28 Textures
28.1 Introduction
The visual world is made of objects (chairs, cars, tables), surfaces (walls, floor, ceiling), and stuff (wood, grass, water). This chapter is about seeing stuff [1]. How do we build image representations that can capture what makes wood different from a wall of bricks?
Representing textures is a task, similar to color perception, that is intimately related to human perception. A texture is a type of image that is composed by a set of similar looking elements. A texture representation contains information about the statistics of its constituent elements, but not about the elements individually.
In this chapter we will introduce the problems of texture analysis and synthesis as a way to explore texture representations. The models presented here are precursors of more modern approaches using deep learning. But many of the concepts, and some of the intuitions about why these models might be successful, are better understood by exploring first simple yet powerful models.
Texture synthesis can be solved by a trivial algorithm as shown in Figure 28.1. But such an algorithm, although successful in practice, will give us little understanding on how human perception works and how to modify textures to create new ones. It will also not help us in understanding what representation can be useful to measure similarity between textures.

Before we dive into computational approaches to texture analysis, let’s first build some intuitions about what might be plausible representations by looking into human perception.
28.2 A Few Notes about Human Perception
The study of texture perception is a large field in visual psychophysics and we will not try to review it here in detail. Instead, we will just describe three visual phenomena that will allow you getting a sense of the mechanisms underlying texture perception by your own visual system.
How many stones there are in this wall?  Most people will not care about the number of rocks in the wall, unless you are in the business of selling rocks. Most observers perceive this image as a rock texture. It appears to observers as a texture instead of a composition of countable rocks. They are indeed countable, but counting them requires a significant effort.
Most people will not care about the number of rocks in the wall, unless you are in the business of selling rocks. Most observers perceive this image as a rock texture. It appears to observers as a texture instead of a composition of countable rocks. They are indeed countable, but counting them requires a significant effort.
28.2.1 Perception of Sets
When an image is composed of one or a few distinct objects, we can easily pay attention to each of them individually. We can also count them in parallel, that is, we can tell if an image has one, two, three, or four elements, very quickly and the time it takes for us to say how many elements are in the display does not depend on the number of elements in the image. That is, if a display has only one element or four elements, we are equally fast at reporting that number (figures Figure 28.2[a, b and c]).
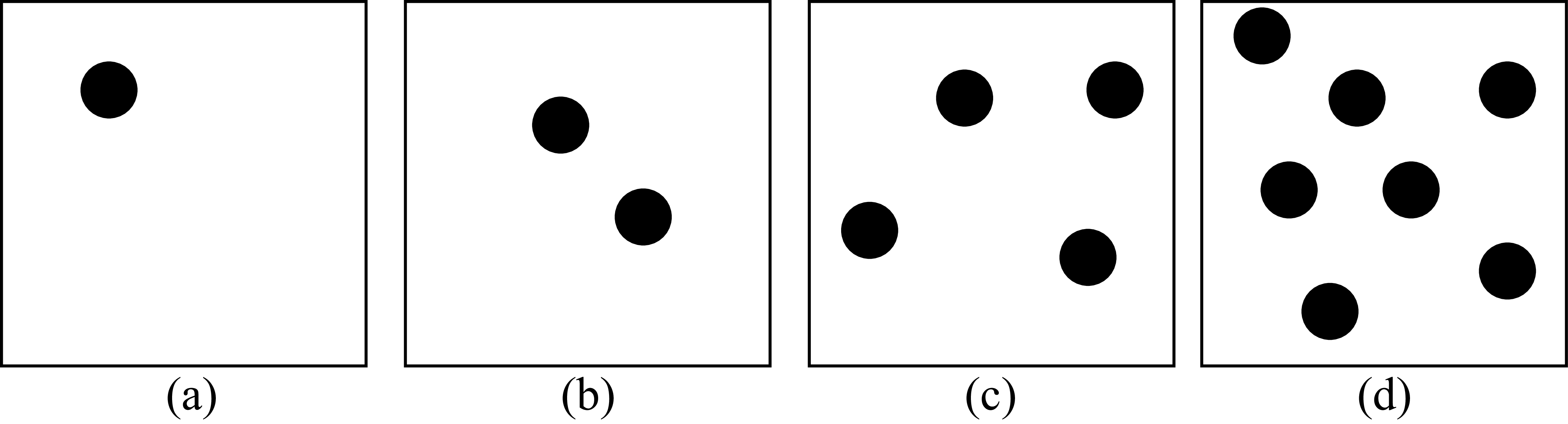
But something interesting happens when images are composed of more than five similarly looking elements. If we want to count them we need to look at all of them one by one, and the time to count them grows linearly with the number of elements in the image, as illustrated in Figure 28.2.
The ability to know how many objects are in a display without counting them is called subitizing [2]. Subitizing only works when there are fewer than five elements in a display.
When there are more than four or five objects, we seem to pay attention only to a few of them and represent the rest of them as a set. The perception of sets is an important area of study in human visual psychophysics [3].
28.2.2 Crowding
Figure 28.3 illustrates a curious visual phenomenon. Look at the central cross and try to read the letter on the left and right without moving your eyes.
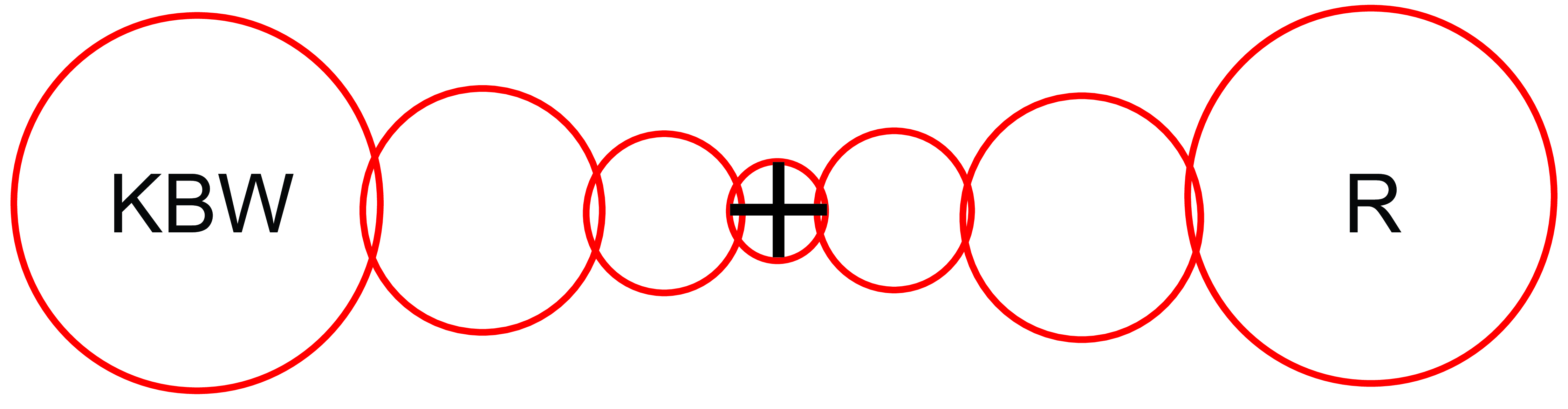
You will notice that the letter R on the right can be recognized easily while the letter B on the left is hard to read. The reason cannot be due to the low resolution of peripheral vision as both letters are at the same distance from the fixation location. The explanation of this phenomena is due to something called crowding [4].
As the letter B is surrounded by other letters, the features of the three letters get entangled as if the pooling window for image features was larger than the three letters together. While you fixate the cross, as you pay attention to the location of the B, you will notice that the features of the three letters are mixed. It is easy to see that it is text, but it is hard to bind the features together to perceive the individual letters. The circles in Figure 28.3 represent an approximation of the size of the visual regions over which visual features are pooled. Anything inside the region will suffer from crowding effects. Those regions are larger than what would be predicted by the loss of resolution due to the spacing between receptors in the periphery.
The main message here is for you to feel what it is to perceive what seems to be a statistical representation of the image features present in an image region.
28.2.3 Pre-Attentive Texture Discrimination
One of the first computational models of texture perception was due to Bela Julesz [5]. He proposed that textures are analyzed in terms of statistical relationships between fundamental texture elements that he called textons. It generally required a human to look at the texture in order to decide what those fundamental units were and his models were restricted to binary images formed by simple elements as shown in Figure 28.4.

One interesting observation about Figure 28.4 is that it seems easy to see the boundary between the two textures in the image. Interestingly, not all textures can be easily discriminated pre-attentively (i.e., without making an effort). Bela Julesz and many others studied what makes two textures look similar or different in order to understand the nature of the visual representation used by the human visual system.
According to Bela Julesz, textons might be represented by features such as the number of junctions, terminators, corners, and intersections within the patterns. The challenge is that detecting those elements can be unreliable making the representation non-robust.
A different texture representation based on filter banks was introduced in parallel by Bergen and Adelson [6], and by Malik and Perona [7]. They showed that filters were capable of explaining several of the pre-attentive texture discrimination results, and that features based on filter outputs could be used to do texture-based image segmentation [7]. The texture model we will study in the next section is motivated by those works.
In the rest of this chapter we will study two texture analysis and synthesis approaches.
28.3 Heeger-Bergen Texture Analysis and Synthesis
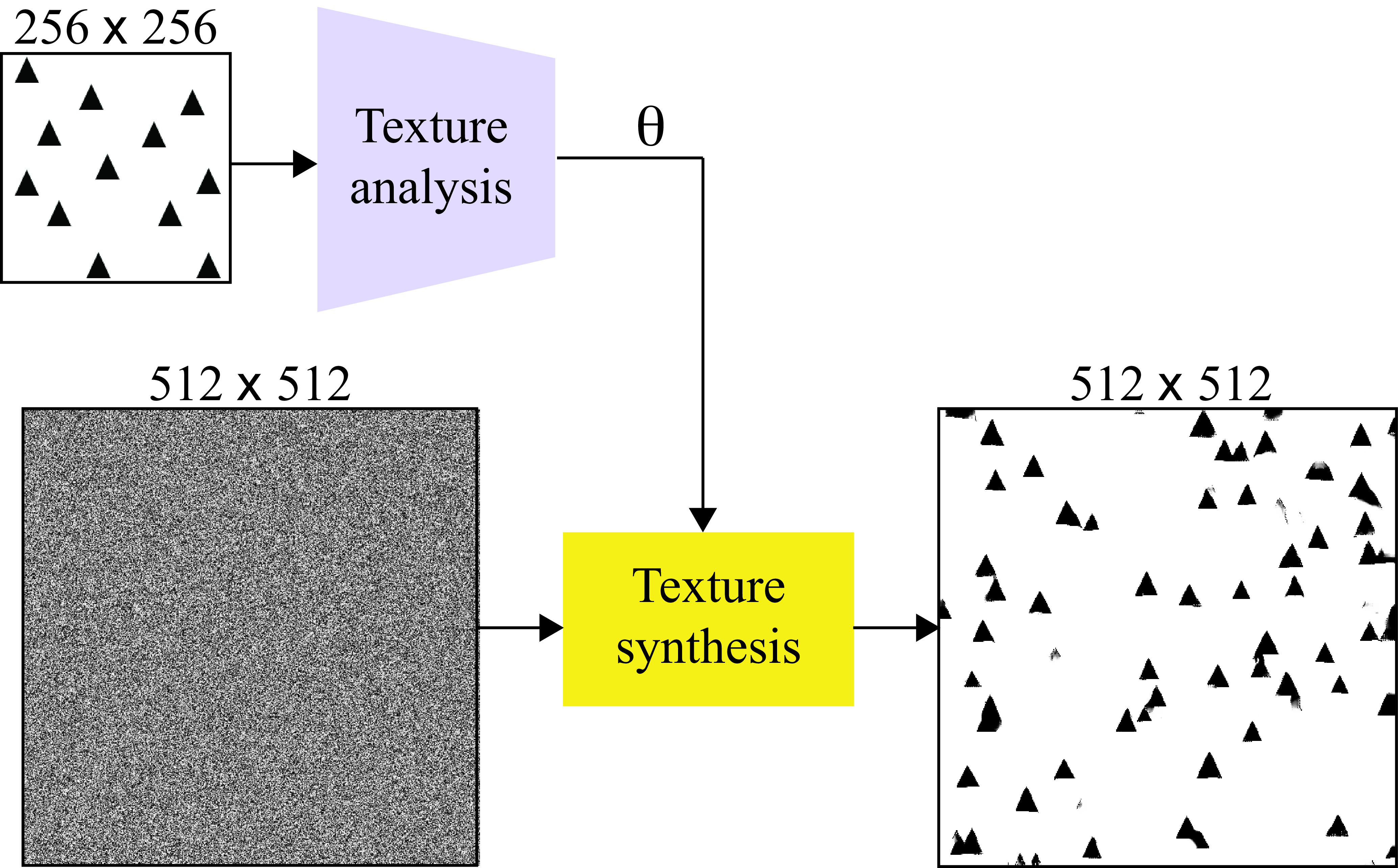
The statistical characteristics of image subbands allow for powerful image synthesis and also denoising algorithms. Let’s start with the problem of texture synthesis. The task is as follows: given a reference texture we want to build a process that outputs images with new random samples of the same texture, as shown in Figure 28.5.
A demo of the content in this section.
Texture synthesis is important for many computer graphics applications, and also as way of studying what representations of a texture can be useful for visual recognition.
An influential wavelet-based image synthesis algorithm is the Heeger-Bergen texture synthesis method published in 1995, with the following origin story [8]: David Heeger heard Jim Bergen give a talk at a human vision conference about representations for image texture. Bergen highlighted the value of measuring the mean-squared responses of filters applied to images for characterizing texture. He suggested that determining the full probability distribution of each filter’s responses would be even more effective. He conjectured that if two textures produced the same distribution of filter responses for all filters, they would look identical to a human observer. Heeger disagreed and aimed to prove Bergen wrong by implementing the proposal using a steerable pyramid [9]. To Heeger’s surprise, the first example he tried worked very well, and this led to Heeger and Bergen’s influential paper on texture synthesis [10].
Texture generation has two stages depicted in Figure 28.5. Texture analysis of a reference texture extracts a texture representation, \(\theta\). Texture synthesis uses a representation, \(\theta\), to generate new random samples of the same texture. In the case of texture, it is difficult to precisely define what we mean by “same texture.” The perception of textures is an important topic in studies of visual human perception. In general, two textures will be perceived as similar when they seem to be generated by the same physical process.
An important research question is as follows: what is the minimal representation, \(\theta\), needed to generate textures that seem identical (i.e., appear as being originated by the same process) to human observers?
Texture synthesis is usually an iterative image synthesis procedure that begins with a random noise image and uses the parameters \(\theta\) to produce a new improved image as shown in Figure 28.6. We will describe a similar algorithm in Section 32.8 when talking about diffusion models.
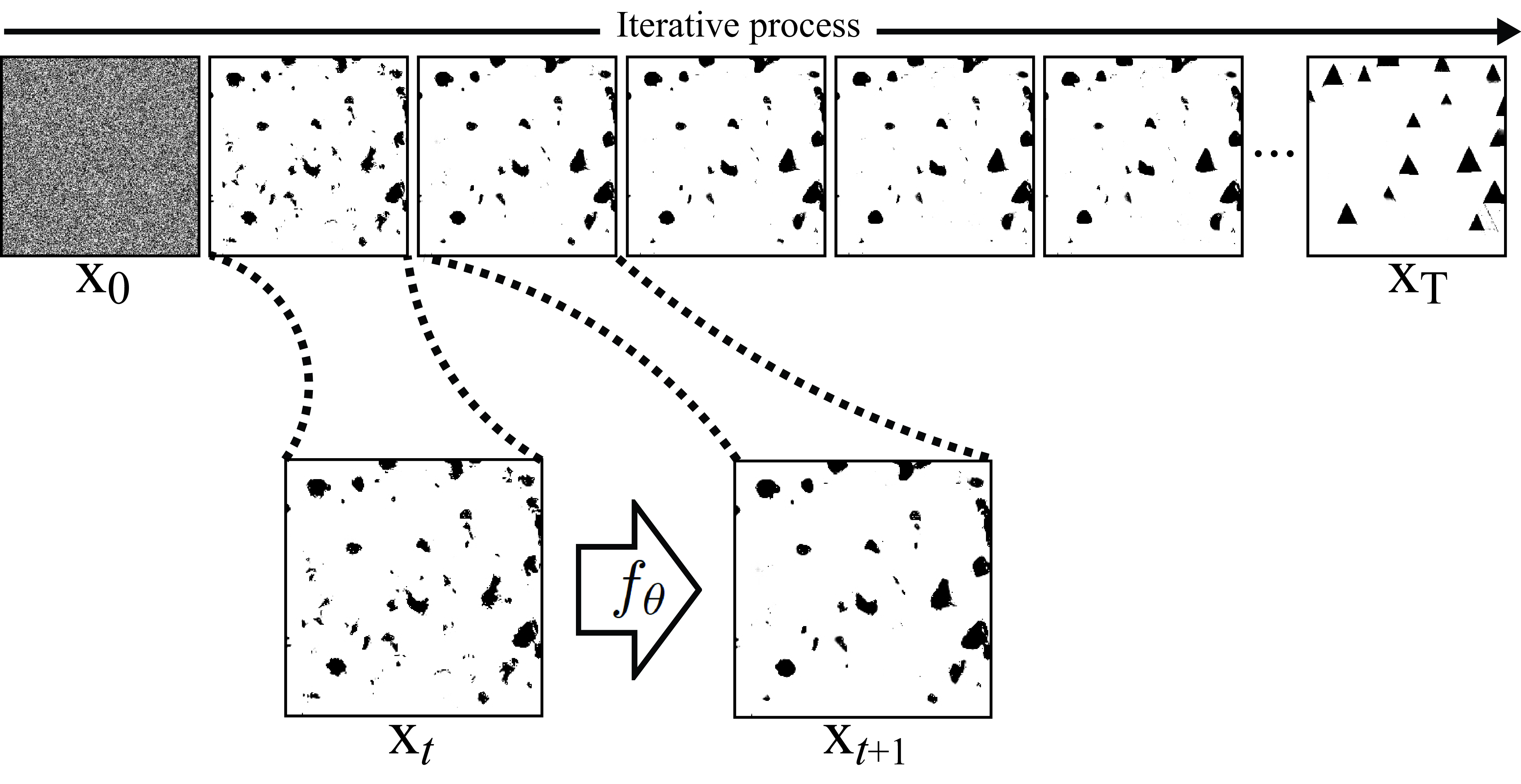
Figure 28.7 shows the main idea behind the approach proposed by Heeger and Bergen to implement the analysis and synthesis functions. First, the reference texture is decomposed multiple orientation and scales as the outputs of many oriented filters over different spatial scales. The transform should represent all spatial frequencies of the image, so that all aspects of a texture can be synthesized, and the subbands should not be aliased, to avoid artifacts in the synthesized results. In the examples shown here we use a steerable pyramid [9] described in chapter Chapter 23 with six orientations and three scales. The final texture representation is the concatenation of the 18 subband histograms, the low-pass residual histogram and the input image histogram (Figure 28.7 [a]).
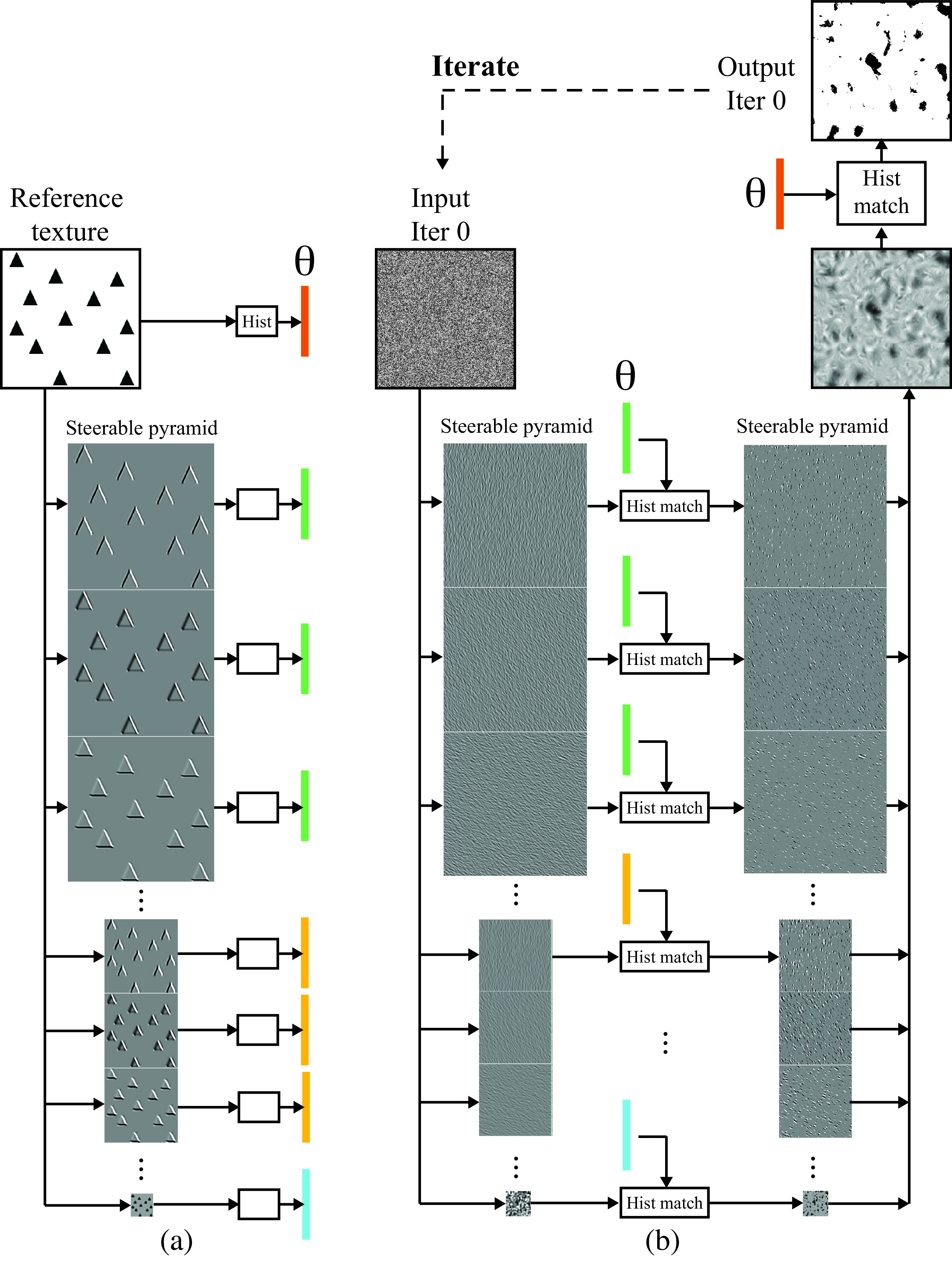
The crux of the algorithm is to alternate matching the intensity domain pixel histogram of the image, then to transform the resulting image into the transform domain and enforce a match, subband by subband, of the image histograms there.
Histogram matching is implemented by a pointwise monotonic nonlinearity.
Figure 28.8 shows how one of the subbands gets transformed by the histogram matching procedure. The histogram of the subband of the reference texture has the Laplacian shape typical of natural images. Most of the values of the output of the oriented filter are zero, and only near the triangle boundaries the values are non-zero. In the first iteration, the texture synthesis process starts with white noise (each pixel is sampled independently from a Gaussian distribution). The subband of the input noise has also a Gaussian distribution (as a linear combination of Gaussian random variables also follows a Gaussian distribution). Histogram matching modifies the values of each subband pixel (the histogram matching function is a pixelwise nonlinearity that depends on the current and target pixel histograms). After histogram matching, the noise subband looks sparser, with many values set to zero. The same operation is done for all the subbands in the steerable pyramid.

Figure 28.7 (b) shows the result of applying this to all the subbands and then collapsing the pyramid to reconstruct an image. Then we also histogram match the output texture to match the histogram of the pixel values of the reference texture. The result is an image that starts showing some initial black blobs that, after repeating the same process multiple times, will become triangles, as shown in Figure 28.6. After several iterations of the histogram matching steps in both domains (subbands and image) the algorithm appears to converge and the result is the synthesized texture.
The results are often quite good. For images like the triangles of Figure 28.5, the algorithm works well. However, we note that correlations of filter responses across scale is not captured in this procedure, and long or large-scale structures are often depicted poorly. Figure 28.9 shows two additional examples with more complex images. To process color images, we first do principal component analysis (PCA) in color space to find decorrelated color components, then we apply the texture analysis-synthesis to each decorrelated channel independently. The final image is produced by projecting back into the original color space. For the results in Figure 28.9, the algorithm is run only for 15 iterations. Adding more iterations makes the images look worse.

Texture models using statistics of filter outputs are a precursor to diffusion models (Section 32.8) and share a number of architectural features.
The Heeger and Bergen model was one of the first successful approaches that used filter outputs to represent arbitrary textures. Other models followed after that introducing stronger statistical representations capable of generating higher quality textures [11].
Parametric texture models represent a texture image with a small vector of parameters, usually around 1,000 dimensions [11].
These models, usually called parametric texture models, stayed popular until 2000. After that, nonparametric texture models became dominant (Section 28.4) until generative models with neural networks emerged around 2014.
28.4 Efros-Leung Texture Analysis and Synthesis Model
Nonparametric Markov random field image models, introduced earlier in chapter Chapter 27, define the probability distribution of a pixel as dependent of neighborhood around the pixel. As we said before, if the values of enough pixels surrounding a given pixel are specified, then the probability distribution of the given pixel is independent of the other pixels in the image. This image model can be used as a powerful texture synthesis model [12].
As with other texture synthesis algorithms, the input to the Efros-Leung algorithm [12] is an example of the texture to be synthesized, and the output is an image of more of that texture. It is an iterative algorithm as shown in Figure 28.10.
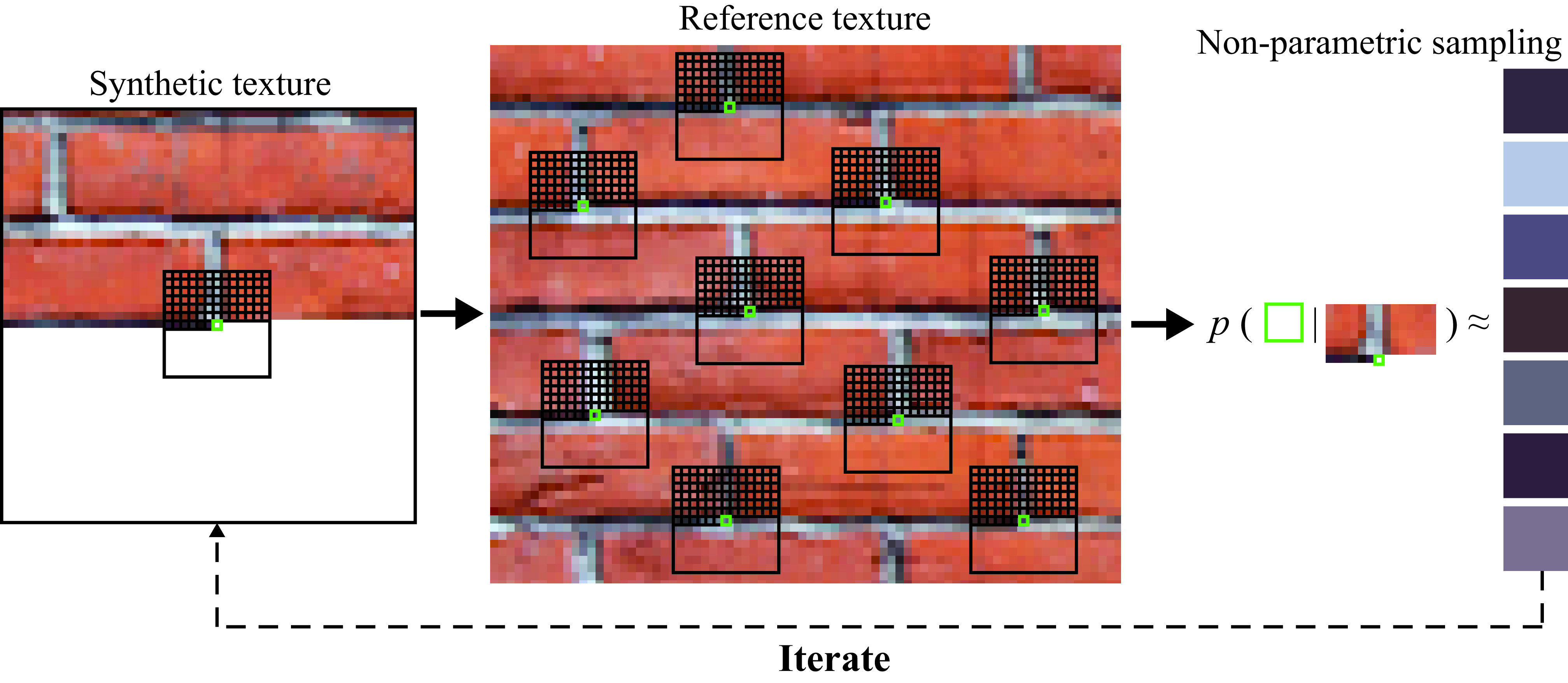
At each iteration, we have synthesized pixels in the neighborhood of the pixel to be synthesized. We look through the input image for examples of similar configurations of pixel values as the current local neighborhood, having a sum of squared intensity differences from the local neighborhood lower than some threshold. Randomly select one of the matching instances, and copy the value of the pixel into the pixel to be synthesized. Repeat for all pixels to be synthesized. It can be natural to synthesize the pixels in a raster-scan ordering. Image pixels without sufficient neighboring pixels for context can be randomly sampled from the input texture.
In this nonparametric model, the representation of a texture is the reference image itself. There is not a low-dimensional representation as it is the case of parametric texture models. The advantage is that no information is lost in this representation.
Figure 28.11 shows how the synthesized texture from the Efros-Leung algorithm [12] changes as a function of size of the context region. Figure 28.11 (a) shows the source texture; Figure 28.11 (b) shows how a very small context region (the grid of Figure 28.10) only covers a part of each circle and the synthesized texture doesn’t show complete circles; Figure 28.11 (c) shows how a larger context region yields a synthesized texture that maintains the circles, but not the regularity of their spacing; and Figure 28.11 (d) shows how a still larger context region enforces all the spatial regularities of the input texture.




Figure 28.12 shows additional image synthesis results. It is remarkable that such a simple model works so well. The results seem better than the ones shown in Figure 28.9; however, note that there can still be artifacts (such as the very big leaf that appear in the output). Increasing the neighborhood size can remove those issues. Also, we can see that some elements of the reference texture might appear multiple times in the output texture. Removing repetitions requires decreasing the neighborhood size.

Embellishments have been developed that account for structures over scale [13] or which are more efficient by operating on patches [14], [15].
28.5 Connection to Deep Generative Models
In chapters Chapter 32 and Chapter 33 we will learn about generative models for image synthesis. These chapters cover models that generate images of all kinds, not just textures. However, they have strong similarities to the texture synthesis models we saw in this chapter. A few of connections are as follows:
The Efros-Leung algorithm is an autoregressive model. Section Section 32.7 covers this class of models in more generality, and shows how to use them in conjunction with deep nets.
The iterative optimization of the Heeger-Bergen algorithm is a type of denoising process: it starts with a noise image and little by little transforms it into an image of a texture. This general idea reappears in Section 32.8 on diffusion models, which follow this same strategy.
The Heeger-Bergen algorithm is also connected to generative adversarial networks (GANs), which we will encounter in
- The objective of Heeger-Bergen is to make a texture that has the same histogram statistics as an exemplar. A GAN also makes images that have the same statistics as a set of exemplars; however, the statistics we seek to match are learned (by a so-called discriminator neural net) rather than hand-defined to be subband statistics.
More generally, texture modeling is about modeling a distribution over patches, while generative modeling is about modeling a distribution over whole images. The tools are similar in both cases but the scope differs in this way.
Be on the lookout for more connections; all generative models are intimately related to each other and it is often possible to frame any one generative model as a special case or extension of any other.
28.6 Concluding Remarks
There is an important relationship between texture models and human perception. One of the goals of many vision algorithms is to compute representations that reproduce image similarities relevant to humans. The representations might be the result of constraining the models to learn human preferences, or as a byproduct of unsupervised learning techniques that result in representations that correlate with human perception.
The methods described in this chapter are the basis to understand some of the latest image generative models.