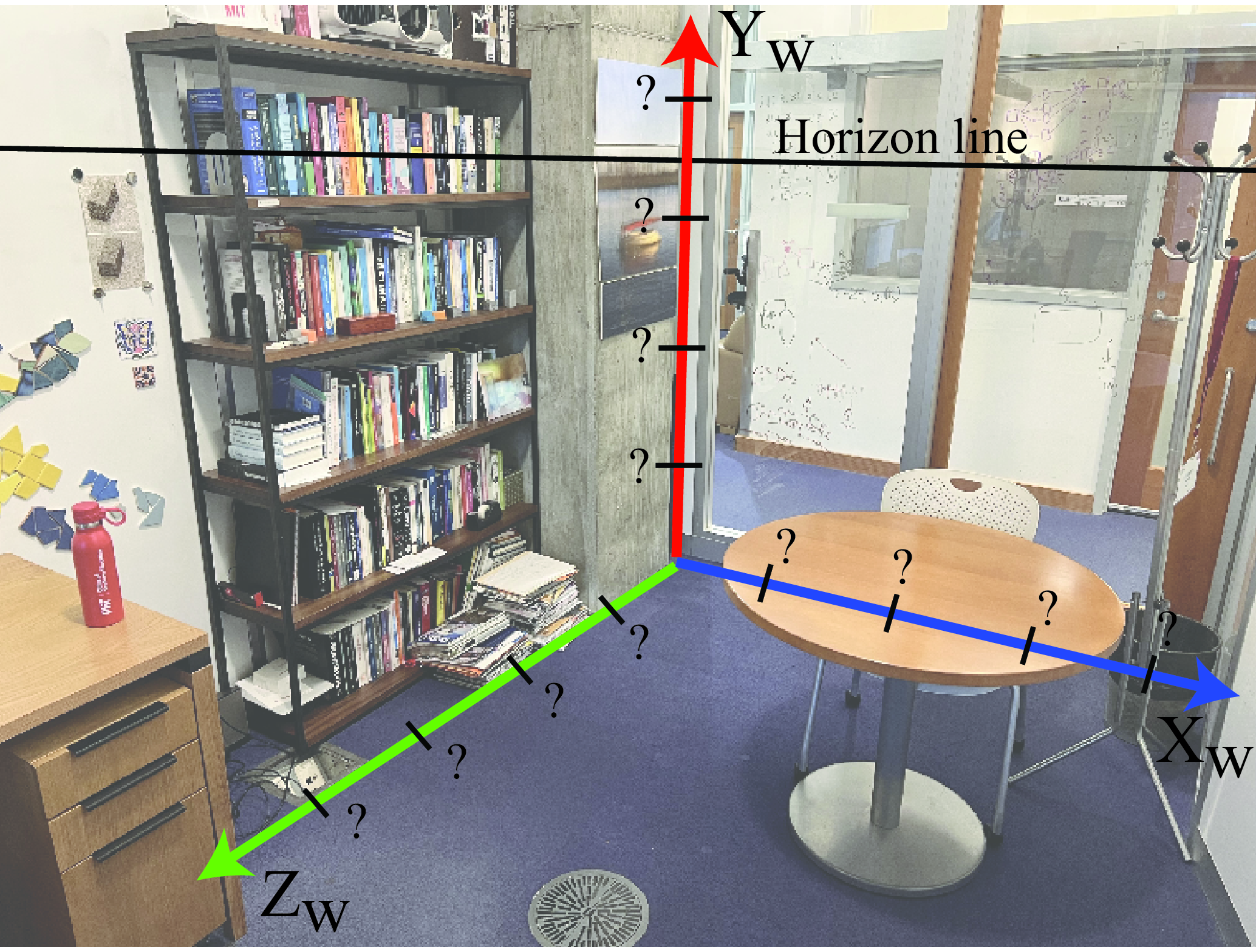
In this section we will describe first how to calibrate the projected world-coordinate axes in the image plane and then we will show how to transport points into the 3D world axes in order to measure object sizes and points locations.
42.5.1 Calibration of the Projected World Axis
Where should we position the tick marks that correspond to 1, 2, 3, ... meters from the origin on each axis in Figure 42.17? Simply placing them at evenly spaced intervals along the axis in the image won’t be correct. Due to geometric distortion introduced by perspective projection, the tick marks are not evenly spaced within the image plane. This distortion affects each axis in a distinct manner.
Let’s start assuming we know the location of some arbitrary 3D distance to the origin on each axis that we will denote by \(\alpha_X\), \(\alpha_Y\) and \(\alpha_Z\). The question is, where do we place the ticks for \(k\alpha_X\), \(k\alpha_Y\) and \(k\alpha_Z\) for all \(k\)? We will use the cross-ratio to calibrate the projection of the world coordinate system in the image plane. For doing this we will need the location of the horizon line of a reference plane (i.e. the ground plane), the position of the orthogonal vanishing point and the real measure of one object in the scene.
As shown in Figure 42.18 (a) we can use the cross-ratio to estimate the location of the points \(Y= k \alpha_X\) where \(\alpha_X\) is an arbitrary constant as shown in Figure 42.18 (b), and the corresponding image location \(r\), for \(k=1\), is chosen arbitrarily as shown in Figure 42.18 (a). Due to perspective projection, the image projection of the point \(Y= k \alpha_X\) will not be evenly spaced in the image. In this particular example we chose the orientation of the world axis in image coordinates to be aligned with the location of the vanishing points.
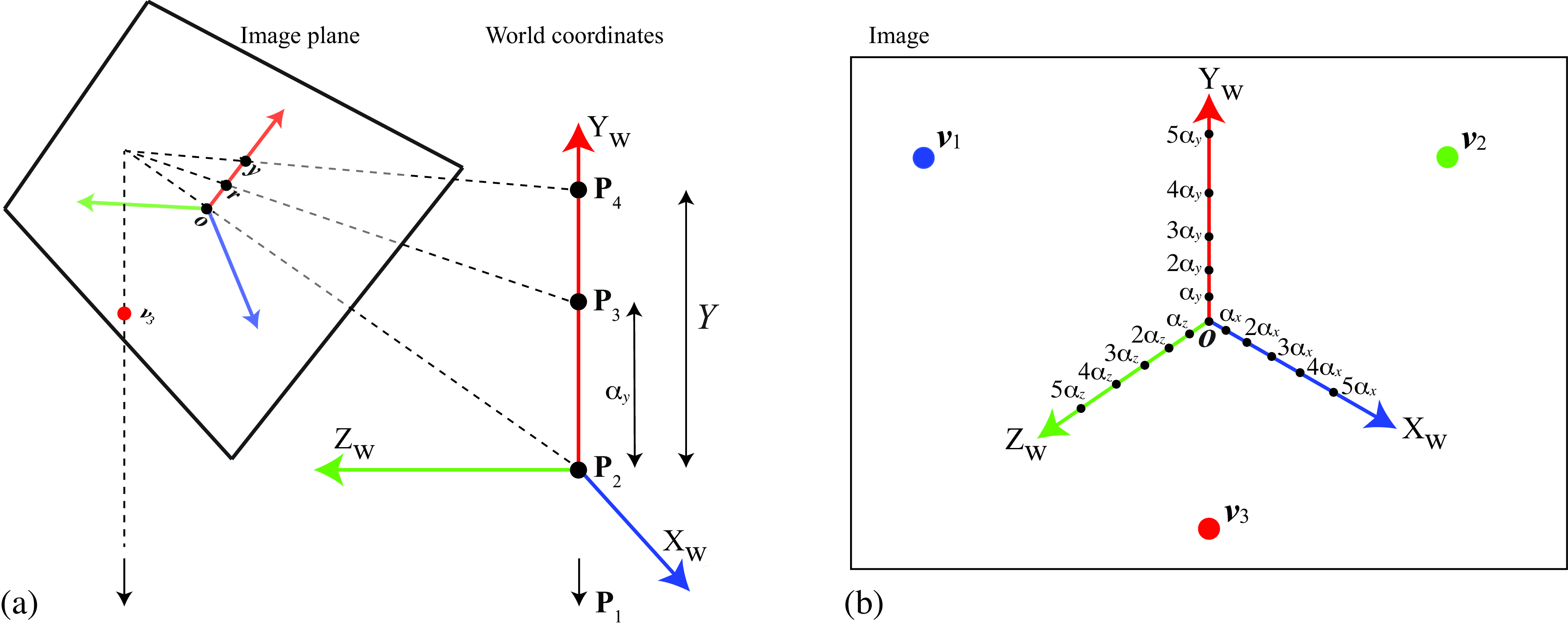
In order to calibrate the axis we need to know the dimensions of an object in the scene. We need measurements along the three axis. In this example, we used the bookshelf height (197 cm) and the radius of the table base (50 cm). Using these reference measurements we can solve for the image locations of the ticks \(\alpha_X=\alpha_Y=\alpha_Z=1\) m.
Figure 42.19 shows the final calibrated axes with ticks placed each 50 cm along each of the three axes.

From this calibrated system we can directly read the height of the camera. The location of the camera coincides with the location of the horizon line because, in this example, the ground plane is horizontal. It seems that the center of the camera is approximately 163 cm above the ground.
There are many ways in which we can arrive to the same result.
42.5.2 Locating a 3D Point
In the absence of any other information, we can not recover the 3D location of a single point \(\mathbf{P}\) from a single view as illustrated in Figure 42.20 [a]. But real world scenes are composed by a multitude of objects providing context, which allows solving the 3D estimation problem even with just a single image. In the previous section we showed how to estimate the height of an object, here we show how to estimated the 3D coordinates of a point.
The basic procedure is illustrated in Figure 42.20 [b]. The trick consists in using context (what object is the point part of, where is the horizon line of the scene and where are the vanishing points) to estimate 3D from a single image. It suffices to know that the point \(\mathbf{P}\) belongs to an object that is in contact with the ground and the geometry of this object provides the information to localize the projection of the point \(\mathbf{P}\) on the ground plane, which we denote with \(\mathbf{G}\).
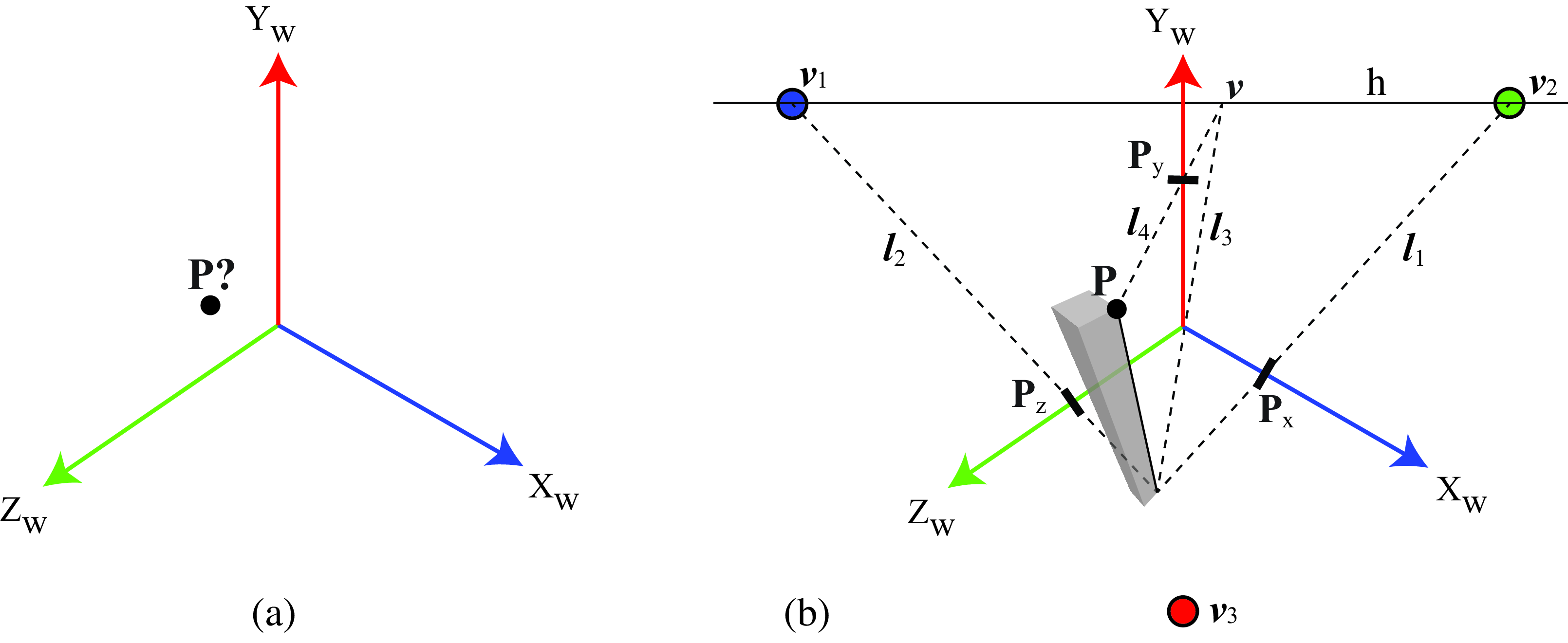
Once we know the image location of the projection of the 3D point \(\mathbf{P}\) to the ground, \(\mathbf{G}\), we can project this point to the world-coordinate axis. To estimate the \(Y\)-coordinate we use a similar method as the one described in the previous section. We first find the line, \(\boldsymbol{l}_3\), that passes by the point \(\mathbf{G}\) and the origin, and then find the intersection with the horizon line, giving the point \(\mathbf{v}\). Next, find the line, \(\boldsymbol{l}_4\), that passes by \(\mathbf{v}\) and \(\mathbf{P}\). The intersection of \(\boldsymbol{l}_4\) with the \(Y_w\)-axis gives the coordinate \(P_y\). The \(P_x\) and \(P_z\) coordinates can be obtained by connecting \(\mathbf{G}\) with the vanishing points \(\mathbf{v}_1\) and \(\mathbf{v}_2\).
Here we have been using the ground plane as a reference. But the same idea can be applied if we know the projection of the point \(\mathbf{P}\) into another plane with a known horizon line.
In summary, we can recover the location of the 3D point from a single image by propagating information from the calibrated world-coordinate axis using the vanishing points that are aligned with the axis.
42.6 Camera Calibration from Vanishing Points
In the previous chapters, we have seen different methods to calibrate a camera. We saw that we could do it by taking pictures of a calibration pattern, and we also showed that we can extract both the intrinsics and extrinsics from a set of 3D points and their image correspondences. Here we will see a different method that uses only the vanishing points to extract the camera parameters; note that this method will only work under some conditions.
The first step consists in finding the vanishing points in the image. Let’s use the office picture from Figure 42.10. In this particular scene there are many parallel lines in 3D, and they also happen to be parallel to the three directions we used to define the world coordinates system. Therefore, the three vanishing points are also aligned with the world coordinate axis.
Let’s assume that we have three orthogonal vanishing directions. That is the vectors \(\mathbf{D}_1\), \(\mathbf{D}_2\), and \(\mathbf{D}_3\) are orthogonal in 3D. From equation (Equation 42.5), the vanishing points measured on the image are the result of projecting \(\mathbf{D}_1\), \(\mathbf{D}_2\), and \(\mathbf{D}_3\) into the image using the unknown camera projection matrix. We will use the vanishing points to derive a set of constraints on the projection matrix. To do this, we start by inverting equation (Equation 42.5): \[\mathbf{D}_i = \mathbf{R}^{-1} \mathbf{K}^{-1} \mathbf{v}_i \tag{42.7}\] Because the vectors \(\mathbf{D}_i\) are orthogonal, we have that \(\mathbf{D}_i^{\mathsf{T}} \mathbf{D}_j = 0\) for \(i \neq j\). Therefore, we can write: \[\mathbf{D}_i^\mathsf{T}\mathbf{D}_j = \mathbf{v}_i^\mathsf{T}\mathbf{K}^{-\mathsf{T}} \mathbf{R}^{-\mathsf{T}} \mathbf{R}^{-1} \mathbf{K}^{-1} \mathbf{v}_j \tag{42.8}\] As \(\mathbf{R}\) is an orthonormal matrix, we have that \(\mathbf{R}^{-\mathsf{T}} \mathbf{R}^{-1} = \mathbf{I}\), resulting in a relationship that only depends on the intrinsic camera parameters \(\mathbf{K}\): \[\mathbf{D}_i^T \mathbf{D}_j = \mathbf{v}_i^\mathsf{T}\mathbf{K}^{-\mathsf{T}} \mathbf{K}^{-1} \mathbf{v}_j = 0 \tag{42.9}\]
It is useful to define the following matrix: \[\mathbf{W} = \mathbf{K}^{-\mathsf{T}} \mathbf{K}^{-1}\] This is also known as the conic matrix and it has lots of different properties [1].
If we assume that the skew parameter of the intrinsic camera matrix is zero, then the matrix \(\mathbf{W}\) has a very particular structure and it has only four different values: \[\mathbf{W} = \begin{bmatrix} a & 0 & b\\ 0 & a & c\\ b & c & d \end{bmatrix}\] Using equation (Equation 42.9), we can derive a linear constraint on the values \(a,b,c,d\) for each pair of vanishing points. Defining the vector \(\mathbf{w}=[a~b~c~d]^\mathsf{T}\), we can rewrite equation (Equation 42.9) into a system of linear equations that has the form: \[\mathbf{A} \mathbf{w} = 0\]
The linear equation can be solved with the singular value decomposition (SVD) and the result is the eigenvector with the smallest eigenvalue.
Once we have \(\mathbf{W}\), we can find \(\mathbf{K}\) by using the Cholesky factorization, which decomposes a matrix as the product of an upper triangular matrix and its transpose. The last step is to normalize the result by normalizing all the matrix values so that the value on the bottom-right side is 1. In our running example of the office picture, we get the following solution for \(\mathbf{K}\):
\[ \mathbf{K} = \begin{bmatrix} 3{,}054.6 & 0 & 1{,}999.4\\ 0 & 3{,}054.6 & 1{,}528.3\\ 0 & 0 & 1 \end{bmatrix} \]
We can now compare this result with the one we obtained when we (1) used the physical camera parameters Section 39.3.3; (2) used a calibration pattern Section 39.3.3; and (3) used a collection of 3D points and the corresponding image locations Section 39.7.5. We can see that in all cases we get similar results, although, not identical.
42.7 Concluding Remarks
In this chapter we have shown how to use geometric image features (vanishing points, horizon line) and projective invariants (such as the cross-ratio) to estimate 3D scene properties from a single image. However, most of the steps required some manual intervention. All of those steps can be performed in a fully automatic way by training detectors to localize the full extend of an object as we will discuss in Chapter 50 and detecting points of contact between objects.
One of the key insights from this chapter is that a single images contain a lot of information that, in most cases, is enough to estimate metric 3D information from a single 2D image. In the next chapter we will discuss learning-based methods for 3D estimation from images.