Neural Architectures for Vision
Building on the concepts introduced in the previous set of chapters, we will describe neural networks for vision. One way of understanding neural networks is to think of them as big signal processors, built as a succession of multiple stages (layers) of learned linear filters (convolutional units) followed by nonlinearities.
Outline
Chapter 24 Convolutional Neural Nets introduces convolutional neural networks, which are very much like image pyramids, but with learned filters.
Chapter 25 Recurrent Neural Nets covers recurrent networks, which enable memory and adaptation over time.
Chapter 26 Transformers describes transformers, a relatively new kind of architecture where the units are vector-valued tokens rather than scalar-valued neurons.
Notation
In this part we will study architectures that can work on both images and other kinds of data. Because of this, we will denote inputs as \(\mathbf{x}\) rather than \(\ell\), even when the input is an image.
Some of the architectures we will encounter can operate over input tensors with variable shapes. For this reason, we will sometimes treat the input signal as a lower-case bolded variable regardless of its dimensionality: \(\mathbf{x}_{\texttt{in}}\) can represent a 1D signal, a 2D image, 3D volumetric data, etc.
For signals with multiple channels, including neural feature maps with multiple features at each coordinate, the first dimension of the tensor indexes over the channel. For example, in \(\mathbf{x} \in \mathbb{R}^{C \times N \times M \times \ldots}\), where \(C\) is the number of channels of the signal.
For transformers, we deviate from the previous point slightly, in order to match standard notation: a set of tokens (which will be defined in the transformers chapter) is represented by a \(N \times d\) matrix, where \(d\) is the token dimensionality.
Node Notation
As shown below, we draw networks with two kinds of nodes:
A token is a vector of neurons used in a particular way, which will be defined in the transformers chapter. We give it a special symbol, a rectangle, to distinguish it from other kinds of vectors of neurons.
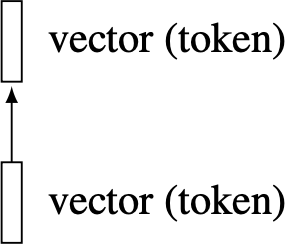
As shown above, sometimes we draw networks with the layers moving left to right and sometimes bottom to top. Both mean the same thing, and the direction in each figure is just chosen for visual clarity.