44 Multiview Geometry and Structure from Motion
44.1 Introduction
As humans, we know how it feels to look at the world with one eye. We can easily experience this by closing one eye, or when looking at a picture. The world clearly appears to us as three-dimensional (3D), but there is something that still feels somewhat flat. We also know what it is to look at the world with two eyes. Objects and scenes appear and feel 3D. We sense the volume of the space. In fact, even when we look with both of our eyes at a flat surface we feel it is 3D as we can feel how far the surface is and what is its orientation. But we do not know what it is to look at the world with three or more eyes. We can try to make guesses about what new sensations we might feel, but we are likely to fall short in truly understanding how it feels to see world through many eyes. It’s like someone with one eye trying to envision seeing the world with two; we can make guesses, but our comprehension will be limited.
Looking at an object simultaneously with many eyes surrounding the object, we will not only feel its 3D but also its wholeness in a way hard to imagine with only two eyes. For us, only one side of the object is visible at any given time. We can turn around an object to see all of its sides, but that will not compare with the simultaneous perception of all its sides.
Multiview geometry studies the 3D reconstruction of an object or a scene when captured from \(N\) cameras (with \(N>2\)).
44.2 Structure from Motion
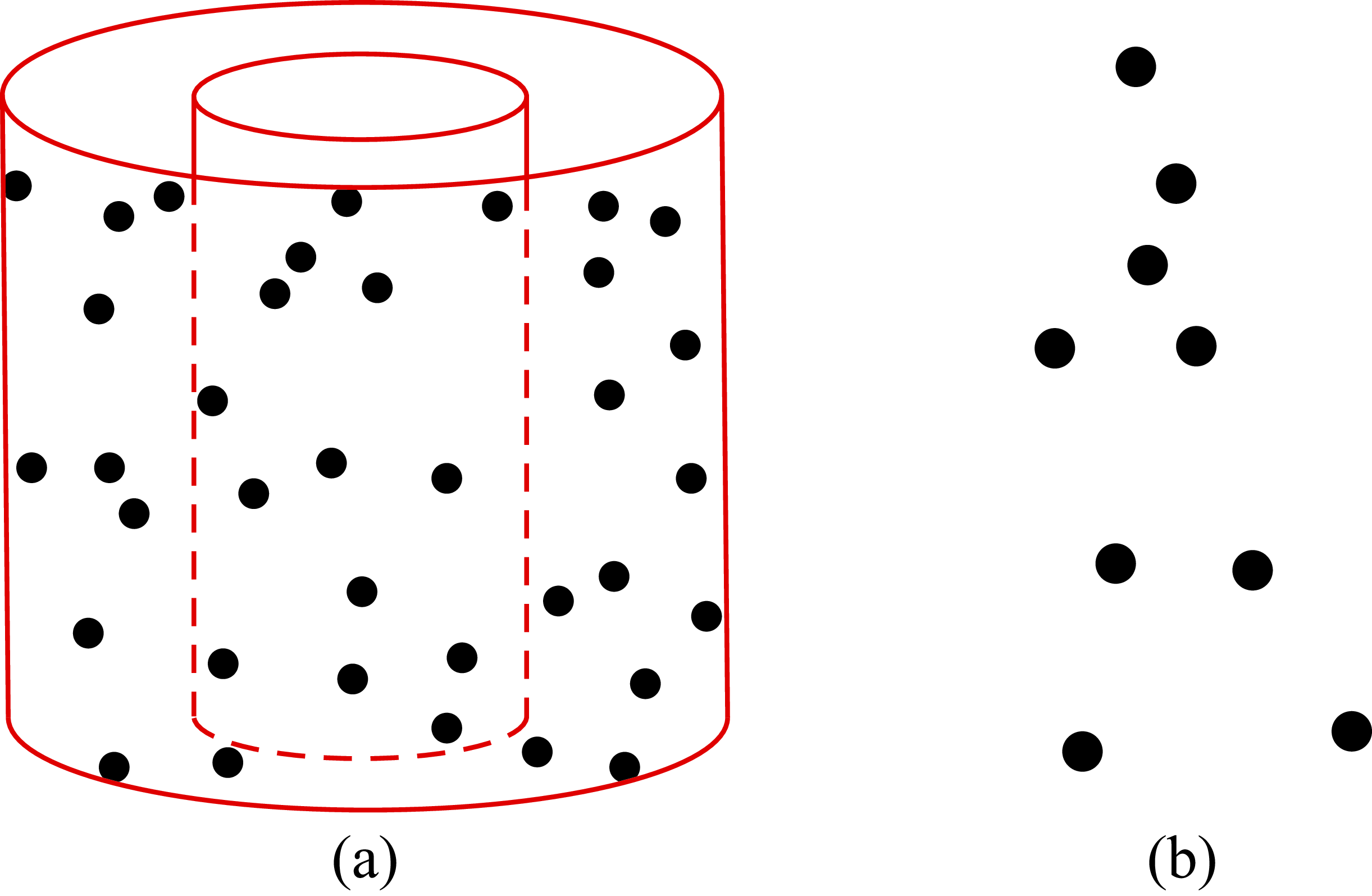
In 1971, Gunnar Johansson created a series of beautiful videos by recording the movements of a person with a set of lights attached to few of the body joints (e.g., elbows, knees, feet, head, and hands as illustrated in Figure 44.1[b]).
Gunnaar Johansson was a Swedish psychologist working on gestalt laws of motion perception. He introduced the term of biological motion to describe the typical motion of biological organisms.
Johansson [1] demonstrated that by watching the motion of only a few of those points, no more than 12, it was possible to clearly recognize the person actions. By showing only moving points, Johansson dissociated the perception of form/shape from the motion pattern. Johansson’s videos were very surprising at the time and researchers were stunned by how easy was to recognize many types of actions from just a few moving points. Since then, Johansson’s early demonstrations have been used to argue about the importance of reliably tracking a few points over time.
One major advance that allowed writing a mathematical formulation of the problem of structure from motion (SFM) was the rigidity assumption introduced by Shimon Ullman in 1979 [2] where he writes: “Any set of elements undergoing a two dimensional transformation which has a unique interpretation as a rigid body moving in space should be interpreted as such a body in motion.” Since then, the 3D reconstruction of rigid objects from camera motion has been a rich area of work. Most of the works start by representing the sequence using as input the temporal trajectories of a sparse set of points (sparse SFM). Figure 44.1 [a] shows one frame from the nested cylinders sequence. In this sequence, there are a set of points placed on the surface of two nested cylinders. The cylinders are rotating. When viewing the sequence it is easy to see both cylinders, even though when seeing any single frame (as shown in Figure 44.1[a]) it is hard to see the cylinders or even to say which points are attached to the same surface.
One of the first algorithms for structure from motion for rigid bodies was introduced by Tomasi and Kanade [3]. For simplicity, their approach assumed parallel projection (orthographic camera) instead of perspective projection. The algorithm took as input a video sequence captured by a moving camera looking at a static scene. The video was first processed by extracting keypoints and tracking them over time. The input to the reconstruction algorithm was the keypoint trajectories and the output was the 3D locations of those points with respect to a reference world-coordinate system (usually defined by the first frame in the video). The model introduced by Tomasi and Kanade was later extended by Sturm and Triggs [4] to handle perspective projection.
One of the key problems in SFM is to find correspondences across multiple images. Finding image correspondences is a topic that we have already mentioned in multiple places (e.g., Chapter 40 and Chapter 41 and that will be mentioned again (chapter Chapter 48).
SIFT [5] made image matching more reliable and structure from motion started to work much better under difficult conditions such as where views are captured by cameras at very different locations, which is a more difficult image matching than when the views are frames from one sequence.
The task of SFM became more general, and instead of focusing on one moving camera, SFM was applied to the problem of reconstructing the 3D scene even from multiple images taken by different cameras and making no assumption about the placement of the cameras. The work by Snavely et al. [6] was one of the first to produce spectacular registrations and camera pose estimates of images taken with many different cameras. They showed how one could reconstruct famous buildings from pictures taken by tourists.
In the last decade, deep learning now provides a more robust set of features for finding image correspondences, which is one of the key elements of the SFM algorithms.
44.3 Sparse SFM
Let’s start defining the notation and the formulation of the problem we want to solve; given a set of \(M\) images with overlapping content, we want to recover the 3D structure of the scene and the location of the camera for each image. Figures Figure 44.2 and Figure 44.3 show two examples of sets of images. Figure 44.2 shows 12 images of an object taken by a camera moving around the object. Figure 44.3 shows eight images taken inside a plaza. Both sets of images represent very different scenarios that will be reconstructed with the same set of techniques.




















44.3.1 Problem Formulation
In the sparse SFM problem, we consider that in the scene there are \(N\) distinct points (with \(N\) smaller than the number of pixels on each image) that are matched across \(M\) different views (we will consider later that not all points may be visible across all images). We denote the \(N\) 3D points as \(\mathbf{P}_i\).
Notation reminder: we use capital letters for quantities measured in 3D world coordinates and lowercase for image coordinates.
For each of the \(M\) views (it could be different cameras or different pictures taking by a moving camera), we denote the projection of point \(\mathbf{P}_i\) as seen by camera \(j\) by \(\mathbf{p}^{(j)}_i\). Each view has camera parameters \({\mathbf K}^{(j)}\), \({\mathbf R}^{(j)}\), and \({\mathbf T}^{(j)}\). If all the images are captured by the same camera, then the matrices \({\mathbf K}^{(j)}\) will be the same. In general it is not necessary to make that assumption.
The goal of the SFM problem is, given the set of corresponding 2D points \(\mathbf{p}^{(j)}_i\), recover 3D points \(\mathbf{P}_i\), the intrinsic camera parameters, \({\mathbf K}^{(j)}\), and the extrinsic camera parameters \({\mathbf R}^{(j)}\) and \({\mathbf T}^{(j)}\), for each camera \(j\).
We will next study what is the minimal number of observations that we need to have any hope of being able to solve the problem. Let’s assume that we have calibrated cameras, that is, we know the intrinsic camera parameters for each image, \({\mathbf K}^{(j)}\). We will first count the number of unknowns that we have. We have two sets of unknowns: the 3D coordinates of the \(N\) points and the extrinsic camera parameters for the \(M\) images.
This results in 3\(N\) unknowns for the \(N\) 3D points. For the camera parameters, we assume that the first camera is at the origin. Therefore, we need to figure out the camera matrices for \(M-1\) cameras. The rotations can be specified with three numbers, which results in \(3(M-1)\) unknowns. The translations (up to a scale factor) result in \(3(M-1)-1\) unknowns. This gives a total of \(3N + 6(M-1)-1\) unknowns.
If we have the image coordinates of the \(N\) points across the \(M\) images, we would have \(2NM\) observations (in reality we will have less as some points will only be visible in a subset of the images). So, there is a solution when, \[2NM \geq 3N + 6(M-1)-1\] Note that if \(M=1\),only points captured by one camera are available, then we can not solve the problem. If cameras are uncalibrated, this will add \(3M\) additional unknowns (the exact number of additional unknowns will depend on the camera type).
In the previous description, we are making the assumption that every point is visible in every view (so one can run fundamental matrix estimation, triangulation, and other tasks of each of the \(M-1\) cameras with respect to the first view). However, if the visibility criteria isn’t met, for each new image we are adding in to SFM, we will need to triangulate it with respect to its closest image – when doing so, we may have a slight numerical error, and this new frame may end up having an ever-so-slightly different scale factor with respect to the reconstruction. This accumulates over time, causing scale drift.
44.3.2 Reprojection Error
We already introduced the reprojection error in section Section 39.7.4 when talking about camera calibration. Here the formulation is similar but we optimize over a different set of unknowns. The reprojection error is the sum of euclidean distances (in heteregenous coordinates) between the observed image points \(\mathbf{p}^{(j)}_i\) and the estimated projected points \(\hat{\mathbf{p}}^{(j)}_i\)
\[\sum_{j=1}^M \sum_{i=1}^N \left\lVert \mathbf{p}^{(j)}_i - \hat{\mathbf{p}}^{(j)}_i \right\rVert ^2\] The estimated projected points are obtained using the estimated 3D points locations \(\mathbf{P}^{(j)}_i\) and the estimated camera matrices \(\mathbf{M}^{(j)}\), \[\sum_{j=1}^M \sum_{i=1}^N \left\lVert \mathbf{p}^{(j)}_i - \pi \left( \mathbf{M}^{(j)} \mathbf{P}^{(j)}_i \right) \right\rVert ^2 \tag{44.1}\] where \(\pi()\) is the function that transforms a vector described with homogeneous coordinates into the corresponding vector in heterogeneous ones.
We can make the camera model explicit in equation (Equation 44.1) by replacing the camera matrix, \(\mathbf{M}^{(j)}\). By using the intrinsic and extrinsic camera matrices we get:
\[\sum_{j=1}^M \sum_{i=1}^N\left\lVert \mathbf{p}^{(j)}_i - \pi \left( \mathbf{K}^{(j)} \begin{bmatrix} \mathbf{R}^{(j)} ~ \mid ~ -\mathbf{R}^{(j)}\mathbf{T}^{(j)} \end{bmatrix} \mathbf{P}^{(j)}_i \right) \right\rVert ^2 \]
To have the final error we still need to add one more factor. We add a visibility term, \(v_i^{(j)}\), to account for 3D points that are only be visible in a subset of the views. We will use the binary variable \(v_i^{(j)}\) to indicate if point \(i\) is seeing from camera \(j\). For all the points that are not visible in a view we set \(v_i^{(j)}=0\), that is, their reprojection error is ignored. This can be written as: \[\sum_{j=1}^M \sum_{i=1}^N v_i^{(j)} \left\lVert \mathbf{p}^{(j)}_i - \pi \left( \mathbf{K}^{(j)} \begin{bmatrix} \mathbf{R}^{(j)} ~ \mid ~ -\mathbf{R}^{(j)}\mathbf{T}^{(j)} \end{bmatrix} \mathbf{P}^{(j)}_i \right) \right\rVert ^2 \tag{44.2}\] and this gives us the final reprojection error equation. One common simplification is to assume that all the cameras have the same intrinsic parameters, which means that \(\mathbf{K}^{(j)}=\mathbf{K}\). This is the case when the views have been captured by a moving camera with a fixed focal length. The optimization of the reprojection error is also called bundle adjustment.
The term bundle adjustment refers to the process of optimizing the “bundle of rays” connecting the camera centers and the coordinates of the 3D points.
When optimizing equation (Equation 44.2) there are a number of ambiguities that cannot be recovered. Those include a global translation and rotation of the world-coordinate system, the global scale, and a projective ambiguity when \(\mathbf{K}\) is unknown.
There are two main challenges in SFM. The first challenge is that we need reliable matching points, and the second challenge is optimizing equation (Equation 44.2), which is difficult due to local minima and to noisy matches.
44.3.3 Finding Matches across Images
When describing stereo vision in Chapter 40 we had to find matching points across two views in order to recover depth, but we did not spend much time on the problem of matching points across images. Matching features across views in a stereo pair is challenging, but it is easy in comparison with the challenge of matching points in a multiview setting. Now we will have to match points across views that might be very different, with little overlap and with dramatic camera motions. Therefore, we will need a more robust way to match points.
44.3.3.1 Interest point detector
The goal of finding image features is to locate image locations that are likely to be stable under different sets of geometric transformations (translation, scaling, rotation, skew, and projective), and illumination changes. These stable regions are called interest points.
Initially, interest points were called moving elements. A moving element was any image point that could be identified and followed over time such as a corner, a line termination point, or a texture element [2].
When talking about stereo matching we described a simple procedure to detect interest points: the Harris corner detector [7]. Corners are examples of image regions that are likely to be distinct from the image surroundings and also be stable under geometric transformations (i.e., corners remain corners under a number of transformations). There are a number of other important detectors of regions of interest, in addition to the Harris corner detector, such as local extrema of the Laplacian pyramid across space and scale [8], [5], Harris-Laplace [9], and maximally stable regions [10]. For an in depth description of interest point detectors and their evaluation we refer the reader to the work of Cordelia Schmid et al. [11] and Mikolajczyk [8].
More recently, the problem of detecting points of interest has been formulated as a learning problem. Given a set of examples of points of interest manually annotated on images, we can train a classifier to automatically label image patches as being centered on a keypoint or not. Some examples of learning-based approaches are Quad-Networks [12], and SuperPoint [13].
Figure 44.4 illustrates a general formulation for detecting keypoints using a classifier. We start by training a classifier using hand-annotated images with keypoints. This can be done by generating simple synthetic images were keypoints are unambiguously defined. The training set can be extended by running an initial keypoint detector on images and then augmenting the images with random geometric transformations. Then we can use the transformed keypoint coordinates together with the transformed images as new ground truth to train a more robust classifier. This is the approach proposed by SuperPoint [13].

Figure 44.5 shows the resulting detected keypoints by SuperPoint on three viewpoints of the sugar bowl. The images shown in Figure 44.2 seem to lack texture. Interestingly, when we zoom into the images (which are very high-resolution) we can see that the surface contains many irregularities that are detected by the keypoints classifier (Figure 44.6 [a]). If the surface of the bowl was smooth and textureless, the method would fail to detect any interesting points, and the whole pipeline for 3D reconstruction would fail.
The keypoints detected on the plaza scene, shown in Figure 44.6 (b), correspond to more obvious keypoints, such as window corners, bricks, and other building details, than the ones detected on the sugar bowl.


The advantage of hand-engineered detectors is that they are derived from first principles and do not require any training data. However, learning-based detectors can leverage unsupervised learning to achieve state of the art performance.
44.3.3.2 Local image descriptors
Once we have trained a keypoint detector that finds image regions that are distinct and likely to be stable under geometric transformations, we run the detector in the set of images we want to match. We need now to extract at each location a descriptor that will allow finding the same keypoint across the different images.
In Chapter 40 we described SIFT [5] as a local image descriptor. Other classical descriptors are SURF [14], and ORB [15]. For a review of several hand-engineered descriptors and their evaluation, we refer the reader to the work of Krystian Mikolajczyk and Cordelia Schmid [16]. Figure 44.7 shows three interest points in the suggar bowl and the three associated descriptors. In this example, each descriptor is a vector of length 256.

As shown in Figure 44.8, the keypoint detector and descriptor finds image regions and its matches even under different viewpoints and illumination conditions. The top row of Figure 44.8 [a] shows the location of a matching keypoint across six views of the sugar bowl (this keypoint was not detected in the remaining six images). The bottom row shows crops of size \(129 \times 129\) pixels around the keypoint. The larger crops allow better getting a sense of the context of each keypoint. Figure 44.8 [b] shows the same for the plaza scene. In this case the keypoint detects the same window corner across multiple views.


We perform brute-force matching, that is, match features from one image with features from every other image because we have a small number of images. For the actual matching shown in this section, we use SuperGlue, another graph network-based matcher.
44.3.4 Optimization
The matching procedure should have given as a set of image points \(\mathbf{p}^{(j)}_i\) and visibility indicators \(v_i^{(j)}\). Each location will also have a feature, \(\mathbf{f}^{(j)}_i\), associated to it.
There are many different ways in which one can attempt to minimize the loss from equation (Equation 44.2). One standard approach is to do it incrementally starting with only a pair of images. We use the matches between those two images to compute the fundamental and essential matrices, while accounting for outliers using RANSAC. We can then compute an initial 3D reconstruction of the matched points using triangulation as we have already discussed in Chapter 40. Then, we add another image and we repeat the same process until we have incorporated all the images. This process will result in a first set of approximated camera poses and 3D locations for a subset of the detected keypoints.
To find the final set of 3D points, the camera poses and the 3D locations of the keypoints are then further refined by bundle adjustment (camera intrinsics are refined too, if needed). The reprojection error loss is usually rewritten using a robust cost function (typically the Huber kernel).
Figure 44.9 and Figure 44.10 show the final 3D reconstructions and recovered camera locations for the two sets of images that we have used in this chapter.



SFM is predominantly performed in one of two modes: the incremental mode; and the batch model offline or batch-mode SFM approaches, which compute the scene structure after processing all input images. In this mode, bundle adjustment will only need to be run once, albeit across a potentially large number of cameras and 3D points. This mode allows leverages images from all available viewpoints right from the outset. However, if new images are added the entire SFM pipeline needs to be rerun.
Online, or incremental-mode SFM approaches attempt to estimate scene structure and camera parameters as and when a new image arrives. In this mode, bundle adjustment is run periodically, whenever a sufficient number of points have been newly added. Incremental-mode SFM is often used in applications where all images are not available a priori, or where real-time performance is desired.
44.4 Concluding Remarks
Multiview reconstruction is an active field of research with a wide range of applications in vision, graphics and healthcare. While a sparse SFM pipeline results in accurate 3D reconstruction, several applications (such as robotics and computer graphics) require dense 3D scene representations. The goal of dense SFM, not covered here, is to reconstruct every pixel from every image, as opposed to the sparse SFM systems described previously that only reconstruct a subset of pixels.
In this chapter, we focused on the most popular variant of SFM used today — feature-based, or sparse, SFM. In sparse SFM, the 3D reconstruction is computed only for a small subset of the image pixels — distinct points that may be detected reliably and repeatably across camera pose variations. SFM approaches have also attempted to leverage other kinds of features, such as lines, planes, or objects. Point-based features remain the most popular choice due to their geometric simplicity, and the availability of a wide range of point feature detectors and descriptors.
In dense SFM, the 3D reconstruction is computed for every (or most) of the image pixels. The resulting 3D reconstructions are rich and visually informative, and are useful in applications like robot navigation or mixed reality. Dense SFM approaches usually optimize photometric error, that is, the difference in grayscale or red-green-blue (RGB) intensities of corresponding pixels across images. This is in contrast to the point feature-based methods we looked at in this chapter that minimize a 3D reprojection error. However, these dense SFM techniques tend to be much slower than the sparse SFM methods, and often require more assumptions about the scene or the images, such as the scene being Lambertian (i.e., the grayscale or RGB intensity of a 3D point is invariant to the viewing direction) or the images having a substantially smaller baseline motion compared to the range of motions a point feature-based SFM approach can handle. We will talk about dense optimization of the photometric error when discussing motion estimation in Part Understanding Motion.