40 Stereo Vision
40.1 Introduction
Figure 40.1 (a) shows a stereo anaglyph of the ill-fated ocean liner, the Titanic, from [1]. This was taken with two cameras, one displaced laterally from the other. The right camera’s image appears in red in this image, and the left camera image is in cyan. If you view this image with a red filter covering the left eye, and a cyan filter covering the right (Figure 40.1[b]) then the right eye will see only the right camera’s image (analogously for the left eye), allowing the ship to pop-out into a three-dimensional (3D) stereo image. Note that the relative displacement between each camera’s image of the smokestacks changes as a function of their depth, which allows us to form a 3D interpretation of the ship when viewing the image with the glasses (Figure 40.1[b]).

In this chapter, we study how to compute depth from a pair of images from spatially offset cameras, such as those of Figure 40.1. There are two parts to the depth computation, usually handled separately: (1) analyzing the geometry of the camera projections, which allows for triangulating depth once image offsets are known; and (2) calculating the offset between matching parts of the objects depicted in each image. Different techniques are used in each part. We first address the geometry, asking where points matching those in a first image can lie in the second image. A manipulation, called image rectification, is often used to place the locus of potential matches along a pixel row. Then, assuming a rectified image pair, we will address the second part of the depth computation, computing the offsets between matching image points.
40.2 Stereo Cues
How can we estimate depth from two pictures taken by two cameras placed at different locations? Let’s first gain some intuition about the cues that are useful to estimate distances from two views captured at two separate observation points.
40.2.1 How Far Away Is a Boat?
To give an intuition on how depth from stereo vision works, let’s first look at a simple geometry problem of practical use: How do we estimate how far away a boat is from the coast?
Sailors can use tricks to estimate distances using methods related to the ones presented in this chapter. These techniques can be useful when the electronics on the boat are out.
We can solve this problem in several ways. We will briefly discuss two methods. The first one uses a single observation point but will use the horizon line as a reference. The second method will use two observation points. Both methods are illustrated in Figure 40.2.
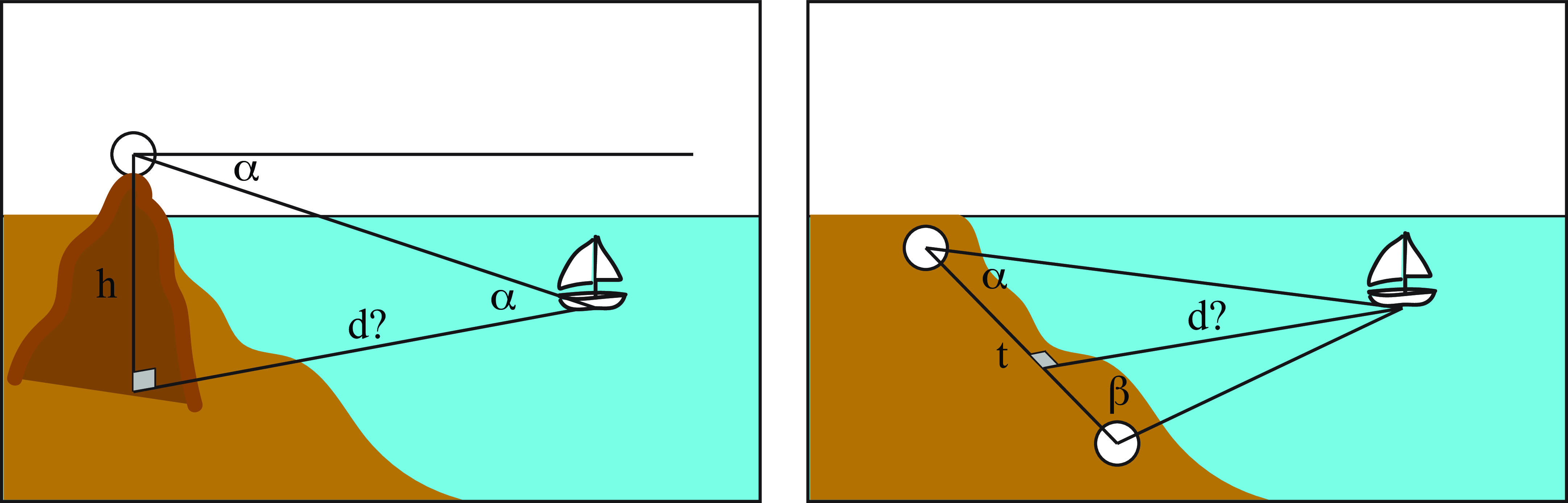
The first method measures the location of the boat relative to the horizon line. An observer is standing on top of an elevated point (a mountain, tower, or building) at a known height, \(h\). The observer measures the angle \(\alpha\) between the horizontal (obtained by pointing toward the horizon) and the position of the boat. We can the derive the boat distance to the base of the point of observation, \(d\) by the simple trigonometric relation: \[d = \frac{h}{\tan (\alpha)}\] This method isnot very accurate and might require high observation points, which might not be available, but it allows as to estimate the boat position with a single observation point, if the observer’s height above the water is known. It also requires incorporating the earth curvature when the boat is far away.
The second method requires two different observation points along the coast separated by a distance \(t\). At each point, we measure the angles, \(\alpha\) and \(\beta\), between the direction of the boat and the line connecting the two observation points. Then we can apply the following relation: \[d = t \frac{\sin (\alpha) \sin (\beta)}{\sin (\alpha+\beta)}\] This method is called triangulation. For it to work we need a large distance \(t\) so that the angles are significantly different from \(90\) degrees.
40.2.2 Depth from Image Disparities
When observing the world with two eyes we get two different views of the world (Figure 40.1). The relative displacement of features across the two images (parallax effect) is related to the distance between the observer and the observed scene. Just as in the example of estimating the distance to boats in the sea, our brain uses disparities across the two eye views to measures distances to objects.
**Free fusion* consists in making the eyes converge or diverge in order to fuse a stereogram without needing a stereoscope. Making it work requires practice. Try it in Figure 40.3.
Our brain will use many different cues such as the ones presented in the previous chapter. But image disparity provides an independent additional cue. This is illustrated by the random dot stereograms (Figure 40.3) introduced by Bela Julesz [2]. Random dot stereograms are a beautiful demonstration that humans can perceive depth using the relative displacement of features across two views even in the absence of any other depth cues. The random images contain no recognizable features and are quite different from the statistics of the natural world. But this seems not to affect our ability to compute the displacements between the two images and perceive 3D structure.

40.2.3 Building a Stereo Pinhole Camera
Stereo cameras generally are built by having two cameras mounted on a rigid rig so that the camera parameters do not change over time.
We can also build a stereo pinhole camera. As we discussed in Chapter 5, a pinhole camera is formed by a dark chamber with a single hole in one extreme that lets light in. The light gets projected into the opposite wall, forming an image. One interesting aspect of pinhole cameras is that you can build different types of cameras by playing with the shape of the pinhole. So, let’s make a new kind of pinhole camera! In particular, we can build a camera that produces anaglyph images, like the one in Figure 40.1, in a single shot by making two pinholes instead of just one.
We will transform the pinhole camera into an anaglyph pinhole camera by making two holes and placing different color filters on each hole (Figure 40.4). This will produce an image that will be the superposition of two images taken from slightly different viewpoints. Each image will have a different color. Then, to see the 3D image we can look at the picture by placing the same color filters in front of our eyes. In order to do this, we used color glasses with blue and red filters.

We used one of the anaglyph glasses to get the filters and placed them in front of the two pinholes. Figure 40.4 shows two pictures of the two pinholes (Figure 40.4[a]) and the filters positioned in front of each pinhole (Figure 40.4[b]). Figure 40.4 (d) is a resulting anaglyph image that appears on the projection plane (Figure 40.4[c]); this picture was taken by placing a camera in the observation hole seen at the right of Figure 40.4 (c). Figure 40.4 (d) should give you a 3D perception of the image when viewed with anaglyph glasses.
Here are experimental details for making the stereo pinhole camera. You will have to experiment with the distance between the two pinholes. We tried two distances: 3 in and 1.5 in. We found it easier to see the 3D for the 1.5 in images. Try to take good quality images. Once you have placed the color filters on each pinhole, you will need longer exposure times in order to get the same image quality than with the regular pinhole camera because the amount of light that enters the camera is smaller. If the images are too blurry, it will be hard to perceive 3D. Also, as you increase the distance between the pinholes, you will increase the range of distances that will provide 3D information because the parallax effect will increase. But if the images are too far apart, the visual system will not be able to fuse them and you will not see a 3D image when looking with the anaglyph glasses.
Let’s now look into how to use two views to estimate the 3D structure of the observed scene.
40.3 Model-Based Methods
Let’s now make more concrete the intuitions we have built in the previous sections. We will start describing some model-based methods to estimate 3D from stereo images. Studying these models will help us understand the sources of 3D information, the constraints, and limitations that exist.
40.3.1 Triangulation
The task of stereo is to triangulate the depth of points in the world by comparing the images from two spatially offset cameras.
If more than two cameras are used, the task is referred to as multiview stereo.
To triangulate depth, we need to describe how image positions in the stereo pair relate to depth in the 3D world.
We will start with a very simple setting where both cameras are identical (same intrinsic parameters) and one is translated horizontally with respect to the other so that their optical axes are parallel, as shown in Figure 40.5. We also will assume calibrated cameras. The geometry shown in Figure 40.5 reveals the essence of depth estimation from the two cameras. Let’s assume that there is one point, \(\mathbf{P}\), in 3D space and we know the locations in which it projects on each camera, \([x_L,y_L]^\mathsf{T}\) for the left camera and \([x_R,y_R]^\mathsf{T}\) for the right camera, as shown in Figure 40.5 a. Because the two cameras are aligned horizontally, the \(y\)-coordinates for the projection in both cameras will be equal, \(y_L=y_R\). Therefore, we can look at the top view of the setting as shown in Figure 40.5 b. We consider the depth estimate within a single image row.
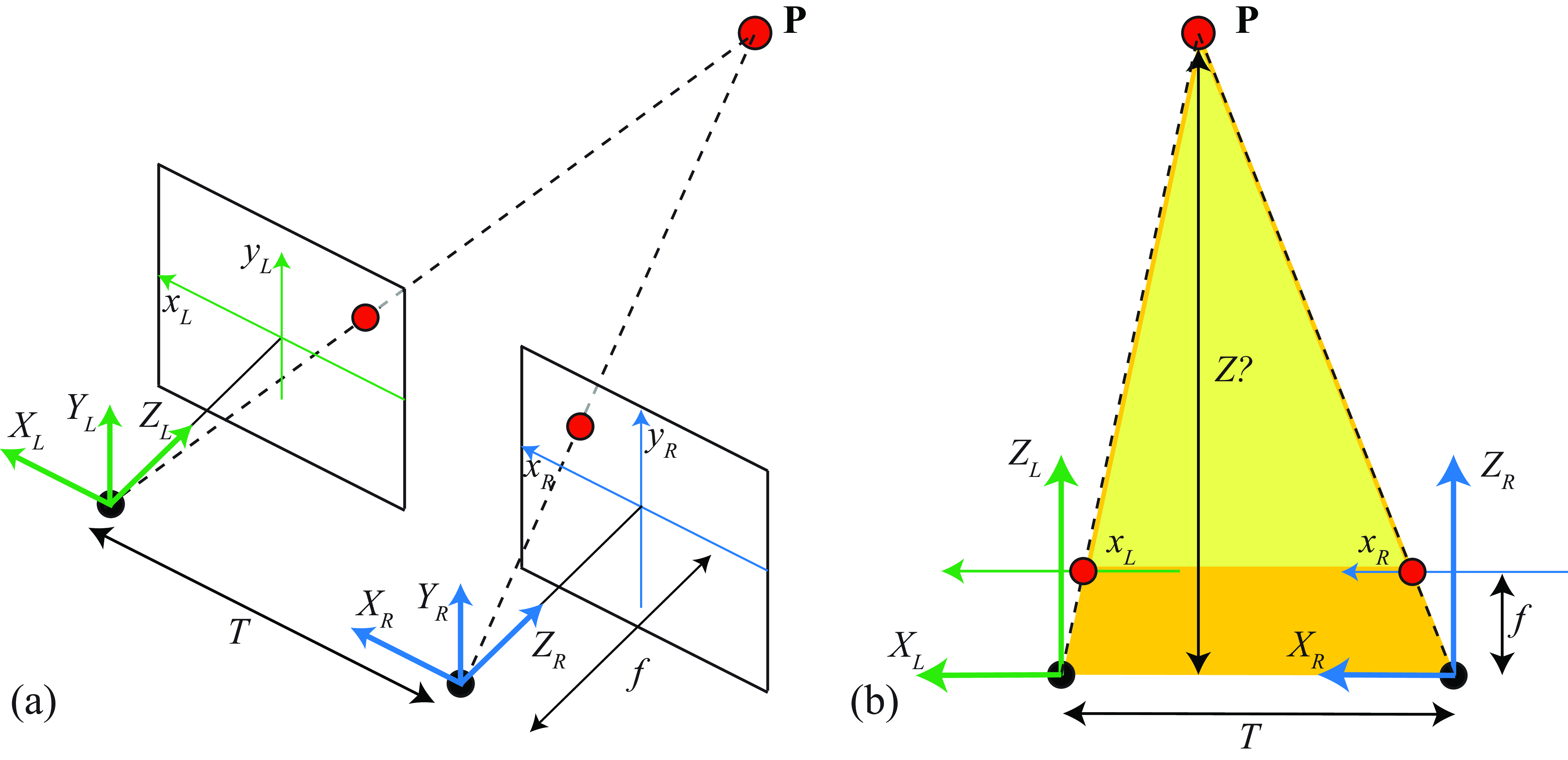
The point \(\mathbf{P}\), for which we want to estimate the depth, \(Z\), appears in the left camera at position \(x_L\) and in the right camera at position \(x_R\).
To distinguish 2D image coordinates from 3D world coordinates, for this chapter, we will denote 2D image coordinates by lowercase letters, and 3D world coordinates by uppercase letters.
A simple way to triangulate the depth, \(Z\), of a point visible in both images is through similar triangles. The two triangles (yellow triangle and yellow+orange triangle) shown in Figure 40.5 (b) are similar, and so the ratios of their height to base must be the same. Thus we have: \[\frac{T+x_R-x_L}{Z-f} = \frac{T}{Z}\] Solving for \(Z\) gives: \[Z = \frac{fT}{x_L-x_R} \tag{40.1}\] The difference in horizontal position of any given world point, \(\mathbf{P}\), as seen in the left and right camera images, \(x_L - x_R\), is called the disparity, and is inversely proportional to the depth \(Z\) of the point \(\mathbf{P}\) for this configuration of the two cameras–parallel orientation. The task of inferring depth of any point in either image of a stereo pair thus reduces to measuring the disparity everywhere.
However, we are far from having solved the problem of perceiving 3D from two stereo images. One important assumption we have made is that we know the two corresponding projections of the point \(\mathbf{P}\). But in reality the two images will be complex and we will not know which points in one camera correspond to the same 3D point on the other camera. This requires solving the stereo matching problem.
40.3.2 Stereo Matching
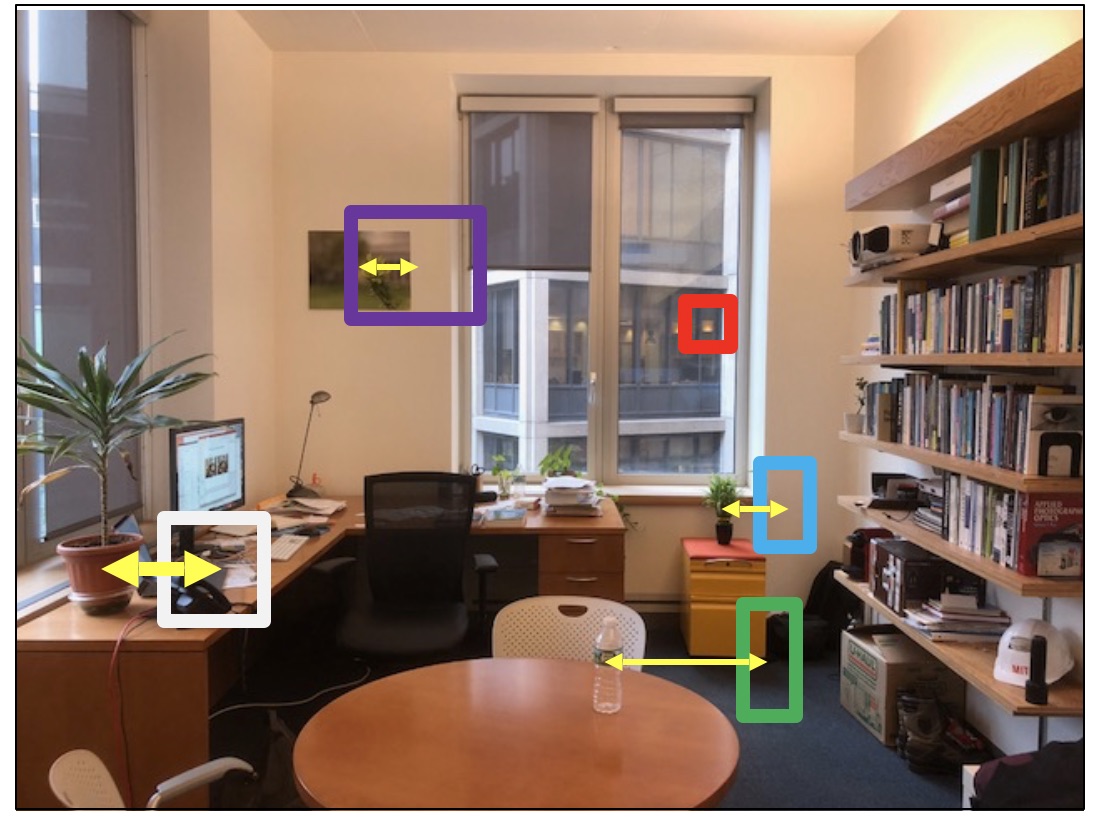
First, let’s examine the task visually. Figure 40.6 shows two images of an office, taken approximately 1 m apart. The locations of several objects in Figure 40.6 (a) are shown in Figure 40.6 (b), revealing some of the disparities that we seek to measure automatically. As the reader can appreciate by comparing the stereo images by eye, one can compute the disparity by first localizing a feature point in one image and then finding the corresponding point in the other image, based on the visual similarity of the local image region. To do this automatically is the crux of the stereo problem.

A naive algorithm for finding the disparity of any pixel in the left image is to search for a pixel of the same intensity in the corresponding row of the right image. Figure 40.7, from [3], shows why that naive algorithm won’t work and why this problem is hard. Figure 40.7 (a) shows the intensities of one row of the right-eye image of a stereo pair. The squared difference of the intensity differences from offset versions of the same row in the rectified left-eye image of the stereo pair is shown in Figure 40.7 (b), for a range of disparity offsets, plotted vertically, in a configuration known as the disparity space image [4]. The disparity corresponding to the minimum squared error matches are plotted in red. Note the disparities of the best pixel intensity matches show much more disparity variations than would result from the smooth surfaces depicted in the image; the local intensity matches don’t reliably indicate the disparity. Many effects lead to that unreliability, including: lack of texture in the image, which leads to noisy matches among the many nearly identical pixels; image intensity noise; specularities in the image which change location from one camera view to another; and scene points appearing in one image but not another due to occlusion. Figure 40.7 (d) shows an effective approach to remove the matching noise: blurring the disparity space image using an edge-preserving filter [3]. The best-matched disparities are plotted in red, and compare well with the ground truth disparities (Figure 40.7[f]), as labeled in the dataset [4].

Dataset from [4]
The task of finding disparity at each point is often broken into two parts: (1) finding features, and matching the features across images, and (2) interpolating between, or adjusting, the feature matches to obtain a reliable disparity estimate everywhere. These two steps are often called matching and filtering, because the interpolation can be performed using filtering methods.
We will describe next a classical method to find key points and extract image descriptors to find image correspondences. In chapter Chapter 44 we will describe other learning-based approaches.
40.3.2.1 Finding image features
Good image features are positions in the image that are easy to localize, given only the image intensities. The Harris corner detector [5] identifies image points that are easy to localize by evaluating how the sum of squared intensity differences over an image patch change under a small translation of the image. If the squared intensity changes quickly with patch translation in every direction, then the region contains a good image feature.
To derive the equation of the Harris corner detector we will compute image derivatives. Therefore, we will write an image as a continuous function on \(x\) and \(y\). The compute the final quantities in practice we will approximate the derivatives using their discrete approximations as discussed in chapter Chapter 18. Let the input image be \(\ell(x,y)\), and let the small translation be \(\Delta x\) in \(x\) and \(\Delta y\) in \(y\). Then, the squared intensity difference, \(E(\Delta x, \Delta y)\), induced by that small translation, summed over a small image patch, \(P\), is \[E(\Delta x, \Delta y) = \sum_{(x, y) \in P} \left( \ell(x,y) - \ell(x + \Delta x, y + \Delta y) \right)^2 \tag{40.2}\]
We expand \(\ell(x + \Delta x, y + \Delta y)\) about \(\ell(x, y)\) in a Taylor series: \[\ell(x + \Delta x, y + \Delta y) \approx \ell(x, y) + \frac{\partial \ell}{\partial x} \Delta x + \frac{\partial \ell}{\partial y} \Delta y\] Substituting the above into equation (Equation 40.2) and writing the result in matrix form yields \[E(\Delta x, \Delta y) \approx \left[ \Delta x ~~ \Delta y \right] \mathbf{M} \left[ \begin{array}{c} \Delta x \\ \Delta y \end{array} \right]\] where \[\mathbf{M} = \sum_{(n, m) \in P} \begin{bmatrix} (\frac{\partial \ell}{\partial x})^2 & \frac{\partial \ell}{\partial x} \frac{\partial \ell}{\partial y} \\ \frac{\partial \ell}{\partial x} \frac{\partial \ell}{\partial y} & (\frac{\partial \ell}{\partial y})^2 \end{bmatrix}\]
The smallest eigenvalue, \(\lambda_{\mbox{min}}\) of the matrix, \(\mathbf{M}\), indicates the smallest possible change of image intensities under translation of the patch in any direction. Thus, to detect good corners, one can identify all points for which \(\lambda_{\mbox{min}} > \lambda_c\), for some threshold \(\lambda_c\). The Harris corner detector has been widely used for identifying features to match across images, although they were later supplanted by the scale-invariant feature transform (SIFT) [6], based on maxima over a scale of Laplacian filter outputs. Figure 40.8 (a and b) show the result of the Harris feature detector to the images of Figure 40.6.



Figure 40.8 (a and b) reveal the challenges of the feature matching task: (1) not every feature is marked across both images, and (2) we need to decide which pairs of image features go together. Feature points are found, independently, in each of the stereo pair images (Figure 40.8). Detected Harris feature points [5] are shown as green dots. It is especially visible within the marked ellipses that not the same set of feature points is marked in each image. Figure 40.8 (c) shows a depth image resulting from a matched and interpolated set of feature points.
40.3.2.2 Local image descriptors
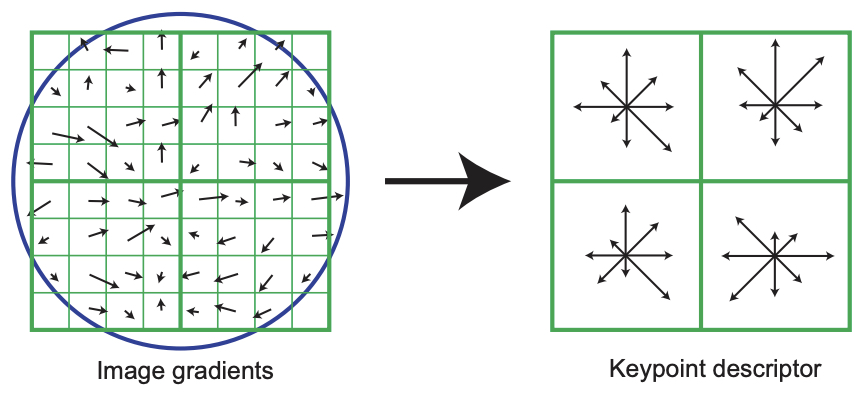
Matching corresponding image features require a local description of the image region to allow matching like regions across two images. SIFT [6] uses histograms of oriented filter responses to create an image descriptor that is sensitive to local image structure, but that is insensitive to minor changes in lighting or location which may occur across the two images of a stereo pair.
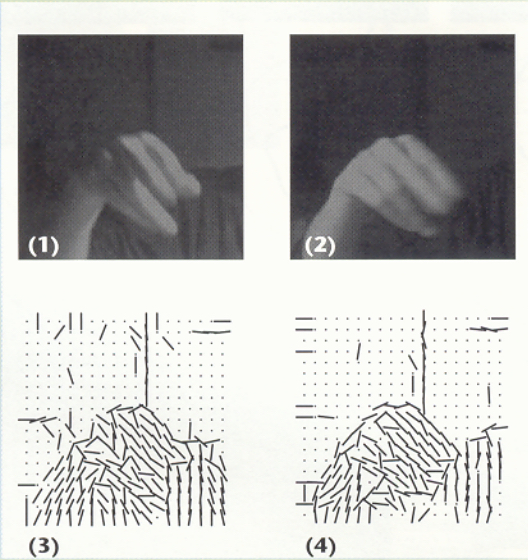
Figure 40.9 shows a sketch of the use of oriented edges and SIFT descriptors in image analysis. The top row of Figure 40.9 [a] shows two images of a hand under different lighting conditions. Despite that both images look quite different in a pixel intensity representation, they look quite similar in a local orientation, depicted in the bottom row by line segment directions. SIFT image descriptors [6] exploit that observation. Taking histograms (Figure 40.9[b]) of local orientation over local spatial regions further allow for image descriptors to be robust to small image translations [7], [6].
40.3.2.3 Interpolation between feature matches
Methods to interpolate depth between the depths of matched points include probabilistic methods such as belief propagation, discussed in Chapter 29. Under assumptions about the local spatial relationships between depth values, optimal shapes can be inferred provided the spatial structure over which inference is performed is a chain or a tree. Note that [8] uses a related inference algorithm, dynamic programming, which has the same constraints on spatial structure for exact inference. Hirschmuller’s algorithm, called semiglobal matching (SGM), applies the one-dimensional processing over many different orientations to approximate a global solution to the stereo shape inference problem.
40.3.3 Constraints for Arbitrary Cameras
Until now we have considered only the case where the two cameras are parallel, but in general the two images will be produced by cameras that can have arbitrary orientations. Note that disparity of the smokestacks in Figure 40.1 (a) increases with depth, rather than decreasing as described by equation (Equation 40.1). That is because the cameras that took the stereo pair were not in the same orientation, related only by a translation.
Let’s assume we have two calibrated cameras: we know the intrinsic and extrinsic parameters for both. They are related by a generic translation, \(\mathbf{T}\), and a rotation, \(\mathbf{R}\), such that their optical axis are not parallel. Let’s now consider that we see one point in the image produced by camera 1 and we want to identify where is the corresponding point in the image from camera 2. The following sketch (Figure 40.10) shows the setting of the problem we are trying to solve.
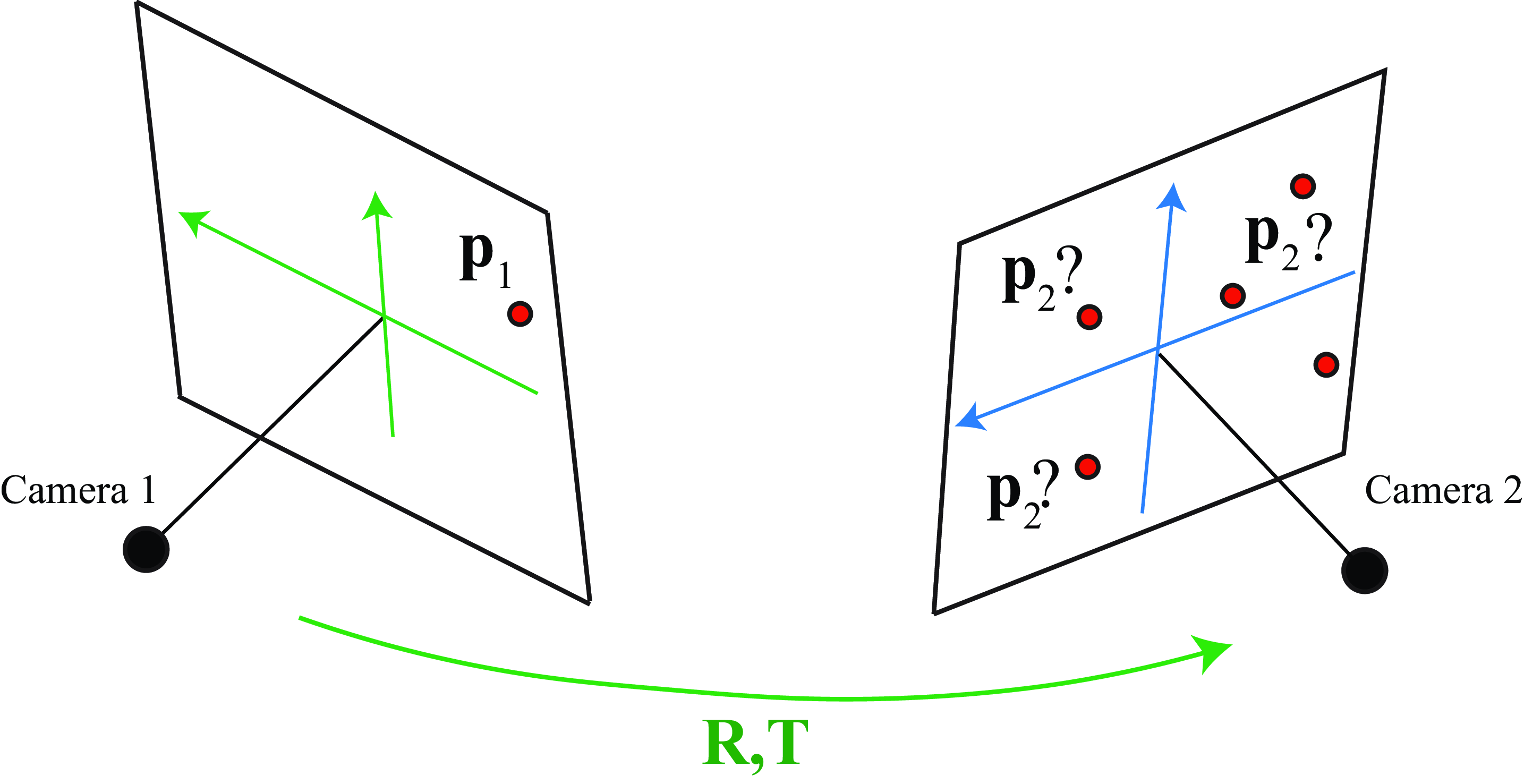
Are there any geometric constraints that can help us to identify candidate matches? We know that the observed point in camera 1, \(\mathbf{p}_1\), corresponds to a 3D point that lies within the ray that connects the camera 1 origin and \(\mathbf{p}_1\) (shown in red in Figure 40.11):
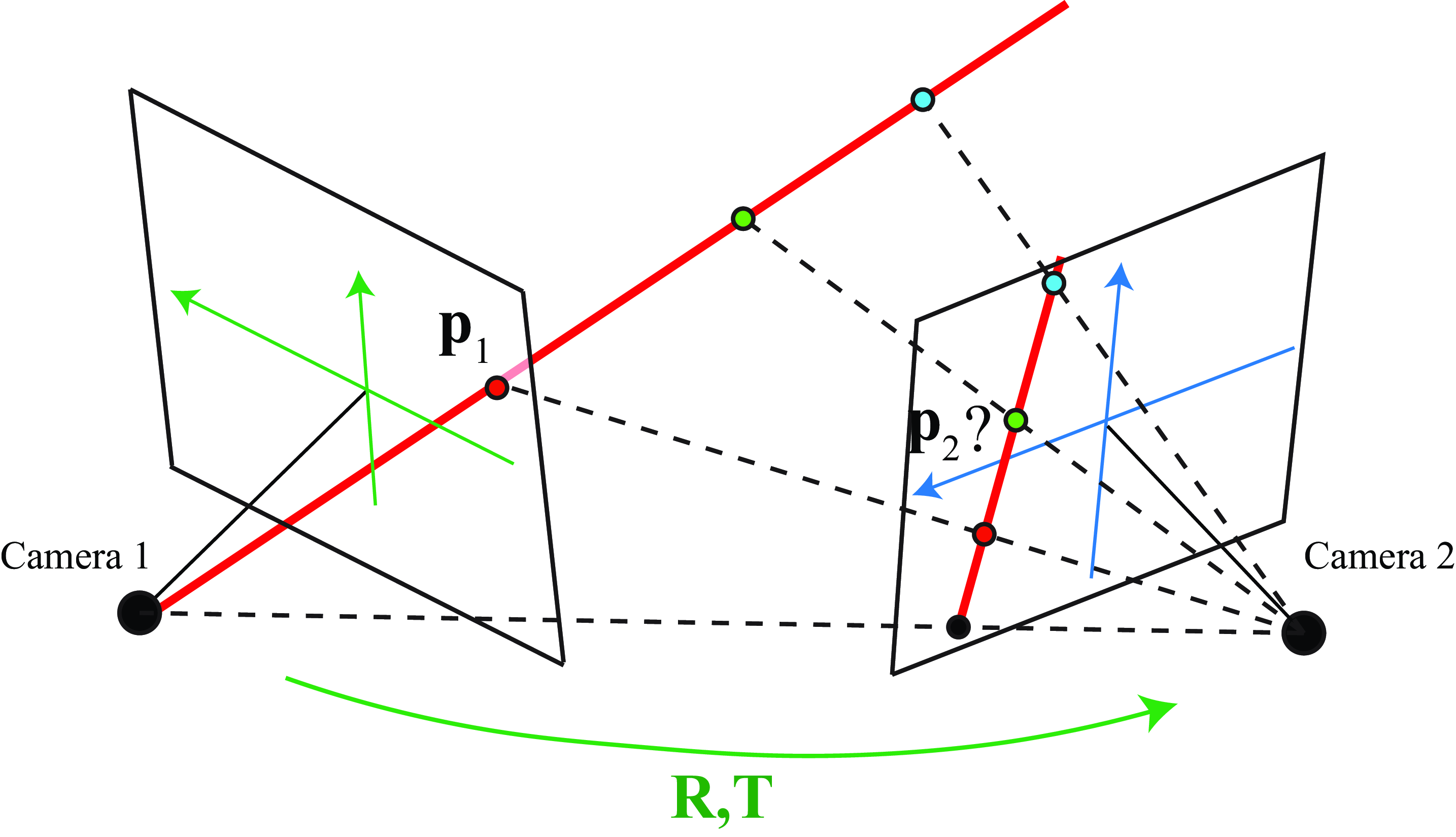
Therefore, \(\mathbf{p}_2\) is constrained to be within the line that results of projecting the ray into camera 2. Remember that a line in 3D projects into a line in 2D. There are two points that are of particular interest in the line projected into camera 2. The first point is the projection of the camera center of camera 1 into the camera plane 2 (the point could lay outside the camera view but in this example it happens to be visible). The second point is the projection of \(\mathbf{p}_1\) itself into camera 2. As we know all the intrinsic and extrinsic camera parameters, those two points should be easy to calculate. And these two points will define the equation of the line (there are many other ways to think about this problem).
The following figure shows the geometry of a stereo pair. Given a 3D point, \(\mathbf{P}\), in the world, we define the following objects:
The epipolar plane is the plane that contains the two camera origins and a 3D point, \(\mathbf{P}\).
The epipolar lines are the intersection between the epipolar plane and the camera planes. When the point \(\mathbf{P}\) moves in space, the epipolar plane and epipolar lines change.
The epipoles are the intersection points between the line that connects both camera origins and the camera planes. The epipoles’ location does not depend on the point \(\mathbf{P}\). Therefore, all the epipolar lines intersect at the same epipoles.
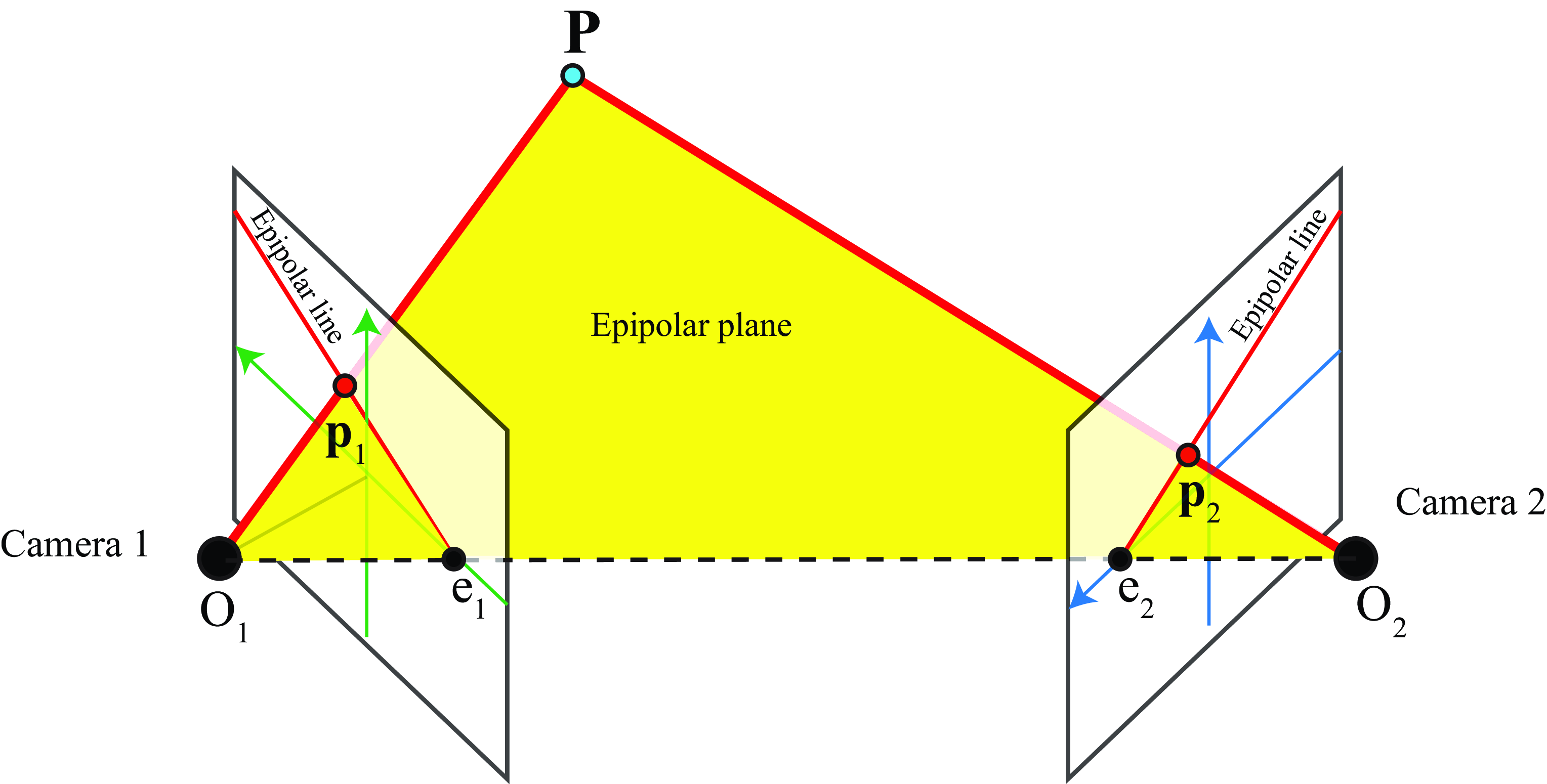
In the example shown in Figure 40.12, as both cameras are only rotated along their vertical axis and there is no vertical displacement between them, the epipoles are contained in the \(x\) axes of both camera coordinate systems. The epipolar line in camera 2, corresponds to the projection of the line \(O_1 P\) into the camera plane. Therefore, given the image point \(\mathbf{p}_1\), we know that the match should be somewhere along the epipolar line.
The epipolar line in camera 2 that corresponds to \(\mathbf{p}_1\) is uniquely defined by the camera geometries and the location of image point \(\mathbf{p}_1\). So, when looking for matches of a point in one camera, we only need to look along the corresponding epipolar line in the other camera. The same applies for finding matches in camera 1 given a point in camera 2.
In the next section we will see how to find the epipolar lines mathematically.
40.3.4 The Essential and Fundamental Matrices
We will follow here the derivation that was proposed by Longuet-Higgins, in 1981 [9]. Let’s consider a 3D point, \(\mathbf{P}\), viewed by both cameras. The coordinates of this 3D point \(\mathbf{P}\) are \(\mathbf{P}_1 = [X_1,Y_1,Z_1]^\mathsf{T}\) when expressed in the coordinates system of camera 1, and \(\mathbf{P}_2= [X_2,Y_2,Z_2]^\mathsf{T}\) when expressed in the coordinates system of camera 2. Both systems are related by (using heterogeneous coordinates): \[\mathbf{P}_2 = \mathbf{R} \mathbf{P}_1 + \mathbf{T} \tag{40.3}\]
The 3D point \(\mathbf{P}_1\) projects into the camera 1 at the coordinates \(\mathbf{p}_1 = f \mathbf{P}_1 /Z_1\) where \(\mathbf{p}_1\) is expressed also in 3D coordinates \(\mathbf{p}_1 = [f X_1/Z_1, f Y_1/Z_1, f]^\mathsf{T}\). Without losing generality we will assume \(f=1\).
Taking the cross product of both sides of equation (Equation 40.3) with \(\mathbf{T}\) we get: \[\mathbf{T} \times \mathbf{P}_2 = \mathbf{T} \times \mathbf{R} \mathbf{P}_1 \tag{40.4}\] as \(\mathbf{T} \times \mathbf{T} = 0\). And now, taking the dot product of both sides of equation (Equation 40.4) with \(\mathbf{P}_2\): \[\mathbf{P}_2^\mathsf{T}\mathbf{T} \times \mathbf{P}_2 = \mathbf{P}_2^\mathsf{T}\mathbf{T} \times \mathbf{R} \mathbf{P}_1\]The left side is zero because \(\mathbf{T} \times \mathbf{P}_2\) results in a vector that is orthogonal to both \(\mathbf{T}\) and \(\mathbf{P}_2\), and the dot product with \(\mathbf{P}_2\) is zero (dot product of two orthogonal vectors is zero). Therefore, \(\mathbf{P}_1\) and \(\mathbf{P}_2\) satisfy the following relationship: \[\mathbf{P}_2^\mathsf{T}\left( \mathbf{T} \times \mathbf{R} \right) \mathbf{P}_1 = 0\]
The cross product of two vectors \(\mathbf{a} \times \mathbf{b}\) can be written in matrix form as: \[ \mathbf{a} \times \mathbf{b} = \mathbf{a}_{\times} \mathbf{b} \] The special matrix \(\mathbf{a}_{\times}\) is defined as: \[ \mathbf{a}_{\times} = \begin{bmatrix} 0 & -a_3 & a_2 \\ a_3 & 0 & -a_1 \\ -a_2 & a_1 & 0 \\ \end{bmatrix} \] This matrix \(\mathbf{a}_{\times}\) is rank 2. In addition, it is a skew-symmetric matrix (i.e., \(\mathbf{a}_{\times} = -\mathbf{a}_{\times}^\mathsf{T}\)). It has two identical singular values and the third one is zero.
The matrix \(\mathbf{E}\) is called the essential matrix and it corresponds to: \[\mathbf{E} = \mathbf{T} \times \mathbf{R} = \mathbf{T}_{\times} \mathbf{R}\] This results in the relationship: \[\mathbf{P}_2^\mathsf{T}\mathbf{E} \mathbf{P}_1 = 0 \tag{40.5}\]
If we divide equation (Equation 40.5) by \(Z_1 Z_2\) we will obtain the same relationship but relating the image coordinates:
\[\mathbf{p}_2^\mathsf{T}\mathbf{E} \mathbf{p}_1 = 0 \tag{40.6}\] This equation relates the coordinates of the two projections of a 3D point into two cameras. If we fix the coordinates from one of the cameras, the equation reduces to the equation of a line for the coordinates of the other camera, which is consistent with the geometric reasoning that we made before.
The essential matrix is a \(3 \times 3\) matrix with some special properties:
\(\mathbf{E}\) has five degrees of freedom instead of nine. To see this, let’s count degrees of freedom: the rotation and translation have three degrees of freedom each, this gives six; then, one degree is lost in equation (Equation 40.6) as a global scaling of the matrix does not change the result. This results in five degrees of freedom.
The essential matrix has rank 2. This is because \(\mathbf{E}\) is the product of a rank 2 matrix, \(\mathbf{T}_{\times}\), and a rank 3 matrix, \(\mathbf{R}\).
The essential matrix has two identical singular values and the third one is zero. This is because \(\mathbf{E}\) is the product of \(\mathbf{T}_{\times}\), which has two identical singular values, and the rotation matrix \(\mathbf{R}\) that does not change the singular values.
As a consequence, not all \(3 \times 3\) matrices correspond to an essential matrix which is important when trying to estimate \(\mathbf{E}\).
40.3.4.1 The fundamental matrix
We have been using camera coordinates, \(\mathbf{p}\). If we want to use image coordinates, in homogeneous coordinates, \(\mathbf{c}=[n,m,1]^\mathsf{T}\), we need to also incorporate the intrinsic camera parameters (which will also incorporate pixel size and change of origin). Incorporating the transformation from camera coordinates, \(\mathbf{p}\), to image coordinates, \(\mathbf{c}\), the equation relating image coordinates in both cameras has the same algebraic form as in equation (Equation 40.6):
\[\mathbf{c}_2^\mathsf{T}\mathbf{F} \mathbf{c}_1 = 0\] where \(\mathbf{F}\) is the fundamental matrix.
The fundamental and essential matrices are related via the intrisic camera matrix, namely: \[\mathbf{F} = \mathbf{K}^{-\mathsf{T}} \mathbf{E} \mathbf{K}^{\mathsf{T}}\]
The fundamental matrix has rank 2 (like the essential matrix) and 7 degrees of freedom (out of the 9 degrees of freedom, one is lost due to the scale ambiguity and another is lost because the determinant has to be zero).
40.3.4.2 Estimation of the essential/fundamental matrix
Given a set of matches between the two views we can estimate either the essential or the fundamental matrix by writing a linear set of equations. Any two matching points will satisfy \(\mathbf{p}_2^\mathsf{T}\mathbf{E} \mathbf{p}_1 = 0\) and we can use this a linear set of equations for the coefficients of \(\mathbf{E}\). However, the matrix \(\mathbf{E}\) has a very special structure that allows more efficient and robust methods to estimate the coefficients. The same applies for the fundamental matrix.
As both matrices are rank 2, the minimization the linear set of equations can be done using a constrained minimization or directly optimizing a rank 2 matrix. You can also delete the third singular value \(\mathbf{F}\), and, for \(\mathbf{E}\), you can delete the third singular value and set the first and second singular values to be equal.
Once \(\mathbf{E}\) is estimated, it can be decomposed to recover the translation (skew-symmetric matrix) and rotation (orthonormal matrix) between the two cameras using the singular value decomposition methods.
40.3.4.3 Finding the epipoles
As the epipoles, \(\mathbf{e}_1\) and \(\mathbf{e}_2\), belong to the epipolar lines, they satisfy \[\mathbf{p}_2^\mathsf{T}\mathbf{E} \mathbf{e}_1 = 0\]\[\mathbf{e}_2^\mathsf{T}\mathbf{E} \mathbf{p}_1 = 0\] and, as the epipoles are the intersection of all the epipolar lines, both relationships shown previously have to be true for any points \(\mathbf{p}_1\) and \(\mathbf{p}_2\). Therefore, \[\mathbf{E} \mathbf{e}_1 = 0\]\[\mathbf{e}_2^\mathsf{T}\mathbf{E} = 0\] As the matrix \(\mathbf{E}\) is likely to be noisy, we can compute the epipoles as the eigenvectors with the smallest eigenvalues of \(\mathbf{E}\) and \(\mathbf{E}^\mathsf{T}\).
40.3.4.4 Epipolar lines: The game
In order to build an intuition of how epipolar lines work we propose to play a game. Figure 40.13 shows a set of camera pairs and a set of epipolar lines. Can you guess what camera pair goes with what set of epipolar lines?
Answer for the game in Figure 40.13: A-2, B-5, C-4, D-6, E-3, F-1.
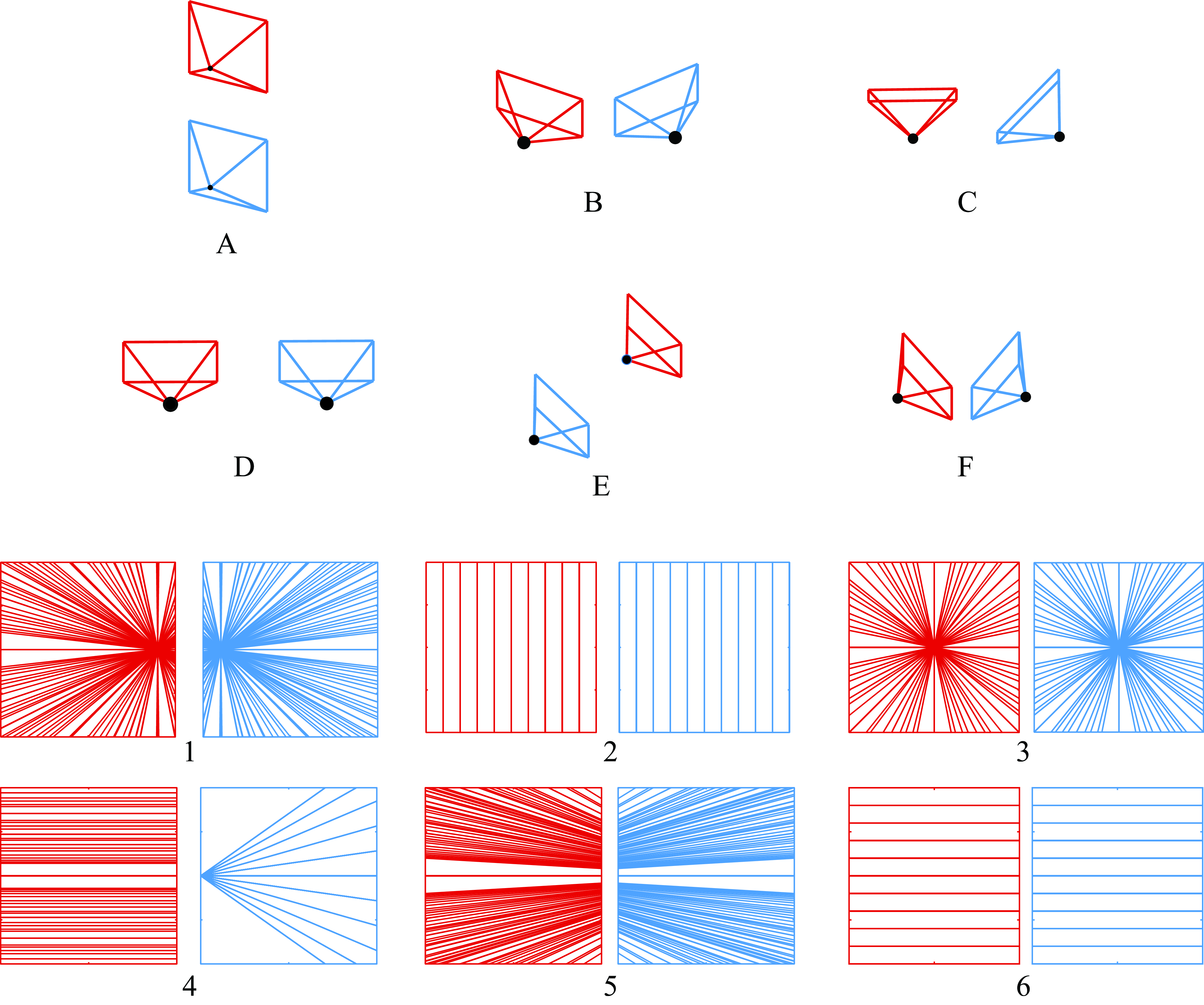
To solve the game, visualize mentally the cameras and think about how rays from the origin of one camera will be seen from the other camera. The epipole corresponds to the location where one camera sees the origin of the other camera.
Observe that most of the sets of epipolar lines shown in the figure are symmetric across the two cameras, but it is not always true. What conditions are needed to have symmetric epipolar lines across both cameras? What camera arrangements will break the symmetry? If you were to place two cameras in random locations, do you expect to see symmetric epipolar lines?
It is also useful to use the equations defining the epipolar lines and deduce the equations for the epipolar lines for some of the special cases shown in Figure 40.13.
When building systems, it is crucial to visualize intermediate results in order to find bugs in code. This requires knowing what the results should look like. The game from Figure 40.13 helps building that understanding.
40.3.5 Image Rectification
As described previously, one only needs to search along epipolar lines to find matching points in the second image. If the sensor planes of each camera are coplanar, and if the pixel rows are colinear across the two cameras, then the epipolar lines will be along image scanlines, simplifying the stereo search.
Using the homography transformations (Chapter 41), we can warp observed stereo camera images taken under general conditions to synthesize the images that would have been recorded had the cameras been aligned to yield epipolar lines along scan rows.
Many configurations of the two cameras satisfy the desired image rectification constraints [10]: (1) that epipolar lines are along image scanlines, and (2) that matching points are within the same rows in each camera image. One procedure that will satisfy those constraints is as follows [11]. First, rotate each camera to be parallel with each other and with optical axes perpendicular to the line joining the two camera centers. Second, rotate each of the cameras about its optical axis to align the rows of each camera with those of the other. Third, uniformly scale one camera’s image to be the same size as to the other, if necessary. The resulting image pair will thus satisfy the two requirements above for image rectification. Image rectification uses image warping with bilinear (or other) interpolation as described in Section 21.4.2.
Other algorithms are optimized to minimize image distortions [10] and may give better performance for stereo algorithms. We assume camera calibrations are known, but other rectification algorithms can use weaker conditions, such as knowing the fundamental matrix [12], [13]. Many software packages provide image rectification code [14].
40.4 Learning-Based Methods
As is the case for most other vision tasks, neural network approaches now dominate stereo methods. The two stages of a stereo algorithm, matching and filtering, can be implemented separately by neural networks [15], or together in a single, end-to-end optimization [16], [17], [18], [19].
40.4.1 Output Representation
One important question is how we want to represent the output. We are ultimately interested in estimating the 3D structure of the scene. We can estimate the disparity or the depth. Disparity might be easier to estimate as it is independent of the camera parameters. It is also easier to model noise, as we can assume that noise is independent of disparity. However, when using depth, estimation error will be larger for distant points.
Another interesting property of disparity is that for flat surfaces, the second-order derivative along any spatial direction, \(\mathbf{x}\), is zero: \[\frac{\partial^2 d}{\partial \mathbf{x}^2} = 0.\] This equality does not hold for depth. This property allows introducing a simple regularization term that favors planarity.
To translate the returned disparity for a given pixel \(d\left[n,m \right]\) into depth values \(z\left[n,m \right]\), we need to invert the disparity, that is
\[\begin{aligned} z \left[n,m \right] = \frac{1}{ d \left[n,m \right] } \end{aligned}\] Now we need to recover the world coordinates for every pixel. Assuming a pinhole camera and using the depth, \(z \left[n,m \right]\), and the intrinsic camera parameters, \(\mathbf{K}\), we obtain the 3D coordinates for a pixel with image coordinates \([n,m]\) in the camera reference frame as
\[\begin{aligned} \begin{bmatrix} X \\ Y \\ Z \end{bmatrix} = z\left[n,m \right] \times \mathbf{K}^{-1} \times \begin{bmatrix} n \\ m \\ 1 \end{bmatrix} \end{aligned}\] Note that \(\mathbf{K}\) are the intrinsic camera parameters for the reference image.
40.4.2 Two-Stage Networks
Given two images, \(\mathbf{v}_1\) and \(\mathbf{v}_2\), the disparity at each location can be computed by a function, that is: \[\hat{\mathbf{d}} = f_{\theta}(\mathbf{v}_1, \mathbf{v}_2)\]
The objective is that the estimated disparities, \(\hat{\mathbf{d}}\), should be close to ground truth disparities, \(\mathbf{d}\). One example of training set are the KITTI dataset [20] and the scene flow dataset [18], which contain ground truth disparities from calibrated stereo cameras. One typical loss is: \[J(\theta) = \sum_t \left| \mathbf{d} - f_{\theta} (\mathbf{v}_1, \mathbf{v}_2) \right|^2\] This is optimized by gradient descent as usual.
When matching and filtering are implemented separately, one common formulation is to use one neural network to extract features from both images, \(g(\mathbf{i}_1)\) and \(g(\mathbf{i}_2)\), and one neural network to compute the matching cost and estimate the disparities at every pixel. \[f(\mathbf{v}_1, \mathbf{v}_2) = c \left( g(\mathbf{v}_1), g(\mathbf{v}_2) \right)\]
A common approach, depicted in block diagram form in Figure 40.5 (b)lock, is the following:
Rectify the stereo pair so that scanlines in each image depict the same points in the world.
Extract features from each image, using a pair of networks with shared weights.
Form a 3D cost volume indicating the local visual evidence of a match between the two images for each possible pixel position and each possible stereo disparity. (This 3D cost volume can be referenced to the \(H\) and \(V\) positions of one of the input images.)
Train and apply a 3D convolutional neural net (CNN) to aggregate (process) the costs over the 3D cost volume in order to estimate a single, best disparity estimate for each pixel position. This performs the function of the regularization step of nonneural-network approaches, such as SGM [8], but the performance is better for the neural network approaches.
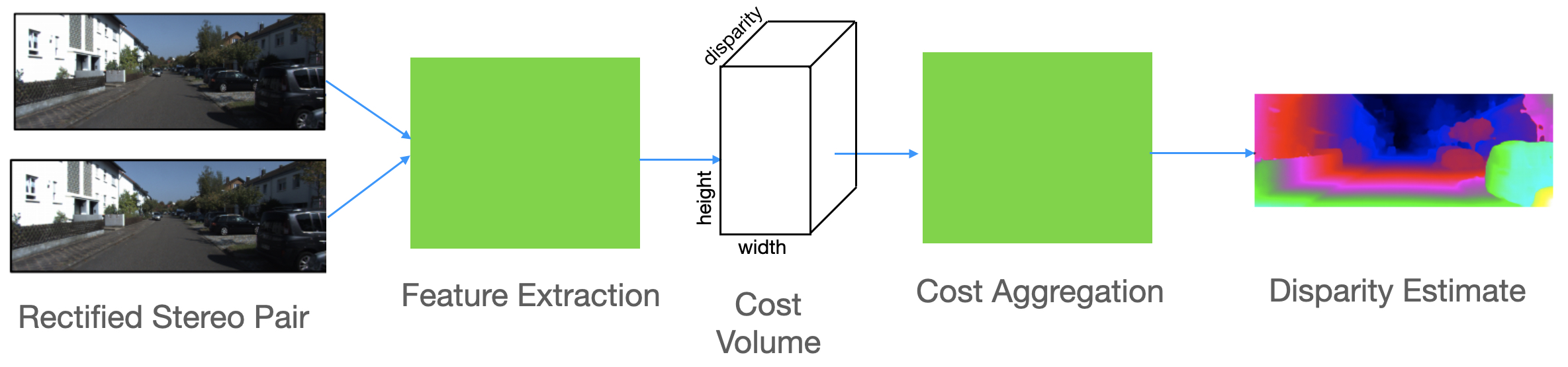
The performance of methods following the block diagram of Figure 40.14 surpassed that of methods with handcrafted features. More recent work has addressed the problem of poor generalization to out-of-training-domain test examples [21]. Training and computing the 3D neural network to process the cost volume can be expensive in time and memory and recent work has obtained both speed and performance improvement through developing an iterative algorithm to avoid the 3D filtering [22].
40.5 Evaluation
The Middlebury stereo web page [4] provides a comprehensive comparison of many stereo algorithms, compared on a common dataset, with pointers to algorithm descriptions and code. One can use the web page to evaluate the improvement of stereo reconstruction algorithms over time. The advancement of the field over time is very impressive.
40.6 Concluding Remarks
Accurate depth estimation from stereo pairs remains an unsolved problem. The results are still not reliable. In order to get accurate depth estimates, most methods require many images and the use of multiview geometry methods to reconstruct the 3D scene.
Stereo matching is often also formulated as a problem of estimating the image motion between two views captured at different locations. In chapter Chapter 46 we will discuss motion estimation algorithms.
We have only provided a short introduction to stereo vision, for an in depth study of the geometry of stereo pairs the reader can consult specialized books such as [12] and [23].