51 Vision and Language
51.1 Introduction
The last few decades have seen enormous improvements in both computer vision and natural language processing. Naturally, there has been great interest in putting these two branches of artificial intelligence (AI) together.
At first it might seem like vision has little to do with language. This is what you might conclude if you see the role of language as just being about communication. However, another view on language is that it is a representation of the world around us, and this representation is one the brain uses extensively for higher-level cognition [1]. Visual perception is also about representing the world around us and forming mental models that act as a substrate for reasoning and decision making. From this perspective, both language and vision are trying to solve more or less the same problem.
It turns out this view is quite powerful, and indeed language and vision can help each other in innumerable ways. This chapter is about some of the ways language can improve vision systems, and also how vision systems can support language systems.
51.2 Background: Representing Text as Tokens
In order to understand vision-language models (VLMs) we first need to understand a bit about language models. There are many ways to model language and indeed there is a whole field that studies this, called natural language processing (NLP). We will present just one way, which follows almost exactly the same format as modern computer vision systems: tokenize the text, then process it with a transformer. In chapter Chapter 26 we saw how to apply transformers to images and now we will see how to apply them to text.
The amazing thing about transformers is that they work well for a wide variety of data types: in fact, the same architectures that we saw in chapter Chapter 26 also works for text processing. To apply transformers to a new data modality may require nothing more than figuring out how to represent that data as numbers.
So our first question is, how can we represent text as numbers? One option, which we have already seen, is to use a word-level encoding scheme, mapping each word in our vocabulary to a unique one-hot code. This requires \(K\)-dimensional one-hot codes for a vocabulary of \(K\) different words.
A disadvantage of this approach is that \(K\) has to be very large to cover a language like English, which has a large vocabulary of over 100,000 possible words. This becomes even worse for computer languages, like Python. Programmers routinely name variables using made up words, which might never have been used before. We can’t define a vocabulary large enough to cover all the strange strings programmers might come up with.
Instead, we could use a different strategy, where we assign a one-hot code to each character in our vocabulary, rather than to each unique word. If we represent all alphanumeric characters and common punctuation marks in this way, this might only require a few dozen codes. The disadvantage here is that representing a single word now requires a sequence of one-hots rather than a single one-hot code, and we will have to model that sequence.
A happy middle ground can be achieved using byte-pair encodings [2]. In this approach, we assign a one-hot code to each small chunk of text. The chunks are common substrings found in text, like “th” or “ing.” This strategy is popular in language models like the generative pretrained transformer (GPT) series [3] and the contrastive language-image pretraining (CLIP) model [4] that we will learn about in Section 51.3.
Once we have converted text into a sequence of one-hot codes, the next step is to convert these into tokens via a projection, \(\mathbf{W}_{\texttt{tokenize}}\), from the one-hot dimensionality (\(K\)) to a target dimensionality for token code vectors (\(d\)). Figure 51.1 shows these steps for converting an input string to tokens. For simplicity, we show word-level one-hot encoding rather than byte-pair encoding.
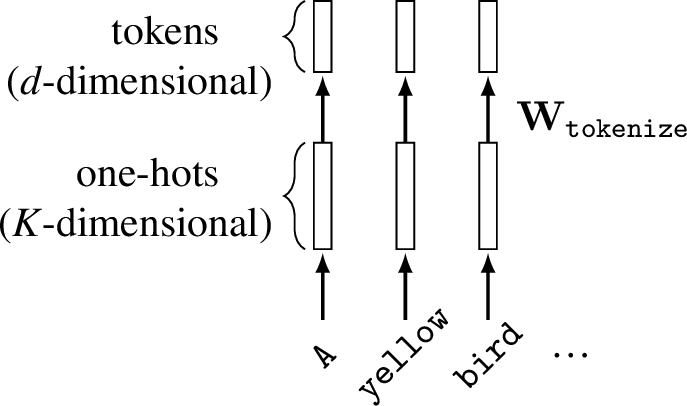
These steps map text to tokens, which can be input into transformers. To handle the output side, where we produce text as an output, we need to convert tokens back to text. The most common way to do this is to use an autoregressive model that predicts each next item in our vocabulary (word/character/byte-pair) given the sequence generated so far. Each prediction step can be modeled as a softmax over all \(K\) possible items in our vocabulary. We will see a specific architecture that does this in Section 51.4.2.
51.3 Learning Visual Representations from Language Supervision
In chapter Chapter 30, we saw that one approach of learning visual representations is to set up a pretext task that requires arriving at a good representation of the scene. In this section we will revisit this idea, using language association as a pretext task for representation learning.
In fact this is not a new idea: historically, one of the most popular pretext tasks has been image classification, where an image is associated with one of \(K\) nouns. In a sense, this is already a way of supervising visual representations from language. Of course, human languages are much more than just a set of \(K\) nouns. This raises the question, could we use richer linguistic structure to supervise vision?
The answer is yes! And it works really well. Researchers have tried using all kinds of language structures to supervise vision systems, including adjectives and verbs [5], words indicating relationships between objects [6], and question-answer pairs [7]. What seems to work best, once you reach a certain scale of data and compute, is to just use all the structure in language, and the simplest way to do this is to train a vision system that associates images with free-form natural language.
This is the idea of the highly popular CLIP system [4]. CLIP is a contrastive method (see Section 30.10) in which one data view is the image and the other is a caption describing the image. Specifically, CLIP is a form of contrastive learning from co-occurring visual and linguistic views that is formulated as follows:

where \(\boldsymbol\ell\) represents an image, \(\mathbf{t}\) represents text, \(\mathbb{S}^{d_z}\) represents the space of unit vectors of dimensionality \(d_z\) (i.e., the surface of the \([d_z-1]\)-dimensional hypersphere), \(f_{\ell}\) is the image encoder, \(f_t\) is the text encoder, image inputs are represented as \([3 \times N \times M]\) pixel arrays, text inputs are represented as \(d_t\) dimensional tokens, and \(d_z\) is the embedding dimensionality. Notice that the objective is a symmetric version of the InfoNCE loss defined in Equation 30.4. Also notice that \(f_\ell\) and \(f_t\) both output unit vectors (which is achieved using \(L_2\)-normalization before computing the objective); this ensures that the denominator cannot dominate by pushing negative pairs infinitely far apart.
The idea of visual learning by image captioning actually has a long history before CLIP. One important early paper on this topic is [8].
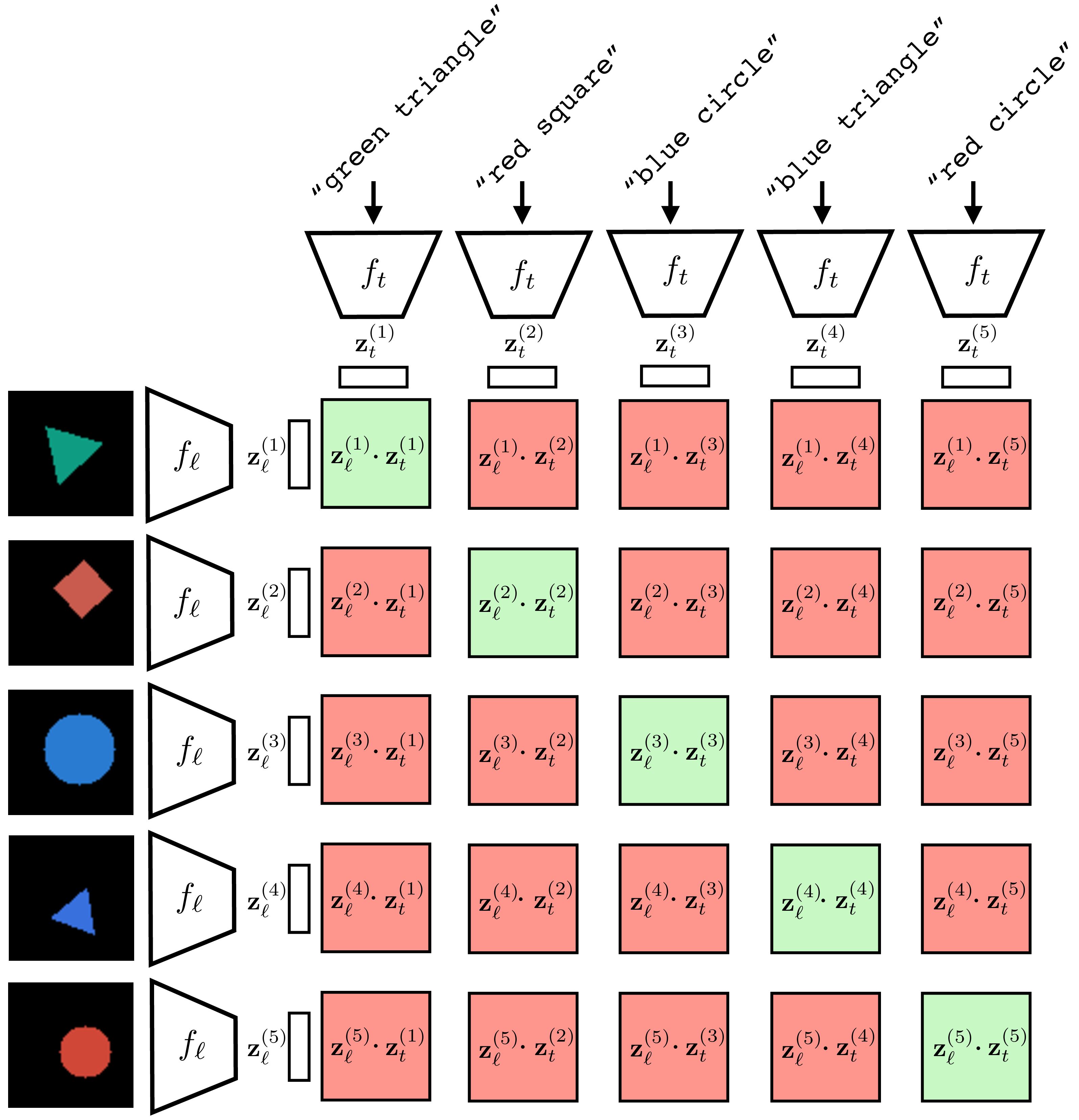
Figure 51.2 visually depicts how CLIP is trained. First we sample a batch of \(N\) language-image pairs, \(\{\mathbf{t}^{(i)}, \boldsymbol\ell^{(i)}\}_{i=1}^N\) (\(N=6\) in the figure). Next we embed measure the dot product between all these text strings and images using a language encoder \(f_t\) and an image encoder \(f_\ell\), respectively. This produces a set of text embeddings \(\{\mathbf{z}^{(i)}_t\}_{i=1}^N\) and a set of image embeddings \(\{\mathbf{z}^{(i)}_\ell\}_{i=1}^N\). To compute the loss, we take the dot product \(\mathbf{z}^{(i)}_\ell\cdot \mathbf{z}^{(j)}_t\) for all \(i, j \in \{1,\ldots,6\}\). Terms for which \(i \neq j\) are the negative pairs and we seek to minimize these dot products (denominator of the loss); terms for which \(i == j\) are the positive pairs and we seek to maximize these dot product (they appear in both the numerator and denominator of the loss).
After training, we have a text encoder \(f_t\) and an image encoder \(f_\ell\) that map to the same embedding space. In this space, the angle between a text embedding and an image embedding will be small if the text matches the matches.
The dot product between unit vectors is proportional to the angle between the vectors.
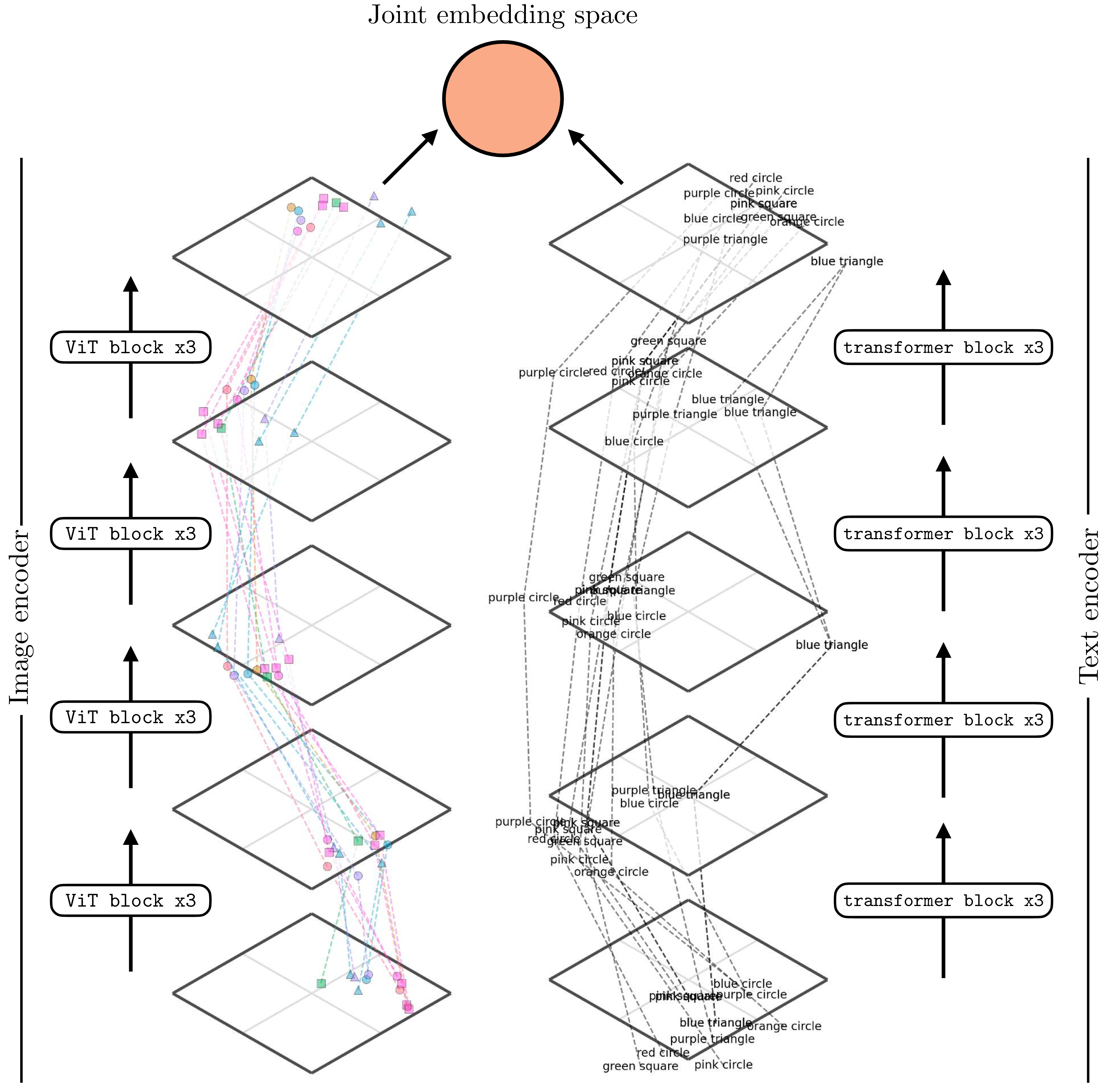
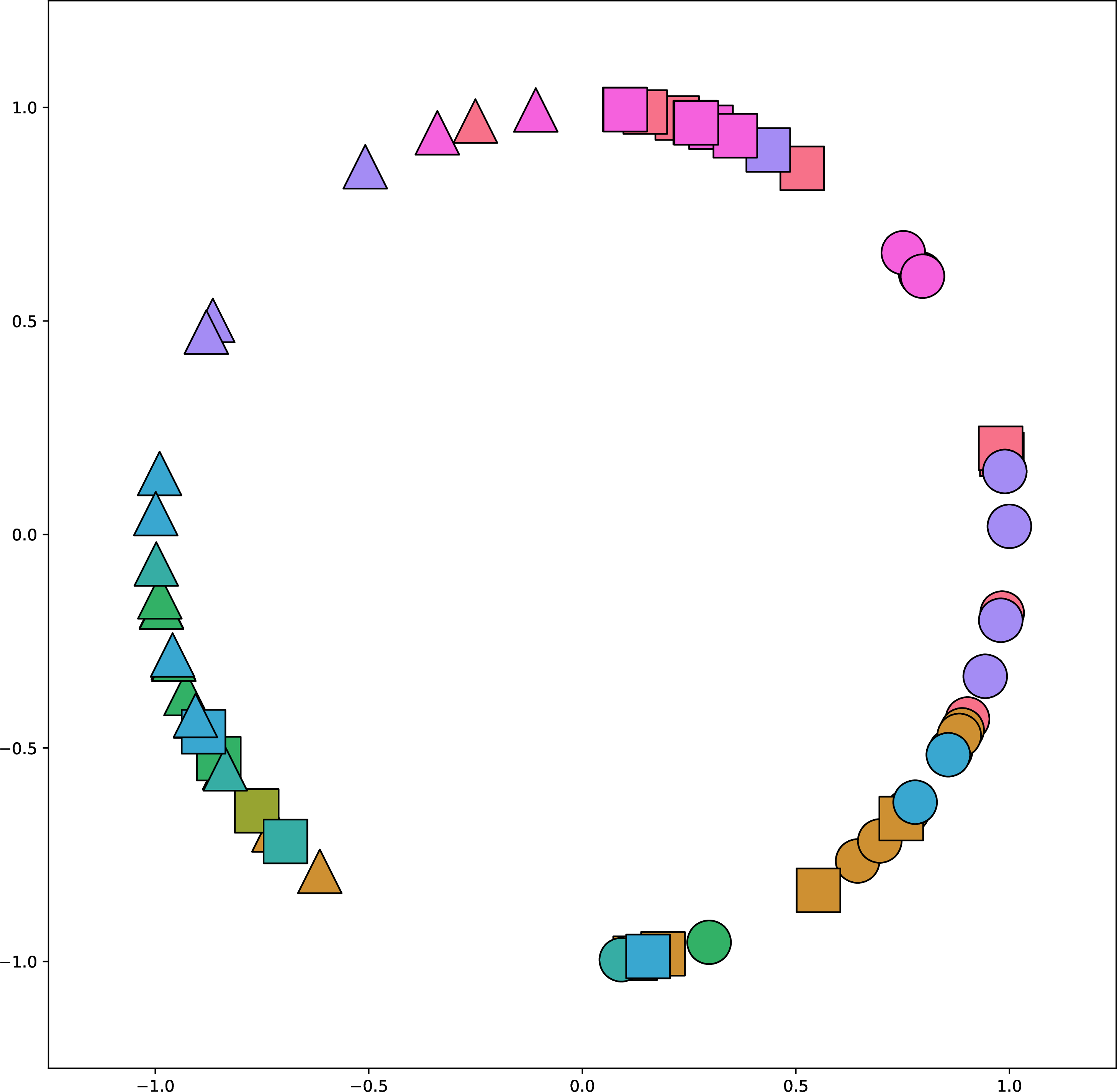
Figure 51.3 shows how a trained CLIP model maps data to embeddings. This figure is generated in the same way as Figure 13.9: for each encoder we reduce dimensionality for visualization using t-distributed Stochastic Neighbor Embedding (t-SNE) [9]. For the image encoder, we show the visual content using icons to reflect the color and shape depicted in the image (we previously used the same visualization in Section 30.10.2).
It’s a bit hard to see, but one thing you can notice here is that for the image encoder, the early layers group images by color and the later layers group more by shape. The opposite is true for the text encoder. Why do you think this is? One reason may be that color is a superficial feature in pixel-space while shape requires processing to extract, but in text-space, color words and shape words are equally superficial and easy to group sentences by.
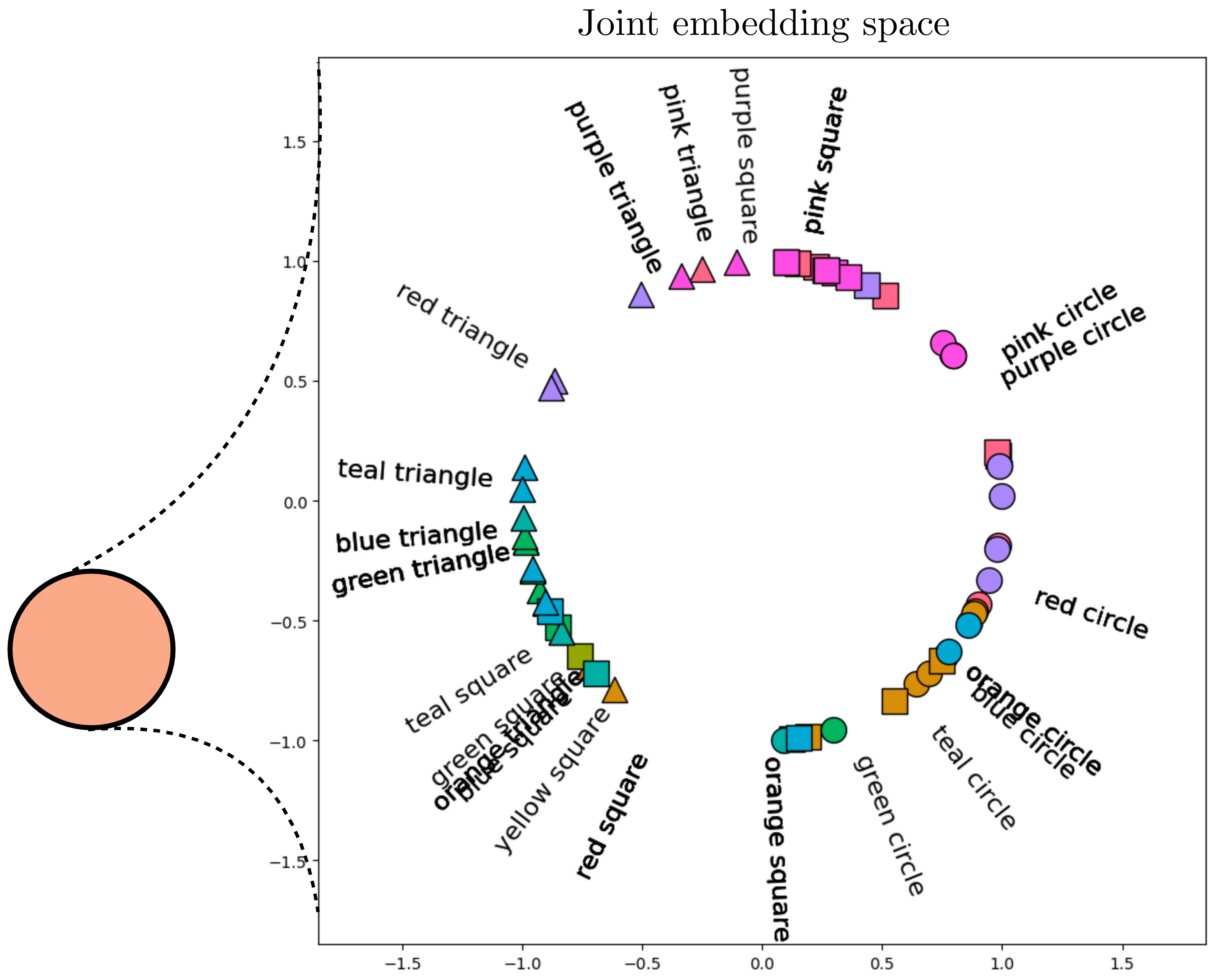
After passing the data through these two encoders, the final stage is to normalize the outputs and compute the alignment between the image and text embeddings. Figure 51.4 shows this last step. After normalization, all the embeddings line on the surface of a hypersphere (the circle in the figure). Notice that the text descriptions are embedded near the image embeddings (icons) that match that description. It’s not perfect but note that this is partially due to limitations in the visualization, which projects the \(768\)-dimensional CLIP embeddings into a 2D visualization. Here we use kernel principle component analysis [10] on the embeddings, with a cosine kernel, and remove the first principle component as that component codes for a global offset between the image embeddings and text embeddings.
Using language as one of the views may seem like a minor variation on the contrastive methods we saw previously, but it’s a change that opens up a lot of new possibilities. CLIP connects the domain of images to the domain of language. This means that many of the powerful abilities of language become applicable to imagery as well. One ability that the CLIP paper showcased is making a novel image classifier on the fly. With language, you can describe a new conceptual category with ease. Suppose I want a classifier to distinguish striped red circles from polka dotted green squares. These classes can be described in English just like that: “striped red circles” versus “polka dotted green square.” CLIP can then leverage this amazing ability of English to compose concepts and construct an image classifier for these two concepts.
Here’s how it works. Given a set of sentences \(\{\mathbf{t}^{a}, \mathbf{t}^{b}, \ldots\}\) that describe images of classes \(a\), \(b\), and so on,
Embed each sentence into a \(\mathbf{z}\)-vector, \(\mathbf{z}_t^{a} = f_t(\mathbf{t}^{a}), \mathbf{z}_t^{b} = f_t(\mathbf{t}^{a}),\) and so on.
Embed your query image into a \(\mathbf{z}\)-vector, \(\mathbf{z}_{\ell}^{q} = f_{\ell}(\boldsymbol\ell^{q})\).
See which sentence embedding is closest to your image embedding; that’s the predicted class.
These steps are visualized in Figure 51.5. The green outlined dot product is the highest, indicating that the query image will be classified as class \(a\), which is defined as “striped red circles.”
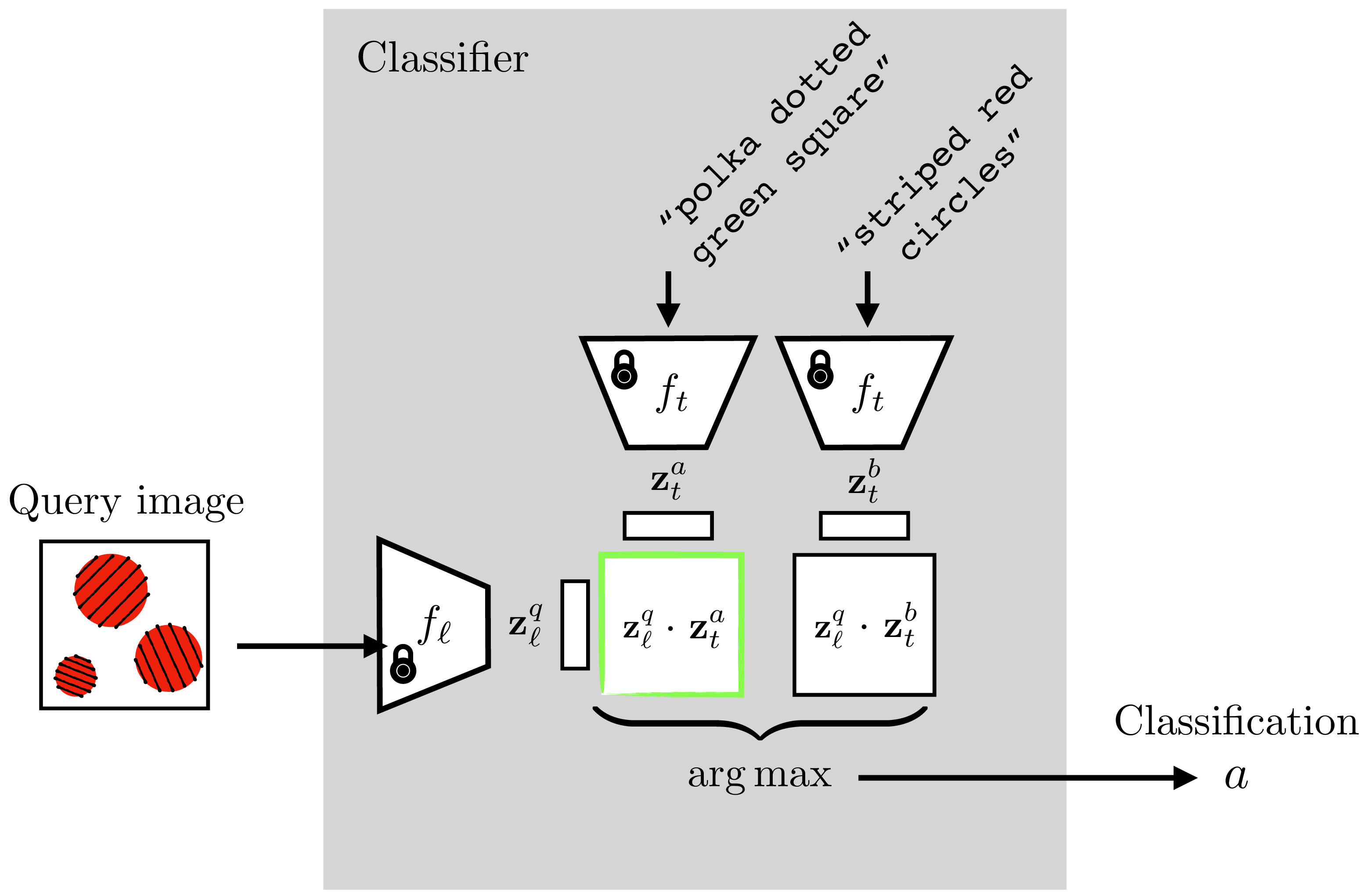
striped red circles'' (class $a$) versuspolka dotted green square’’ (class \(b\)) classifier using a trained CLIP. The CLIP model parameters are frozen and not updated. Instead the classifier is constructed by embedding the text describing to the two classes and seeing which is closer to the embedding of the query image. Inspired by figure 1 of [4]
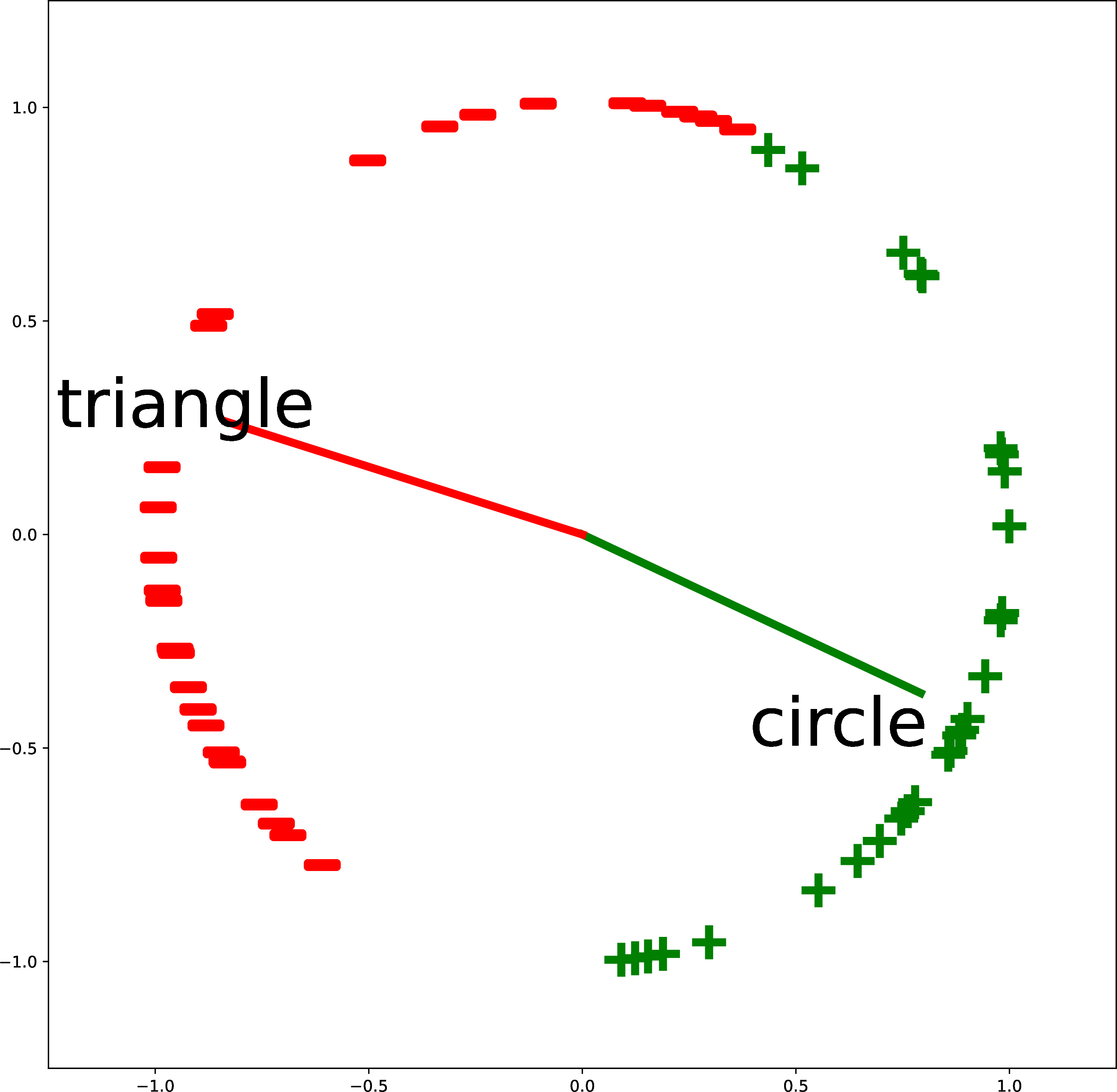
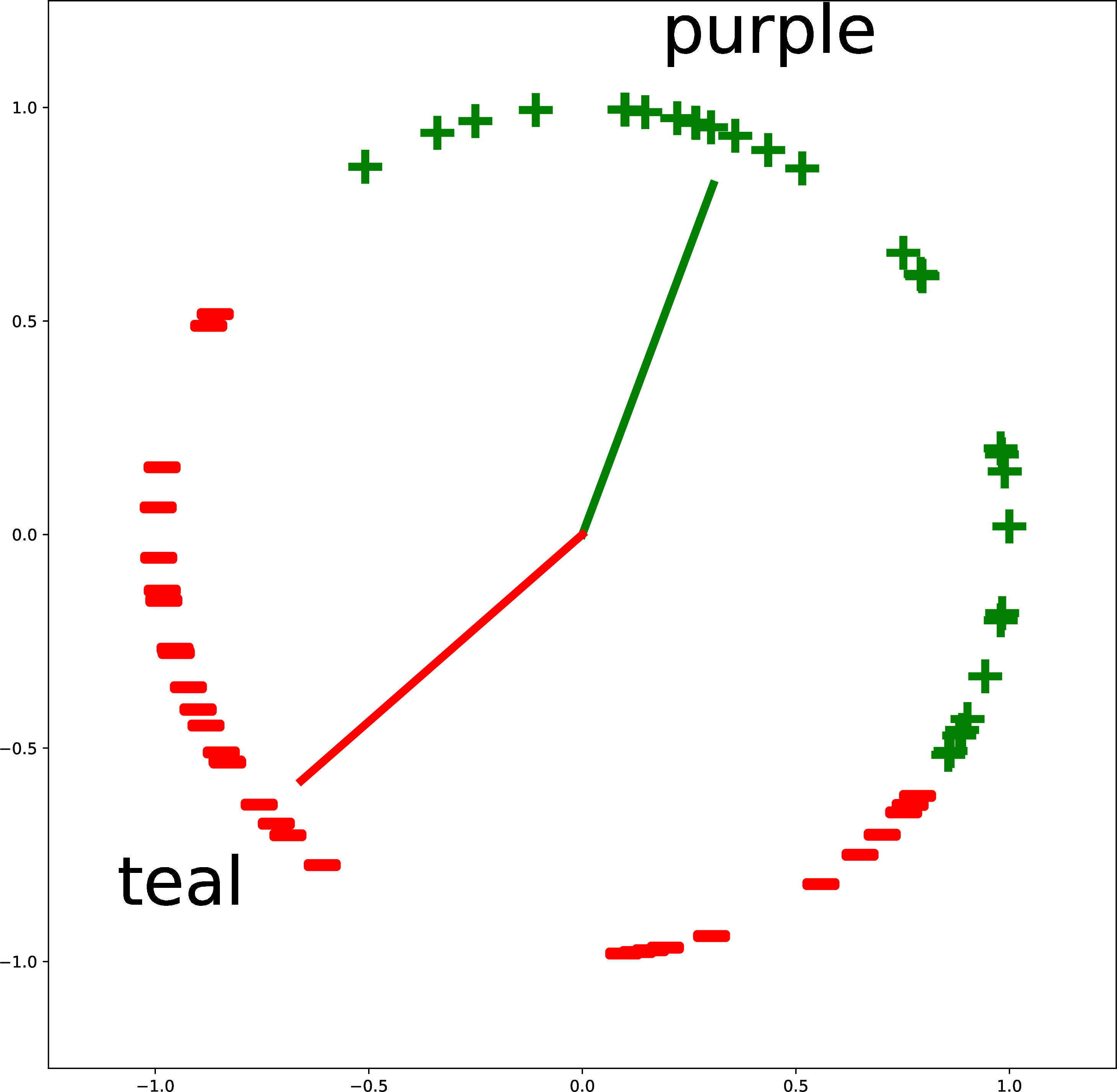
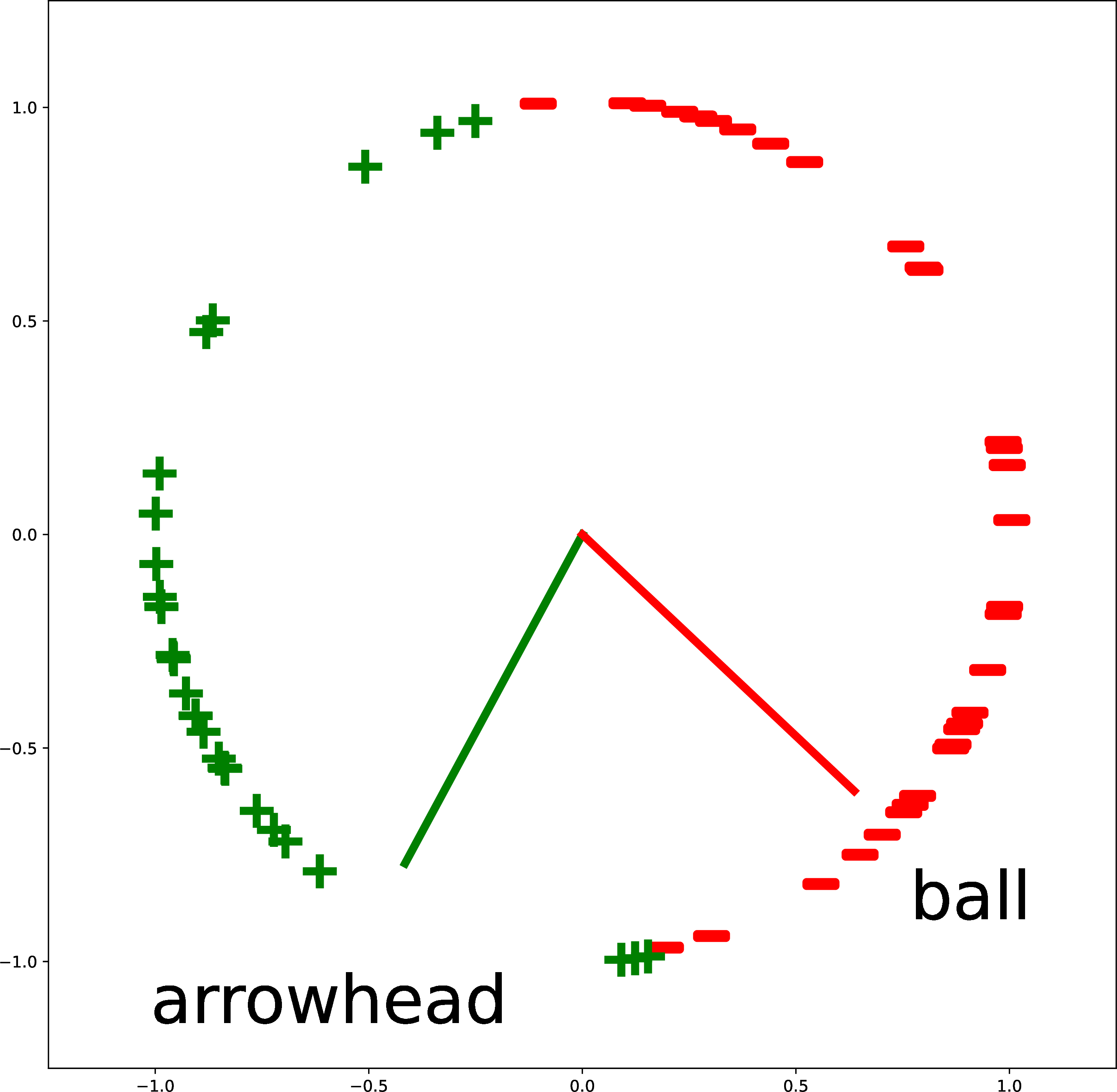
Figure 51.6 gives more examples of creating custom binary classifiers in this way. The two classes are described by two text strings (“triangle” versus “cricle”; “purple” versus “teal”; and “arrowhead” versus “ball”). The embeddings of the text descriptions are the red and green vectors. The classifier simply checks where an image embedding is closer, in angular distance, to the red vector or the green vector. This approach isn’t limited to binary classification: you can add more text vectors to partition the space in more ways.
51.4 Translating between Images and Text
In chapter Chapter 34, we saw how to translate between different image domains. Could we be even more ambitious and translate between entirely different data modalities? It turns out that this is indeed possible and is an area of growing interest. For any type of data X, and any other type Y, there is, increasingly, a method X2Y (and Y2X) that translates between these two data types. Go ahead and pick your favorite data types—X,Y could be images and sounds, music and lyrics, amino acid sequences and protein geometry—then Google “X to Y with a deep net” and you will probably find some interesting work that addresses this problem. X2Y systems are powerful because they forge links between disparate domains of knowledge, allowing tools and discoveries from one domain to become applicable to other linked domains.
One approach to solving X-to-Y translation problems is do it in a modular fashion by hooking up an encoder for domain X to a decoder for domain Y. This approach is popular because powerful encoder and decoder architectures, and pretrained models, exist for many domains. If we have an encoder \(f: \mathcal{X} \rightarrow \mathcal{Z}\) and a decoder \(g: \mathcal{Z} \rightarrow \mathcal{Y}\), then we can create a translator simply by function composition, \(g \circ f\).
Of course, the output of our encoder might not be interpretable as a proper input to the decoder we selected. For example, suppose \(f\) is a text encoder and \(g\) is an image decoder and we have \(\boldsymbol\ell= g(f(\mathbf{t}))\), where \(\boldsymbol\ell\) is a generated image from the text input \(\mathbf{t}\). Then nothing guarantees that \(\boldsymbol\ell\) semantically matches \(\mathbf{t}\).
To align the encoder and decoder we can follow several strategies. One is to simply finetune \(g \circ f\) on paired examples of the target translation problem, \(\{\mathbf{t}^{(i)}, \boldsymbol\ell^{(i)}\}_{i=1}^N\). Another option is to freeze \(f\) and \(g\) and instead train a translation function in latent space, \(h: \mathcal{Z} \rightarrow \mathcal{Z}\), so that \(g \circ h \circ f\) correctly maps each training point \(\mathbf{t}^{(i)}\) to the target output \(\boldsymbol\ell^{(i)}\). See [11] for an example of this latter option.
In the next sections, we will look at a few specific architectures for solving this problem of text-to-image translation as well as the reverse, image-to-text.
51.4.1 Text-to-Image
One amazing ability of modern generative models is to synthesize an image just from a text description, a problem called text-to-image. This can be achieved using any of the conditional generative models we saw in chapter Chapter 34. We simply have to find an effective way to use text as the conditioning information to these models. Figure 51.7 shows how this problem looks as a mapping from the space of text to the space of images:
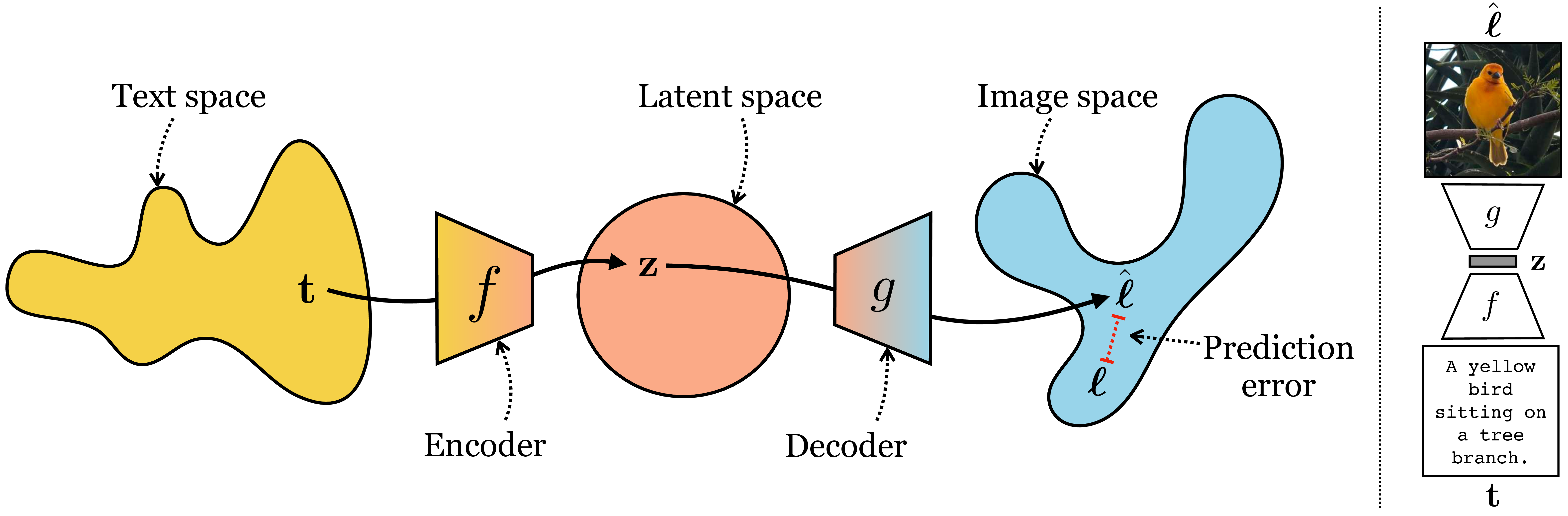
On the right is an example of such a system translating input text \(\mathbf{t}\) to an output image \(\hat{\boldsymbol\ell}\) that matches what the text describes. Recall the similar diagrams in the chapters on representation learning and generative modeling and think about how they relate (see and Figure 33.2. This new problem is not so different from what we have seen before!
Now let’s build some concrete architectures to solve this mapping. We will start with a conditional variational autoencoder (cVAE; Section 34.4.2). This was the architecture used by the DALL-E 1 model [12], which was one of the first text-to-image models that caught the public’s imagination.
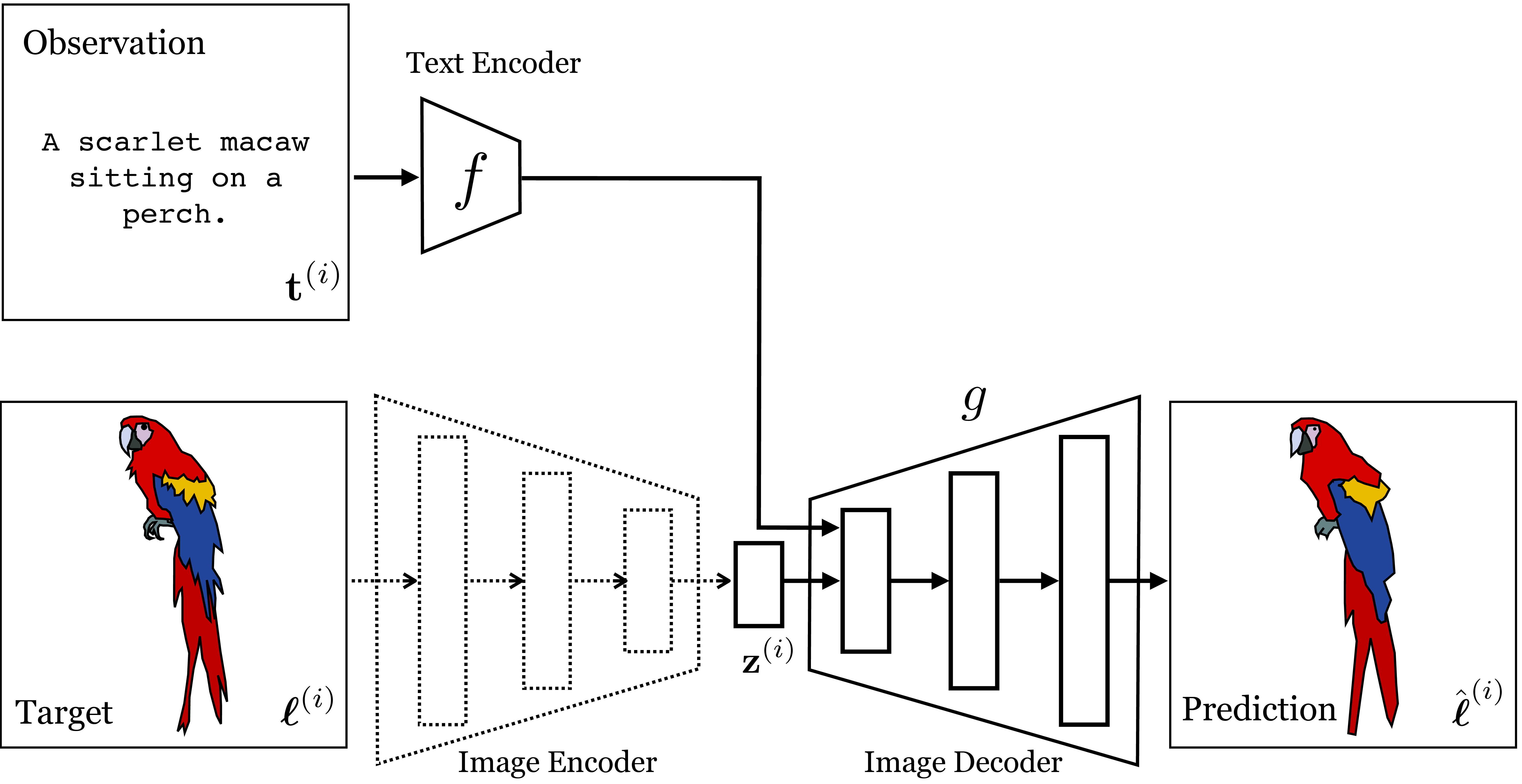
A cVAE for text-to-image can be trained just like a regular cVAE; the special thing is just that the encoder is a text encoder, that is, a neural net that maps from text to a vector embedding. Figure 51.8 shows what the training looks like; it’s conceptually the same as Figure 34.5, which we saw previously.
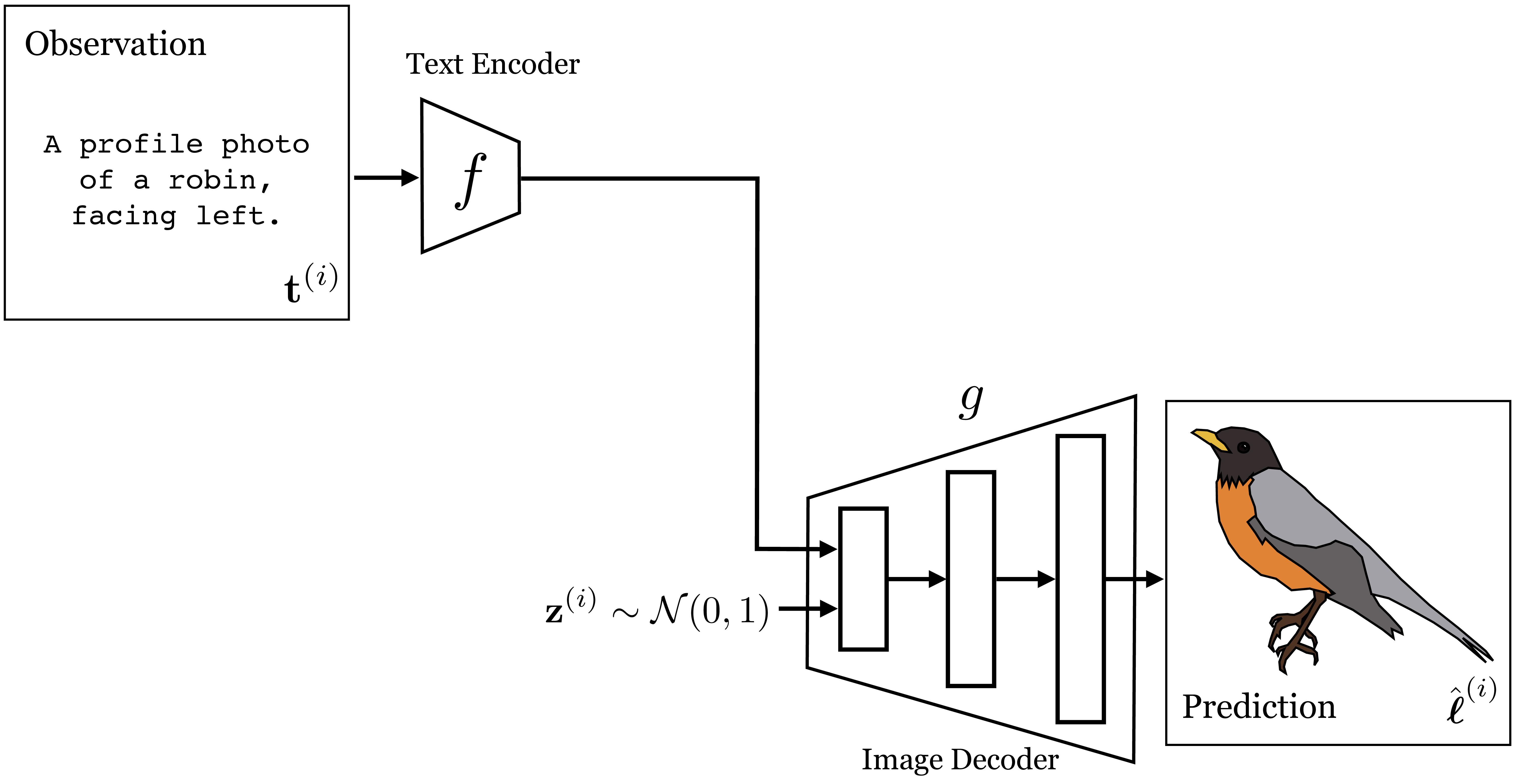
After training this model, we can sample from it by simply discarding the image encoder and instead inputting a random Gaussian vector to the decoder, in addition to providing the decoder with the text embedding. Figure 51.9 shows how to sample an image in this way.
This is how text-to-image generation can be done with a cVAE. We could perform the same exercise for any conditional generative model. Let’s do one more, a conditional diffusion model. This is the approach followed by the second version of the DALL-E system, DALL-E 2 [13], as well as other popular systems like the one described in [11]. The difficulty we will focus on here is as follows: how do you most effectively insert the text embeddings into the the decoder, so that it can make best use of this information? Figure 51.10 shows one way to do this, which is roughly how it is done in [11]: we insert text embedding vectors into each denoising U-Net, and even into multiple layers of each U-Net. This makes it very easy for the diffusion model to condition all of its decisions on the text information.
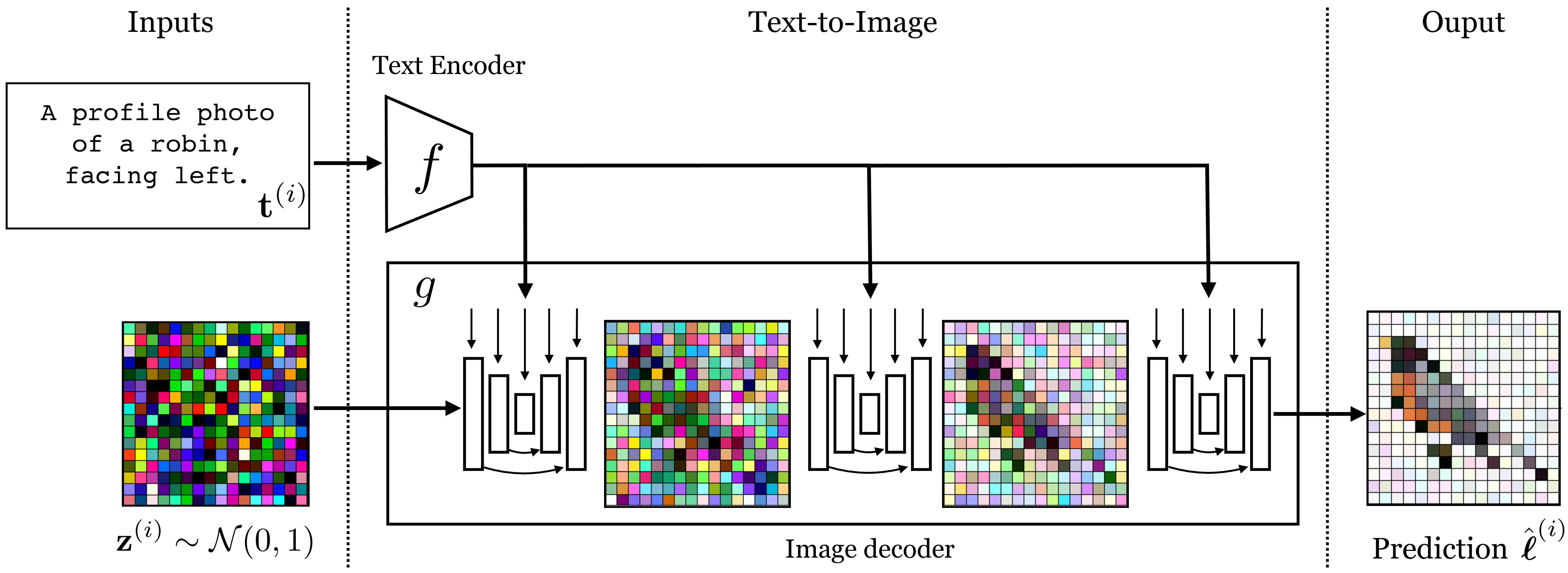
Notice that Figure 51.10 is actually very similar to Figure 51.9. A conditional diffusion model is in fact very similar to a cVAE. At sampling time, both take as input text and Gaussian noise. The VAE uses a network that directly maps these inputs to an image, in a single forward pass. The diffusion model, in contrast, maps to an image via a chain of denoising steps, each of which is a forward pass through a neural network. See [14] for a discussion of the connection between diffusion models and VAEs.
51.4.2 Image-to-Text
Naturally, we can also translate in the opposite direction. We just need to use an image encoder (rather than a text encoder) and a text decoder (rather than a text encoder). In this direction, the problem can be called image-to-text or image captioning. This kind of translation is very useful because text is a ubiquitous and general-purpose interface between almost all domains of human knowledge (we use language to describe pretty everything we do and everything we know). So, if we can translate images to text then we link imagery to many other domains of knowledge.
As an example of an image-to-text system, we will use a transformer to map the input image to a set of tokens, and we will then feed these tokens as input to an autoregressive text decoder, which is also implemented with a transformer. See [15] for an example of a system that uses this general approach. Figure 51.11 shows this architecture.
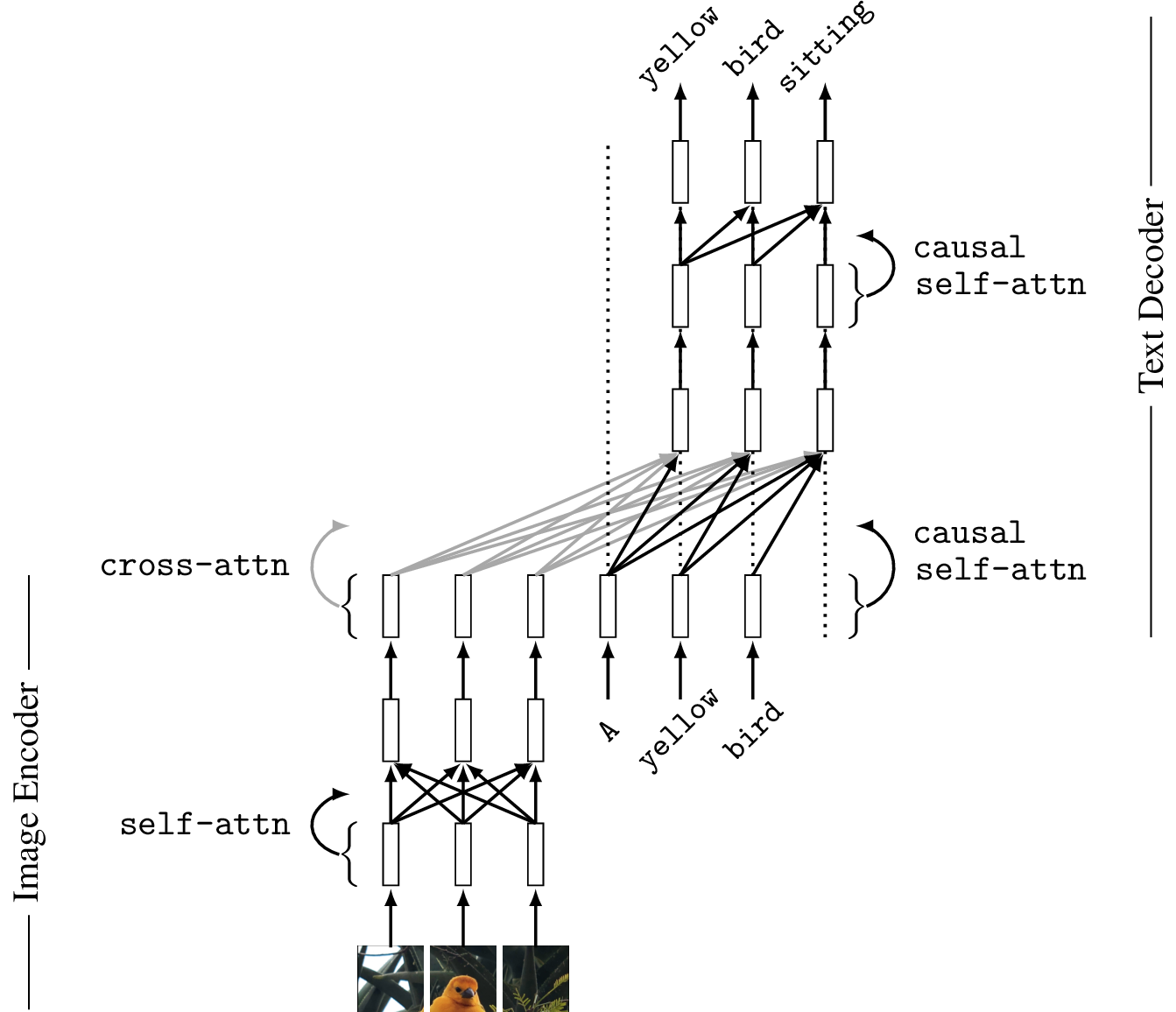
There is one special layer to point out, the cross-attention layer (cross-attn). This layer addresses the question of how to insert image tokens into a text model. The answer is quite simple: just let the text tokens attend to the image tokens. The image tokens will emit their value vectors which will be mixed with the text token value vectors according to the attention weights to produce the next layer of tokens in the text decoder.
Here are the equations for a cross-attention layer: \[\begin{aligned} \mathbf{Q}_{t} = \mathbf{T}_{t}\mathbf{W}_{t,q}^\mathsf{T}\\ \mathbf{K}_{\ell} = \mathbf{T}_{\ell}\mathbf{W}_{\ell,k}^\mathsf{T}\\ \mathbf{V}_{\ell} = \mathbf{T}_{\ell}\mathbf{W}_{\ell,v}^\mathsf{T}\\ \mathbf{A}_{\texttt{cross}} = \texttt{softmax}(\frac{\mathbf{Q}_{t}\mathbf{K}_{\ell}^\mathsf{T}}{\sqrt{m}})\\ \mathbf{T}_{\texttt{out}, \texttt{cross}} = \mathbf{A}_{\texttt{cross}}\mathbf{V}_{\ell} \end{aligned}\]
where variables subscripted with \(t\) are associated with text tokens and variables subscripted with \(\ell\) are associated with image tokens.
Then, the tokens output by cross-attention can be combined with tokens output by self-attention by weighted summation:
\[\begin{aligned} \mathbf{T} = w_{\texttt{cross}}\mathbf{T}_{\texttt{out}, \texttt{cross}} + w_{\texttt{self}}\mathbf{T}_{\texttt{out}, \texttt{self}} \end{aligned} \] where \(\mathbf{T}_{\texttt{out}, \texttt{self}}\) is regular self-attention on the input text token \(\mathbf{T}_t\), and \(w_{\texttt{cross}}\) and \(w_{\texttt{self}}\) are optional learnable weights.
The text decoder is an autoregressive model (Section 32.7) that uses causal attention (Section 26.10) to predict the next word in the sentence given the previous words generated so far. In this strategy, the input to the text decoder is the tokens representing the previous words in the training data caption that describes the image. At sampling time, the model is run sequentially, where for each next word generated it autoregressively repeats, with that word being added to the input sequence of tokens. The text tokens themselves are produced by tokenizing the input words, for example, via byte-pair encodings or word-level encodings (the latter is shown in the figure).
51.5 Text as a Visual Representation
One way of thinking about image-to-text is as yet another visual encoder, where text is the visual representation. Just like we can represent an image in terms of its frequencies (Fourier transform), its semantics and geometry (scene understanding), or its feature embeddings (DINO [16], CLIP [4], and others), we can also represent it in terms of a textual description of its content.
In Figure 51.12 we show an image represented in several ways (the depth map is produced by MiDaS [17] and the text is produced by BLIP2 [15]):

Think about the relative merits of each of these representations, and what advantages or disadvantages text might have over these other kinds of visual representation.
Text is a powerful visual representation because it interfaces with language models. This means that after translating an image into text we can use language models to reason about the image contents.
51.6 Visual Question Answering
As AI systems become more general purpose, one goal is to make a vision algorithm that is fully general, so that you can ask it any question about an image. This is akin to a Turing test [18] for visual intelligence. Visual question answering (VQA) is one formulation of this goal [7]. The problem statement in VQA is to make a system that maps an image and a textual question to a textual answer, as shown in Figure 51.13.

By now you have seen several ways to build image and text encoders as well as decoders, and how to put them together. As an exercise, think about how you might implement the VQA system shown here, using the tools from elsewhere in this chapter and book. See if you can modify the transformer architecture in Figure 51.11 to solve this problem.
In this chapter, we have already seen all the tools necessary to create a VQA system; you just need a text encoder (for the question), an image encoder (for the image you are asking the question about), and a text decoder (for the answer). These can be hooked together using the same kinds of tools we have seen earlier in this chapter. The critical piece is just to acquire training data of VQA examples, each of which takes the form of a tuple {[question, image], answer}. For a representative example of how to implement a VQA model using transformers, see [15].
51.7 Concluding Remarks
From the perspective of vision, language is a perceptual representation. It is a way of describing “what is where” and much more in a low-dimensional and abstracted format that interfaces well with other domains of human knowledge. There are many theories of how human language evolved, and what it is useful for: communication, reasoning, abstract thought. In this chapter, we have suggested another: language is, perhaps, the result of perceptual representation learning over the course of human evolution and cultural development. It’s one of the main formats brains have arrived at as the best way to represent the “blooming, buzzing” sensory array around us.
“To know what is where by looking” is how David Marr defined the vision in his seminal book on the subject [19].
This phrasing is from a quote by William James (https://en.wikiquote.org/wiki/William_James).