2 A Simple Vision System
2.1 Introduction
The goal of this chapter is to embrace the optimism of the 1960s and to hand-design an end-to-end visual system. During this process, we will cover some of the main concepts that will be developed in the rest of the book.
In 1966, Seymour Papert wrote a proposal for building a vision system as a summer project [1]. The abstract of the proposal starts by stating a simple goal: “The summer vision project is an attempt to use our summer workers effectively in the construction of a significant part of a visual system.” The report then continues dividing all the tasks (most of which also are common parts of modern computer vision approaches) among a group of MIT students. This project was a reflection of the optimism existing in the early days of computer vision. However, the task proved to be harder than anybody expected.
In this first chapter, we will discuss several of the main topics that we will cover in this book. We will do this in the framework of a real, although a bit artificial, vision problem. Vision has many different goals (e.g., object recognition, scene interpretation, three-dimensional [3D] interpretation), but in this chapter we’re just focusing on the task of 3D interpretation.
2.2 A Simple World: The Blocks World
As the visual world is too complex, we will start by simplifying it enough that we will be able to build a simple visual system right away. This was the strategy used by some of the first scene interpretation systems. Larry G. Roberts [2] introduced the Block world, a world composed of simple 3D geometrical figures.
Blocks world from Larry Roberts’ Ph.D. in June 1963.
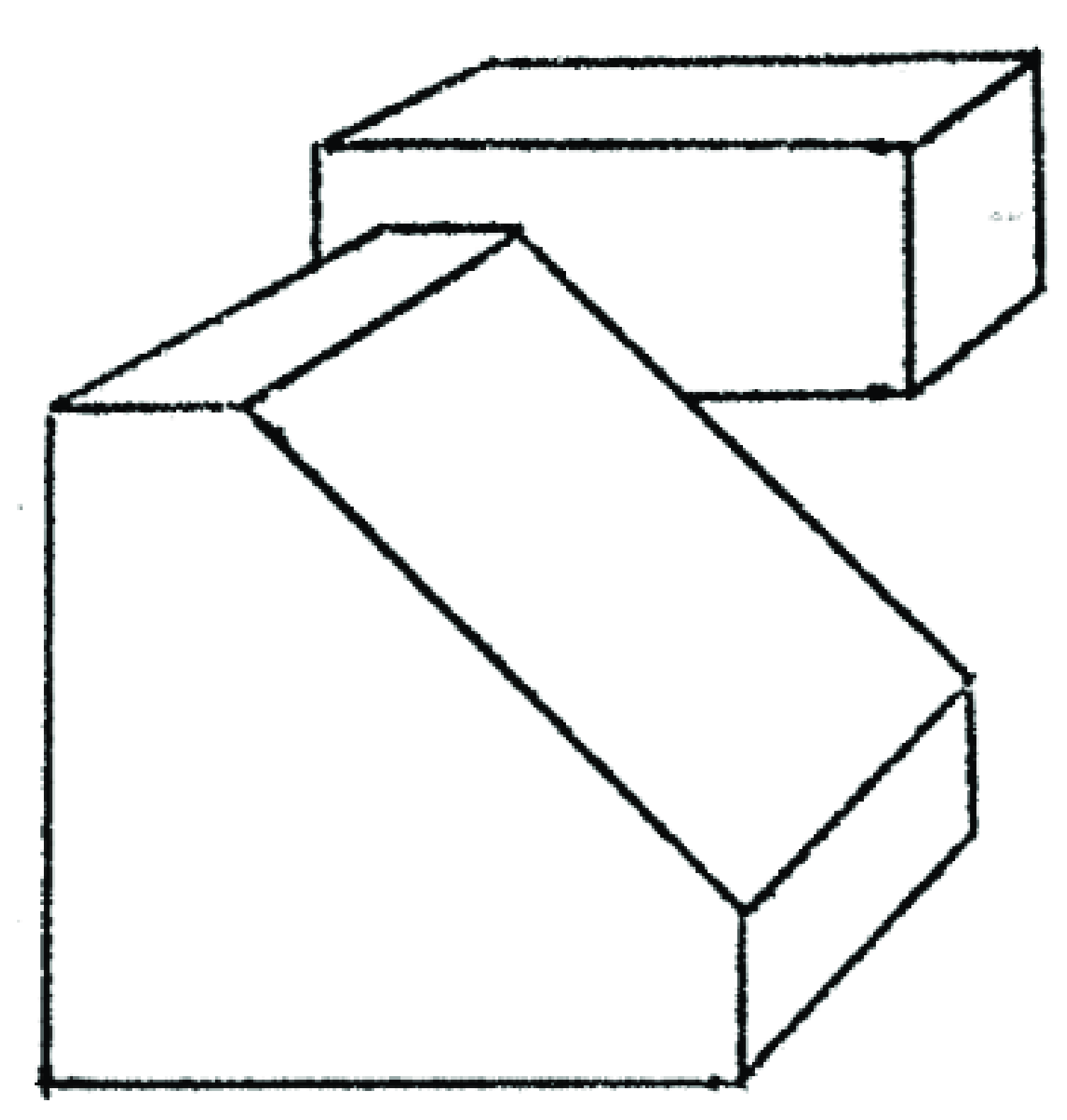
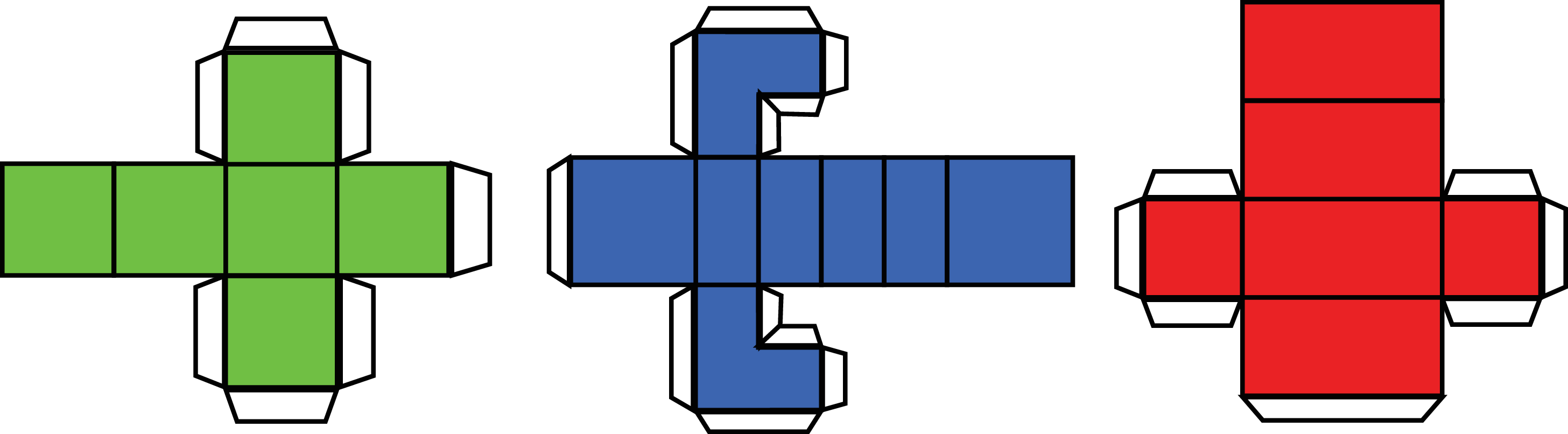
For the purposes of this chapter, let’s think of a world composed of a very simple (yet varied) set of objects. These simple objects are composed of flat surfaces that can be horizontal or vertical. These objects will be resting on a white horizontal ground plane. We can build these objects by cutting, folding, and gluing together some pieces of colored paper as shown in Figure 2.1. Here, we will not assume that we know the exact geometry of these objects in advance.
2.3 A Simple Image Formation Model
One of the simplest forms of projection is parallel (or orthographic) projection. In this image formation model, the light rays travel parallel to each other and perpendicular to the camera plane. This type of projection produces images in which objects do not change size as they move closer or farther from the camera, and parallel lines in 3D remain parallel in the 2D image. This is different from the perspective projection, to be discussed in , where the image is formed by the convergence of the light rays into a single point (focal point). If we do not take special care, most pictures taken with a camera will be better described by perspective projection, as shown in Figure 2.2, (a).

One way of generating images that can be described by parallel projection is to use the camera zoom. If we increase the distance between the camera and the object while zooming, we can keep the same approximate image size of the objects, but with reduced perspective effects, as shown in Figure 2.2 (b). Note how, in Figure 2.2 (b), 3D parallel lines in the world are almost parallel in the image (some weak perspective effects remain).
Changing the zoom to compensate a moving camera can be used to create movie effects. This method was introduced by Alfred Hitchcock to create a sequence, centered in a subject, where the background moves away or closer to the subject.
The first step is to characterize how a point in world coordinates \((X,Y,Z)\) projects into the image plane. Figure 2.3 (a) shows our parameterization of the world and the camera coordinate systems. The camera center is inside the 3D plane \(X=0\), and the horizontal axis of the camera (\(x\)) is parallel to the ground plane (\(Y=0\)). The camera is tilted so that the line connecting the origin of the world coordinates system and the image center is perpendicular to the image plane. The angle \(\theta\) is the angle between this line and the \(Z\)-axis. The image is parameterized by coordinates \((x,y)\).

In this simple projection model, the origin of the world coordinates projects on the origin of the image coordinates. Therefore, the world point \((0,0,0)\) projects into \((0,0)\). The resolution of the image (the number of pixels) will also affect the transformation from world coordinates to image coordinates via a constant factor \(\alpha\) (for now we assume that pixels are square and we will see a more general form in ) and that this constant is \(\alpha=1\). Taking into account all these assumptions, the transformation between world coordinates and image coordinates can be written as follows: \[\begin{aligned} x &=& X \\ y &=& \cos(\theta) Y - \sin(\theta) Z \end{aligned} \tag{2.1}\]
With this particular parametrization of the world and camera coordinate systems, the world coordinates \(Y\) and \(Z\) are mixed after projection. From the camera, a point moving parallel to the \(Z\)-axis will be indistinguishable from a point moving parallel to the \(Y\)-axis.
2.4 A Simple Goal
Part of the simplification of the vision problem resides in simplifying its goals. In this chapter we will focus on recovering the world coordinates of all the pixels seen by the camera.
Besides recovering the 3D structure of the scene, there are many other possible goals that we will not consider in this chapter. For instance, one goal (which might seem simpler but is not) is to recover the actual color of the surface seen by each pixel \((x,y)\). This will require discounting for illumination effects as the color of the pixel is a combination of the surface albedo and illumination (color of the light sources and interreflections).
2.5 From Images to Edges and Useful Features
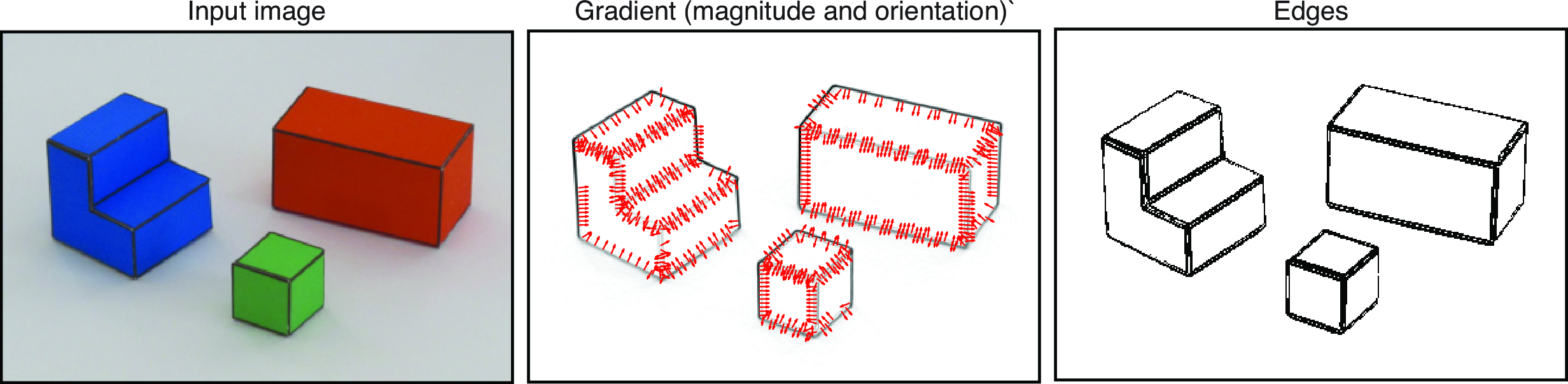
The observed image is a function, \[\ell(x,y)\] that takes as input location, \((x,y)\), and it outputs the intensity at that location. In this representation, the image is an array of intensity values (color values) indexed by location (Figure 2.4).
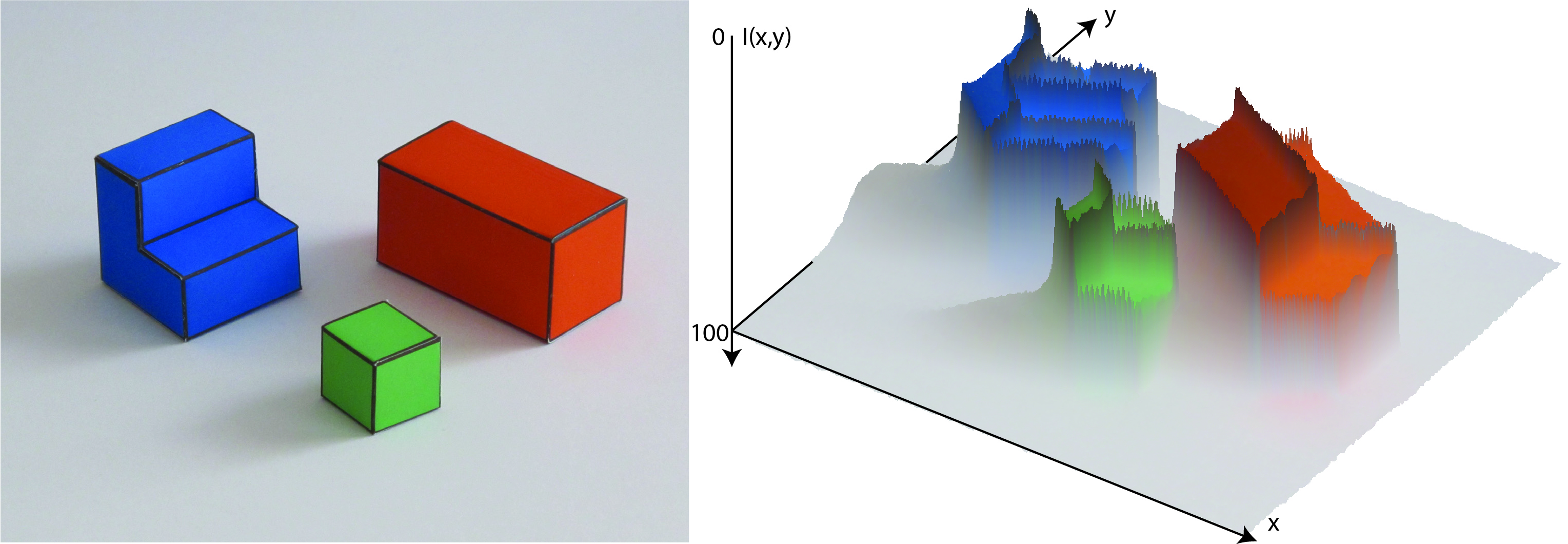
This representation is ideal for determining the light intensity originating from different directions in space and striking the camera plane, as it provides explicit representation of this information. The array of pixel intensities, \(\ell(x,y)\), is a reasonable representation as input to the early stages of visual processing because, although we do not know the distance of surfaces in the world, the direction of each light ray in the world is well defined. However, other initial representations could be used by the visual system (e.g., images could be coded in the Fourier domain, or pixels could combine light coming in different directions).
However, in the simple visual system of this chapter we are interested in interpreting the 3D structure of the scene and the objects within. Therefore, it will be useful to transform the image into a representation that makes more explicit some of the important parts of the image that carry information about the boundaries between objects and changes in the surface orientation. There are several representations that can be used as an initial step for scene interpretation. Images can be represented as collections of small image patches, regions of uniform properties, and edges.
2.5.1 A Catalog of Edges
Edges denote image regions where there are strong changes of the image with respect to location. Those variations can be due to a multitude of scene factors (e.g., occlusion boundaries, changes in surface orientation, changes in surface albedo, shadows).
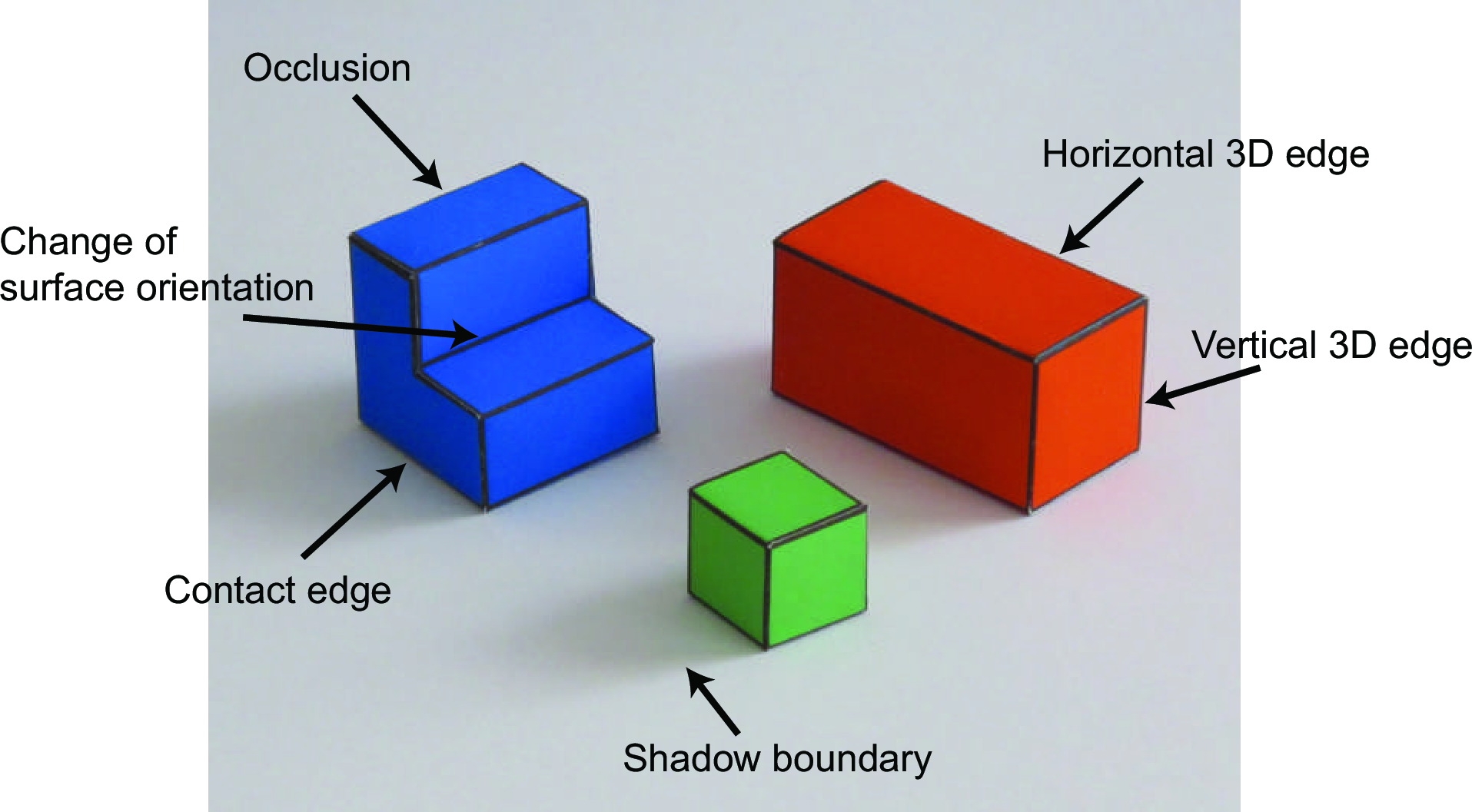
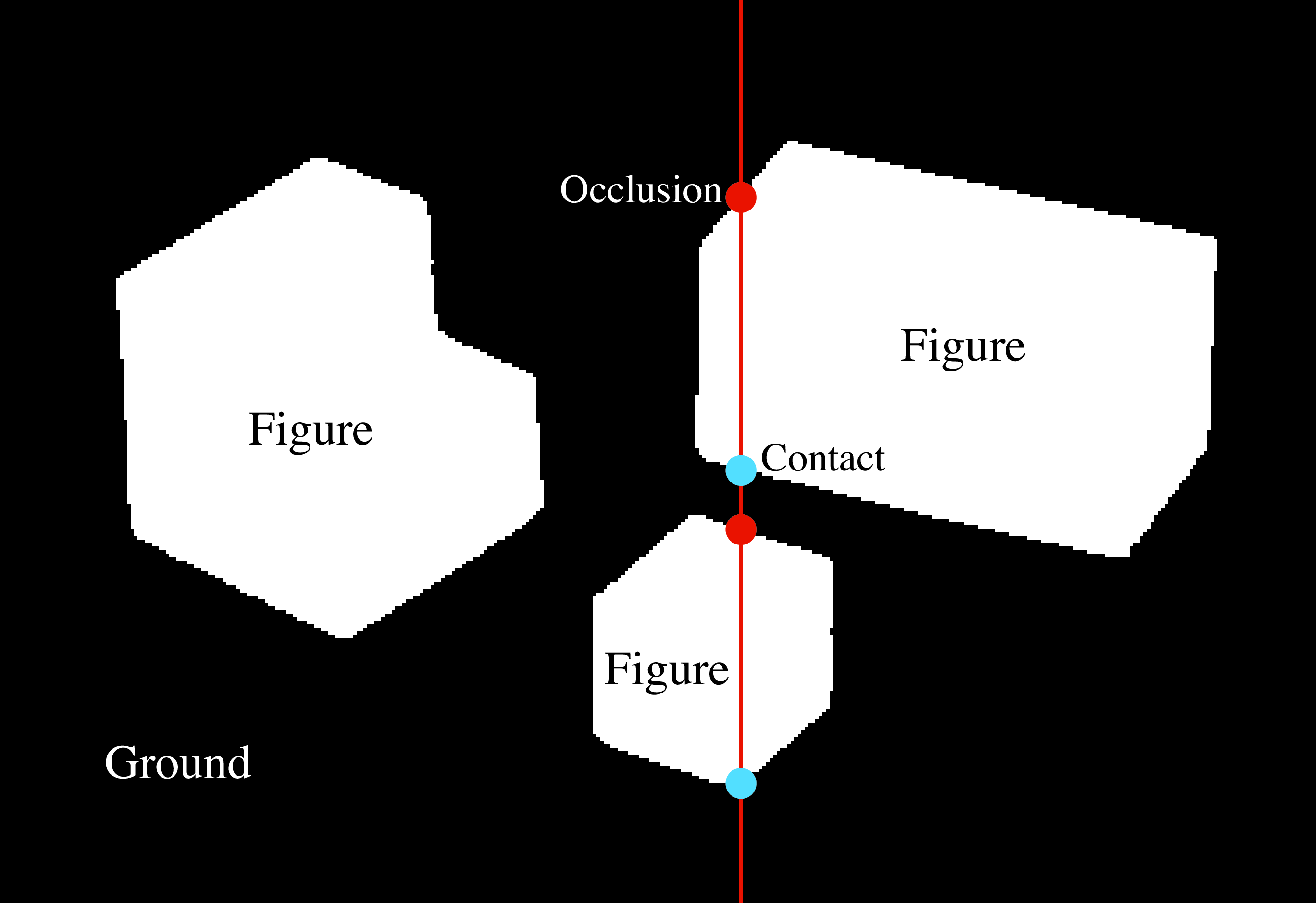
One of the tasks that we will solve first is to classify image edges according to their most probable cause. We will use the following classification of image boundaries (Figure 2.5):
Object boundaries: These indicate pixels that delineate the boundaries of any object. Boundaries between objects generally correspond to changes in surface color, texture, and orientation.
Changes in surface orientation: These indicate locations where there are strong image variations due to changes in the surface orientations. A change in surface orientation produces changes in the image intensity because intensity is a function of the angle between the surface and the incident light.
Shadow edges: This can be harder than it seems. In this simple world, shadows are soft, creating slow transitions between dark and light.
We will also consider two types of object boundaries:
Contact edges: This is a boundary between two objects that are in physical contact. Therefore, there is no depth discontinuity.
Occlusion boundaries: Occlusion boundaries happen when an object is partially in front of another. Occlusion boundaries generally produce depth discontinuities. In this simple world, we will position the objects in such a way that objects do not occlude each other but they will occlude the background.
Despite the apparent simplicity of this task, in most natural scenes, this classification is very hard and requires the interpretation of the scene at different levels. In other chapters we will see how to make better edge classifiers (i.e., by propagating information along boundaries, junction analysis, inferring light sources).
2.5.2 Extracting Edges from Images
The first step will consist in detecting candidate edges in the image. Here we will start by making use of some notions from differential geometry. If we think of the image \(\ell (x,y)\) as a function of two (continuous) variables (Figure 2.4), we can measure the degree of variation using the gradient: \[\begin{aligned} \nabla \ell = \left( \frac{\partial \ell}{\partial x}, \frac{\partial \ell}{\partial y} \right) \end{aligned}\] The direction of the gradient indicates the direction in which the variation of intensities is larger. If we are on top of an edge, the direction of larger variation will be in the direction perpendicular to the edge.
Gradient of an image at one location. 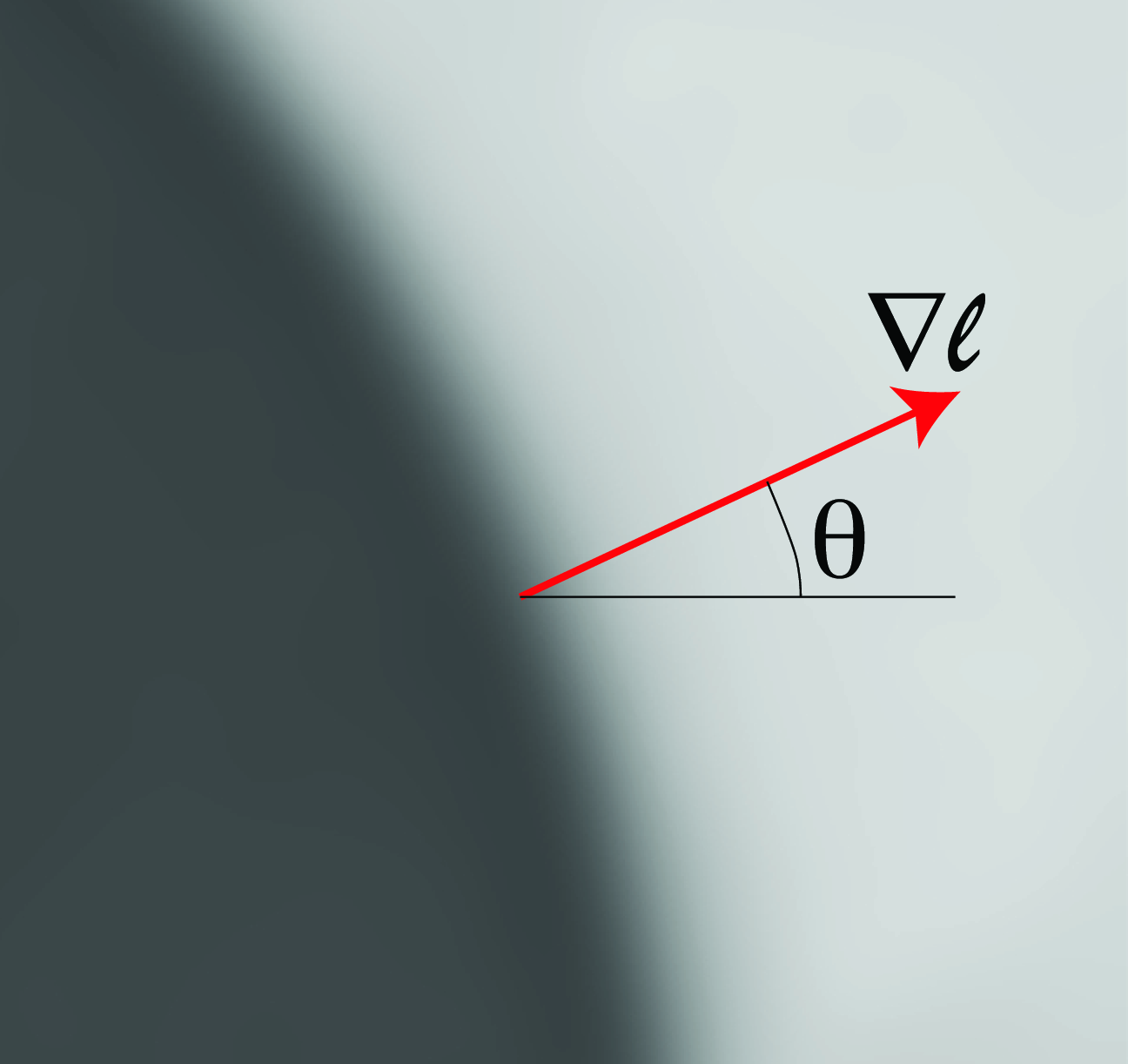
However, the image is not a continuous function as we only know the values of the \(\ell (x,y)\) at discrete locations (pixels). Therefore, we will approximate the partial derivatives by: \[\begin{aligned} \frac{\partial \ell}{\partial x} &\simeq \ell(x,y) - \ell(x-1,y) \\ \frac{\partial \ell}{\partial y} &\simeq \ell(x,y) - \ell(x,y-1) \end{aligned} \tag{2.2}\]
A better behaved approximation of the partial image derivative can be computed by combining the image pixels around \((x,y)\) with the weights: \[\begin{aligned} \frac{1}{4} \times \left [ \begin{matrix} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \end{matrix} \right ] \nonumber \end{aligned}\] We will discuss these approximations in detail in Chapter 18.
From the image gradient, we can extract a number of interesting quantities:
\[\begin{aligned} e(x,y) &= \lVert \nabla \ell(x,y) \rVert & \quad\quad \triangleleft \quad \texttt{edge strength}\\ \theta(x,y) &= \angle \nabla \ell = \arctan \left( \frac{\partial \ell / \partial y}{\partial \ell / \partial x} \right) & \quad\quad \triangleleft \quad \texttt{edge orientation} \end{aligned}\]
The edge strength is the gradient magnitude, and the edge orientation is perpendicular to the gradient direction.
The unit norm vector perpendicular to an edge is:
\[\begin{aligned} {\bf n} = \frac{\nabla \ell}{\lVert \nabla \ell \rVert} \end{aligned}\]
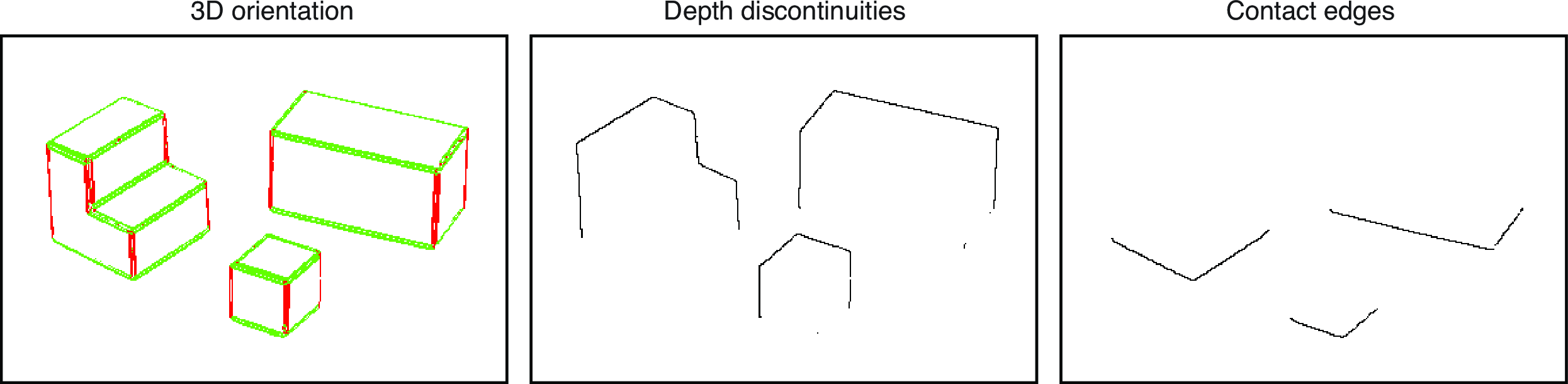
The first decision that we will perform is to decide which pixels correspond to edges (regions of the image with sharp intensity variations) and which ones belong to uniform regions (flat surfaces). We will do this by simply thresholding the edge strength \(e(x,y)\). In the pixels with edges, we can also measure the edge orientation \(\theta(x,y)\). Figure 2.6 and Figure 2.7 visualize the edges and the normal vector on each edge.
2.6 From Edges to Surfaces
We want to recover world coordinates \(X(x,y)\), \(Y(x,y)\), and \(Z(x,y)\) for each image location \((x,y)\). Given the simple image formation model described before, recovering the \(X\) world coordinates is trivial as they are directly observed: for each pixel with image coordinates \((x,y)\), the corresponding world coordinate is \(X(x,y) = x\). Recovering \(Y\) and \(Z\) will be harder as we only observe a mixture of the two world coordinates (one dimension is lost due to the projection from the 3D world into the image plane). Here we have written the world coordinates as functions of image location \((x,y)\) to make explicit that we want to recover the 3D locations of the visible points.
The classical visual illusion ``two faces or a vase’’ is an example of figure-ground segmentation problem.

In this simple world, we will formulate this problem as a set of linear equations.
2.6.1 Figure/Ground Segmentation
Segmentation of an image into figure and ground is a classical problem in human perception and computer vision that was introduced by Gestalt psychology.
In this simple world deciding when a pixel belongs to one of the foreground objects or to the background can be decided by simply looking at the color values of each pixel. Bright pixels that have low saturation (similar values of the red-blue-green [RBG] components) correspond to the white ground plane, and the rest of the pixels are likely to belong to the colored blocks that compose our simple world. In general, the problem of image segmentation into distinct objects is a very challenging task.
Once we have classified pixels as ground or figure, if we assume that the background corresponds to a horizontal ground plane, then for all pixels that belong to the ground we can set \(Y(x,y)=0\). For pixels that belong to objects we will have to measure additional image properties before we can deduce any geometric scene constraints.
2.6.2 Occlusion Edges
An occlusion boundary separates two different surfaces at different distances from the observer. Along an occlusion edge, it is also important to know which object is in front as this will be the one owning the boundary. Knowing who owns the boundary is important as an edge provides cues about the 3D geometry, but those cues only apply to the surface that owns the boundary.
Border ownership: The foreground object is the one that owns the common edge.
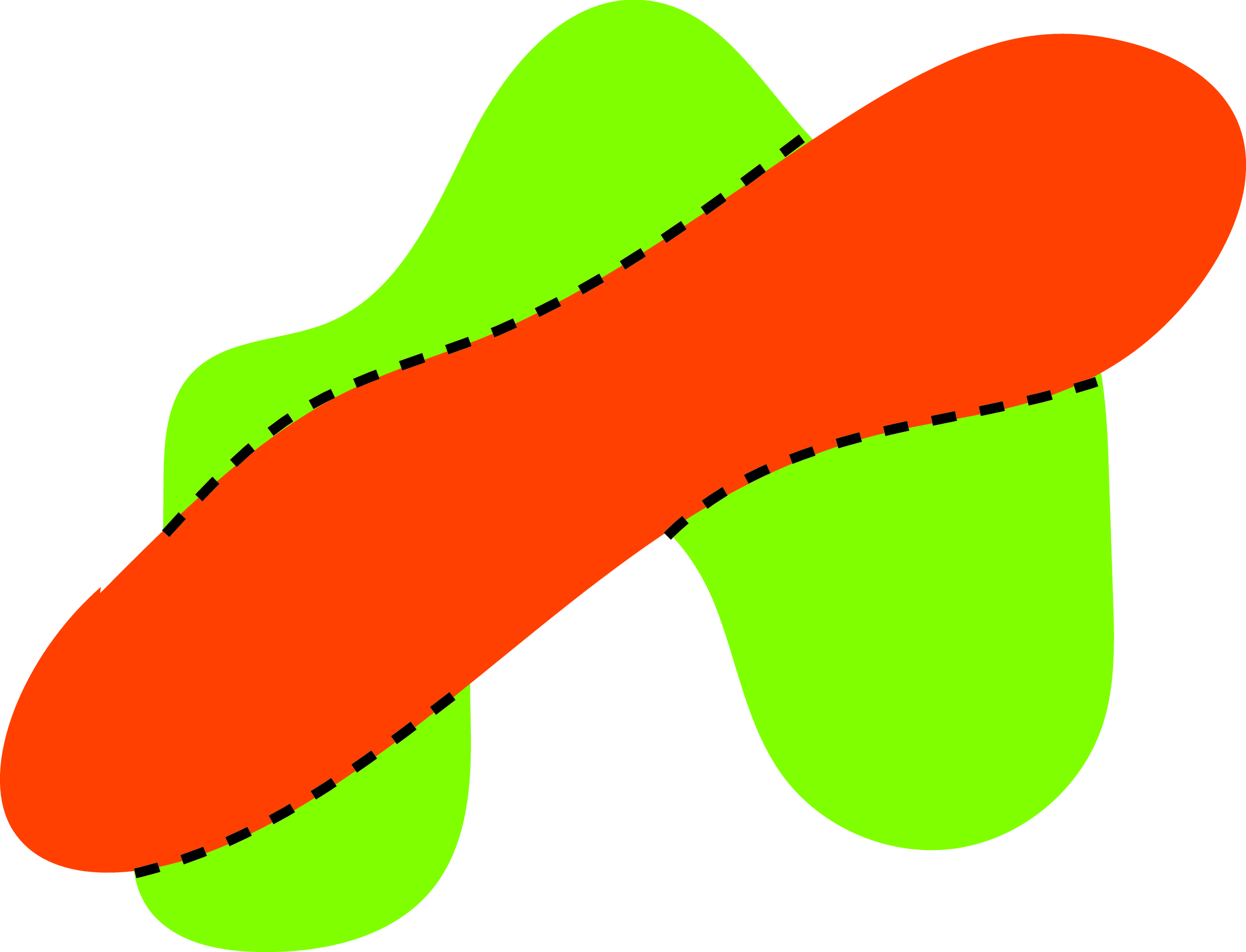
In this simple world, we will assume that objects do not occlude each other (this can be relaxed) and that the only occlusion boundaries are the boundaries between the objects and the ground. However, as we describe subsequently, not all boundaries between the objects and the ground correspond to depth gradients.
2.6.3 Contact Edges
Contact edges are boundaries between two distinct objects but where there exists no depth discontinuity. Despite that there is not a depth discontinuity, there is an occlusion here (as one surface is hidden behind another), and the edge shape is only owned by one of the two surfaces.
In this simple world, if we assume that all the objects rest on the ground plane, then we can set \(Y(x,y)=0\) on the contact edges. Contact edges can be detected as transitions between the object (above) and ground (below). In our simple world only horizontal edges can be contact edges. We will discuss next how to classify edges according to their 3D orientation.
2.6.4 Generic View and Nonaccidental Scene Properties
Despite that in the projection of world coordinates to image coordinates we have lost a great deal of information, there are a number of properties that will remain invariant and can help us in interpreting the image. Here is a list of some of those invariant properties:
Collinearity: a straight 3D line will project into a straight line in the image.
Cotermination: if two or more 3D lines terminate at the same point, the corresponding projections will also terminate at a common point.
Smoothness: a smooth 3D curve will project into a smooth 2D curve.
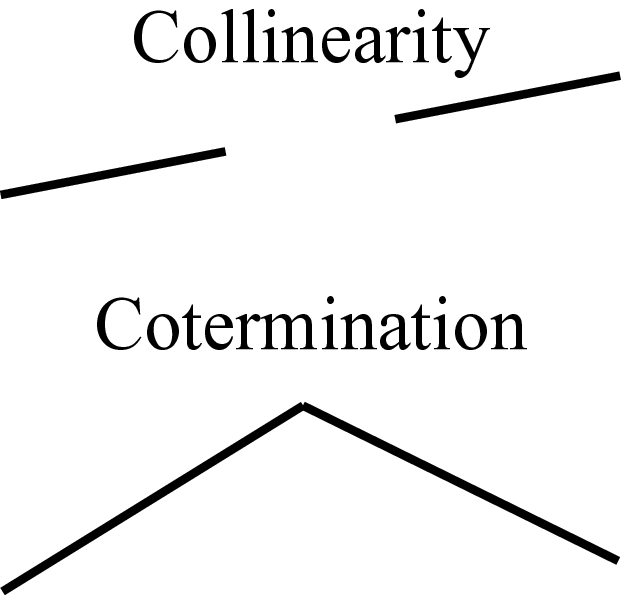
Note that those invariances refer to the process of going from world coordinates to image coordinates. The opposite might not be true. For instance, a straight line in the image could correspond to a curved line in the 3D world but that happens to be precisely aligned with respect to the viewers point of view to appear as a straight line. Also, two lines that intersect in the image plane could be disjointed in the 3D space.
However, some of these properties (not all), while not always true, can nonetheless be used to reliably infer something about the 3D world using a single 2D image as input. For instance, if two lines coterminate in the image, then, one can conclude that it is very likely that they also touch each other in 3D. If the 3D lines do not touch each other, then it will require a very specific alignment between the observer and the lines for them to appear to coterminate in the image. Therefore, one can safely conclude that the lines might also touch in 3D.
These properties are called nonaccidental properties [5] because they will only be observed in the image if they also exist in the world or by accidental alignments between the observer and scene structures. Under a generic view, nonaccidental properties will be shared by the image and the 3D world [6].
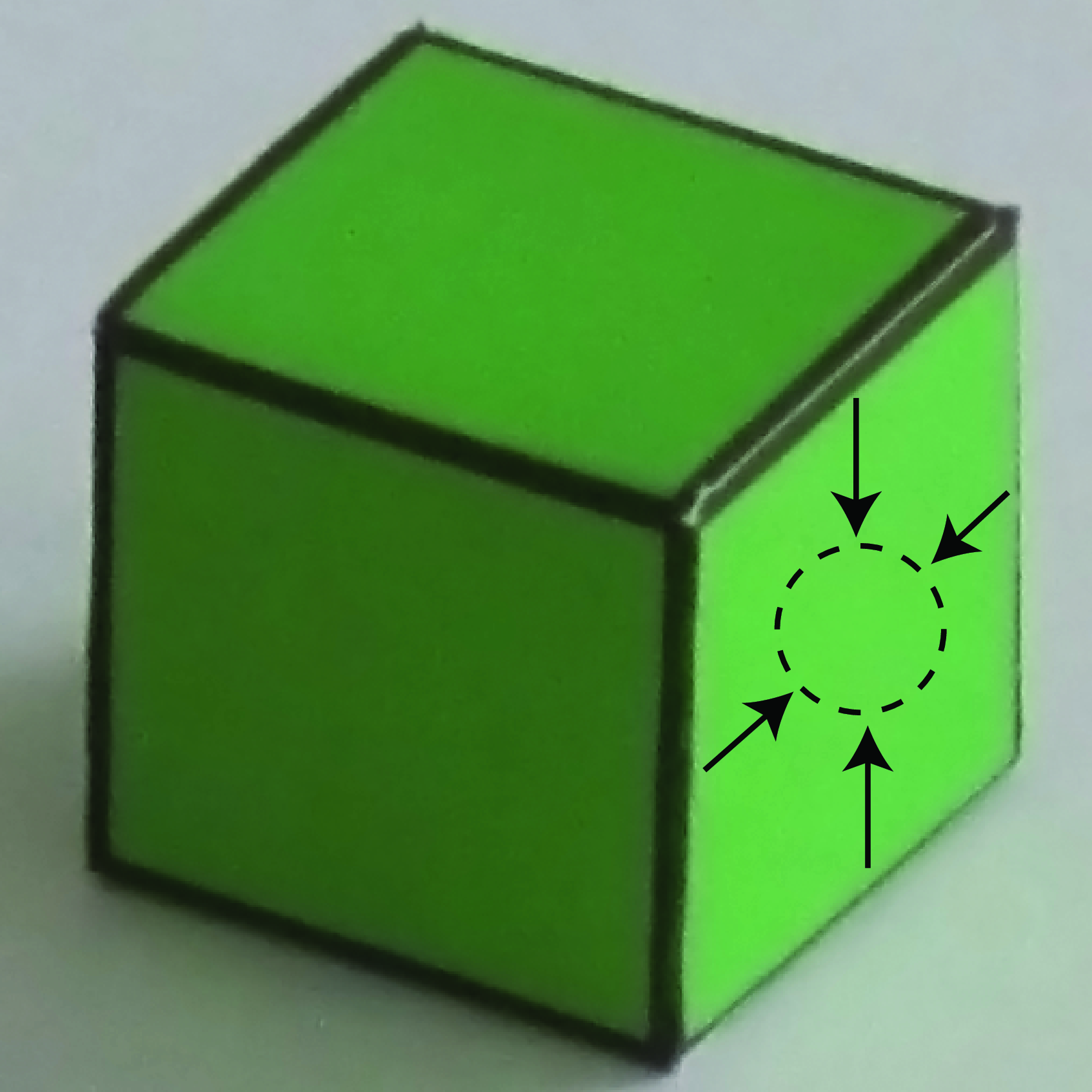
Let’s see how this idea applies to our simple world. In this simple world all 3D edges are either vertical or horizontal. Under parallel projection and with the camera having its horizontal axis parallel to the ground, we know that vertical 3D lines will project into vertical 2D lines in the image. Conversely, horizontal lines will, in general, project into oblique lines. Therefore, we can assume than any vertical line in the image is also a vertical line in the world.
However, the assumption that vertical 2D lines are also 3D vertical lines will not always work. As shown in Figure 2.9, in the case of the cube, there is a particular viewpoint that will make an horizontal line project into a vertical line, but this will require an accidental alignment between the cube and the line of sight of the observer. Nevertheless, this is a weak property and accidental alignments such as this one can occur, and a more general algorithm will need to account for that. But for the purposes of this chapter we will consider images with generic views only.

In Figure 2.6 we show the edges classified as vertical or horizontal using the edge angle. Anything that deviates from 2D verticality by more than 15 degrees is labeled as 3D horizontal.
We can now translate the inferred 3D edge orientation into linear constraints on the global 3D structure. We will formulate these constraints in terms of \(Y(x,y)\). Once \(Y(x,y)\) is recovered we can also recover \(Z(x,y)\) from Equation 2.1.
In a 3D vertical edge, using the projection equations, the derivative of \(Y\) along the edge will be
\[\begin{aligned} \partial Y / \partial y &= 1/ \cos(\theta)\end{aligned} \tag{2.3}\]
In a 3D horizontal edge, the coordinate \(Y\) will not change. Therefore, the derivative along the edge should be zero:
\[\begin{aligned} \partial Y / \partial {\bf t} &= 0 \end{aligned} \tag{2.4}\]
where the vector \(\bf t\) denotes direction tangent to the edge, \({\bf t}=(-n_y, n_x)\).

We can write this derivative as a function of derivatives along the \(x\) and \(y\) image coordinates: \[\begin{aligned} \partial Y / \partial {\bf t} = \nabla Y \cdot {\bf t} = -n_y \partial Y / \partial x + n_x \partial Y / \partial y \end{aligned} \tag{2.5}\]
When the edges coincide with occlusion edges, special care should be taken so that these constraints are only applied to the surface that owns the boundary.
In this chapter, we represent the world coordinates \(X(x,y)\), \(Y(x,y)\), and \(Z(x,y)\) as images where the coordinates \(x,y\) correspond to pixel locations. Therefore, it is useful to approximate the partial derivatives in the same way that we approximated the image partial derivatives in equations (Equation 2.2). Using this approximation, Equation 2.3 can be written as follows: \[\begin{aligned} Y(x,y)-Y(x,y-1) &= 1/ \cos(\theta) \end{aligned}\]
Similar relationships can be obtained from equations Equation 2.4 and Equation 2.5.
2.6.5 Constraint Propagation
Most of the image consists of flat regions where we do not have such edge constraints and we thus don’t have enough local information to infer the surface orientation. Therefore, we need some criteria in order to propagate information from the boundaries, where we do have information about the 3D structure, into the interior of flat image regions. This problem is common in many visual domains.
An image patch without context is not enough to infer its 3D shape.

The same patch shown in the original image (right):
Information about its 3D orientation its propagated from the surrounding edges.
In this case we will assume that the object faces are planar. Thus, flat image regions impose the following constraints on the local 3D structure: \[\begin{aligned} \partial^2 Y / \partial x^2 &= 0 \\ \partial^2 Y / \partial y^2 &= 0 \\ \partial^2 Y / \partial y \partial x &= 0 \end{aligned}\] That is, the second order derivative of \(Y\) should be zero. As before, we want to approximate the continuous partial derivatives. The approximation to the second derivative can be obtained by applying twice the first order derivative approximated by equations (Equation 2.2). The result is \(\partial^2 Y / \partial x^2 \simeq 2Y(x,y)-Y(x+1,y)-Y(x-1,y)\), and similarly for \(\partial^2 X / \partial x^2\).
2.6.6 A Simple Inference Scheme
All the different constraints described previously can be written as an overdetermined system of linear equations. Each equation will have the form: \[\begin{aligned} \mathbf{a}_i \mathbf{Y} = b_i \end{aligned}\] where \(\mathbf{Y}\) is a vectorized version of the image \(Y\) (i.e., all rows of pixels have been concatenated into a flat vector). Note that there might be many more equations than there are image pixels.
We can translate all the constraints described in the previous sections into this form. For instance, if the index \(i\) corresponds to one of the pixels inside one of the planar faces of a foreground object, then there will be three equations. One of the planarity constraint can be written as \(\mathbf{a}_i = [0, \dots, 0, -1, 2, -1, 0, \dots, 0]\), \(b_i=0\), and analogous equations can be written for the other two.
We can solve the system of equations by minimizing the following cost function: \[\begin{aligned} J = \sum_i (\mathbf{a}_i\mathbf{Y} - b_i)^2 \end{aligned}\] where the sum is over all the constraints.
If some constraints are more important than others, it is possible to also add a weight \(w_i\). \[\begin{aligned} J = \sum_i w_i (\mathbf{a}_i \mathbf{Y} - b_i)^2 \end{aligned}\]
Our formulation has resulted on a big system of linear constraints (there are more equations than there are pixels in the image). It is convenient to write the system of equations in matrix form: \[\begin{aligned} \mathbf{A} \mathbf{Y} = \mathbf{b} \end{aligned}\]
where row \(i\) of the matrix \({\bf A}\) contains the constraint coefficients \(\mathbf{a}_i\). The system of equations is overdetermined (\(\mathbf{A}\) has more rows than columns). We can use the pseudoinverse to compute the solution:
\[\begin{aligned} \bf Y = (\mathbf{A}^T \mathbf{A})^{-1} \mathbf{A}^T \mathbf{b} \end{aligned}\] This problem can be solved efficiently as the matrix \(\mathbf{A}\) is very sparse (most of the elements are zero).
2.6.7 Results
Figure 2.10 shows the resulting world coordinates \(X(x,y)\), \(Y(x,y)\), \(Z(x,y)\) for each pixel. The world coordinates are shown here as images with the gray level coding the value of each coordinate (black corresponds to the value 0).
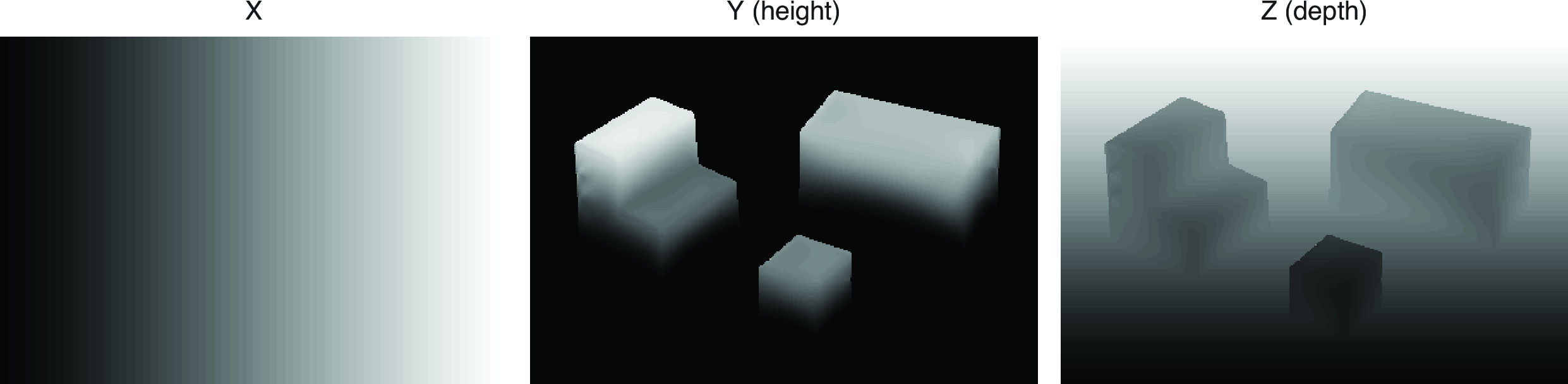
There are a few things to reflect on:
It works. At least it seems to work pretty well. Knowing how well it works will require having some way of evaluating performance. This will be important.
But it cannot possibly work all the time. We have made lots of assumptions that will work only in this simple world. The rest of the book will involve upgrading this approach to apply to more general input images.
Despite that this approach will not work on general images, many of the general ideas will carry over to more sophisticated solutions (e.g., gather and propagate local evidence). One thing to think about is if information about 3D orientation is given in the edges, how does that information propagate to the flat areas of the image in order to produce the correct solution in those regions?
Evaluation of performance is a very important topic. Here, one simple way to visually verify that the solution is correct is to render the objects under new view points. Figure 2.11 shows the reconstructed 3D scene rendered under different view points to show that the 3D structure has been accurately captured.

You may also try the interactive demo below to see the 3D structure. (The demo supports mouse zoom in and out, pan, and rotate.)
2.7 Generalization
One desired property of any vision system is its ability to generalize outside of the domain for which it was designed to operate. In the approach presented in this chapter, the domain of images the algorithm is expected to work on is defined by the assumptions described in . Later in the book, when we describe learning-based approaches, the training dataset will specify the domain. What happens when assumptions are violated? Or when the images contain configurations that we did not consider while designing the algorithm?
Out of domain generalization refers to the ability of a system to operate outside the domain for which it was designed.
Let’s run the algorithm with shapes that do not satisfy the assumptions that we have made for the simple world. Figure 2.12 shows the result when the input image violates several assumptions we made (shadows are not soft and the green cube occludes the red one) and when it has one object on top of the other, a configuration that we did not consider while designing the algorithm. In this case the result happens to be good, but it could have gone wrong.
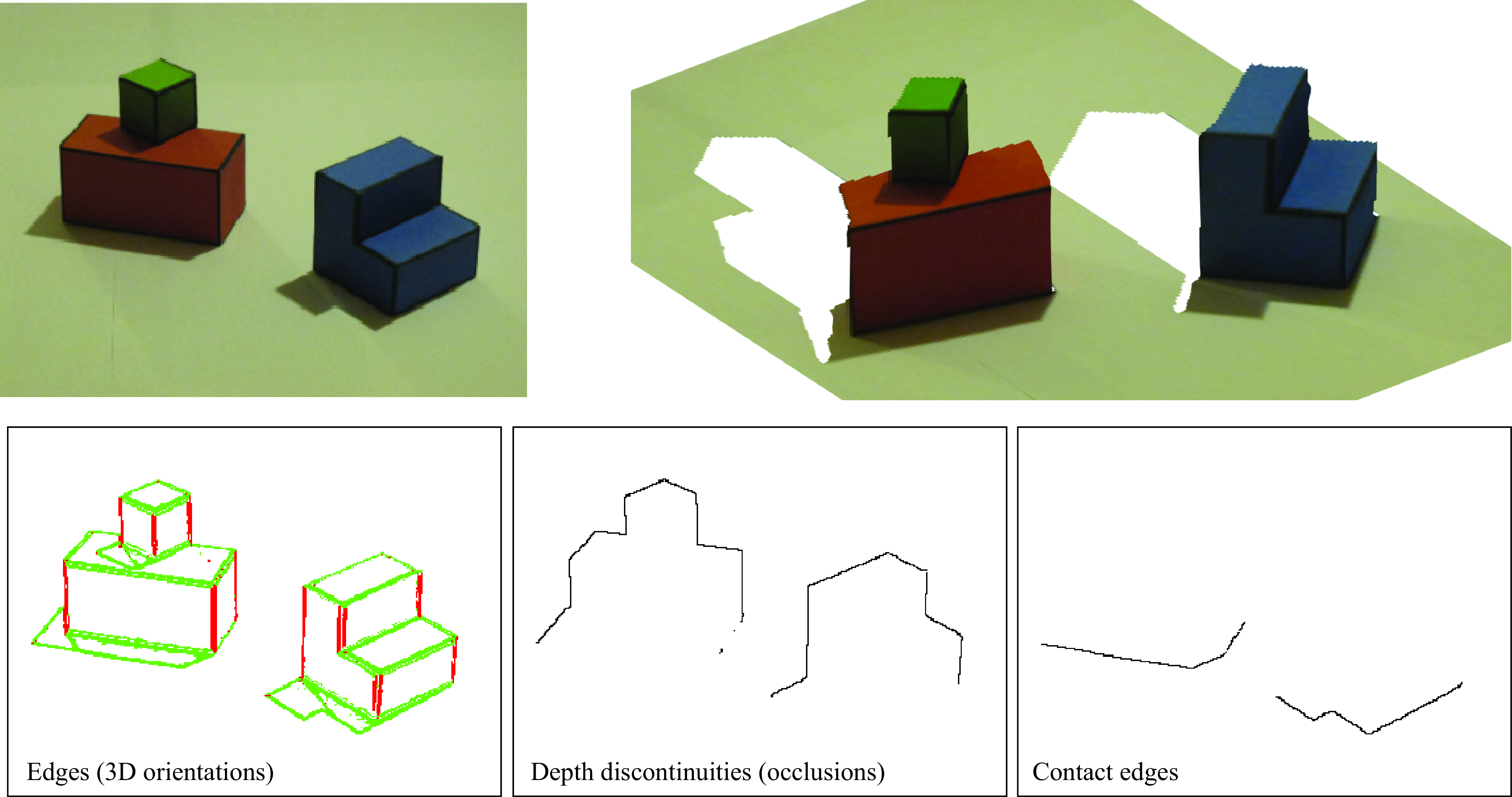
Figure 2.13 shows the impossible steps inspired from [7]. On the left side, this shape looks rectangular and the stripes appear to be painted on the surface. On the right side, the shape looks as though it has steps, with the stripes corresponding to shading due to the surface orientation. In the middle, the shape is ambiguous. Figure 2.13 shows the reconstructed 3D scene for this unlikely image. The system has tried to approximate the constraints, but for this shape it is not possible to exactly satisfy all the constraints.

2.8 Concluding Remarks
Despite having a 3D representation of the structure of the scene, the system is still unaware of the fact that the scene is composed of a set of distinct objects. For instance, as the system lacks a representation of which objects are actually present in the scene, we cannot visualize the occluded parts. The system cannot do simple tasks like counting the number of cubes.
A different approach to the one discussed here is model-based scene interpretation, where we could have a set of predefined models of the objects that can be present in the scene and the system can try to decide if they are present or not in the image, and recover their parameters (i.e., pose, color).
Recognition allows indexing properties that are not directly available in the image. For instance, we can infer the shape of the invisible surfaces. Recognizing each geometric figure also implies extracting the parameters of each figure (i.e., pose, size).
Given a detailed representation of the world, we could render the image back, or at least some aspects of it. We can check that we are understanding things correctly and judge if we can make verifiable predictions, such as what we would see if we looked behind the object. Closing the loop between interpretation and input will be productive at some point.
In this chapter, besides introducing some useful vision concepts, we also made use of mathematical tools from algebra and calculus that you should be familiar with.