34 Conditional Generative Models
34.1 Introduction
In the preceding chapters, we learned about two uses of generative models: (1) as a way to synthesize realistic but novel data, and (2) as a way to learn representations of the data. Now we will introduce a third use, which is arguably the most widespread use of generative models: as a way to solve prediction problems.
34.2 A Motivating Example: Image Colorization
To motivate this use case, consider the following problem. We wish to colorize a black and white photo, that is, we wish to predict the color of each pixel in a black and white photo.
Now, we already have seen some tools we could apply to this problem. First we will try to solve it with least-squares regression. Second, with softmax classification. We will see that both approaches fall short of a good solution. This will motivate the necessity of conditional generative models, which turn out to solve the colorization problem quite nicely, and can produce nearly photorealistic results.
34.2.1 The Failure of Point Prediction: Multimodal Distributions
We could formulate the problem as least-squares regression: train a function to output a vector of real-valued numbers, representing the red, green, and blue values of every pixel in the image, then penalize the squared distance between these values and the ground truth values.
This kind of regression fits a function \(f: \mathcal{X} \rightarrow \mathcal{Y}\). For every input \(\mathbf{x} \in \mathcal{X}\), the output is a single point prediction \(\hat{\mathbf{y}} \in \mathcal{Y}\), that is, we output just a single prediction of what the value of \(\mathbf{y}\) should be.

What if there are multiple equally valid answers? Taking a color image and making it grayscale is a many-to-one mapping: for any given grayscale value, there are many different color values that could have projected to that value of gray. This means that the colorization problem is fundamentally ambiguous, and there may be multiple valid color solutions for any grayscale input. A point estimate is bound to be a poor inference in this case, since a point estimate can only predict one of the multiple possible solutions.
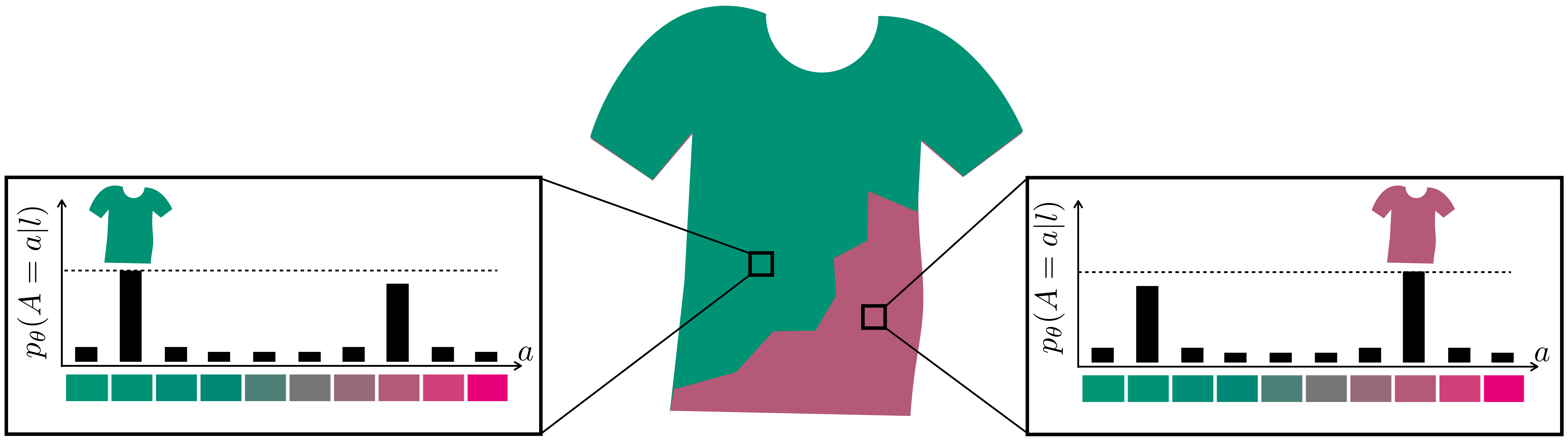
Figure 34.1 shows several kinds of predictions one could make given an observation of a grayscale t-shirt. The question is straightforward: What is the color of the shirt? To unify different kinds of prediction models, we will represent them all as outputting a distribution over the possible colors of the shirt. Let \(A\) be a random variable that represents the \(a\) value of the shirt in \(lab\) color space. Our input is just the \(l\) value of the shirt. Our predictions will be represented as \(p_{\theta}(A \bigm | l)\). The particular shirt we are looking at comes in two colors, either teal or pink. The true data distribution, \(p_{\texttt{data}}\), is therefore two delta functions, one on teal and the other on pink.
Least-squares regression results in a model that predicts the mean of the data distribution. Therefore, the point prediction output by a least-squares regressor will be that the shirt is gray. The probability density associated with this prediction is shown in Figure 34.1 (b).
A point prediction does not necessarily come with probabilistic semantics, but here we will interpret a prediction of \(\hat{a} = f_{\theta}(l)\) as implying a predictive distribution over \(A\) that has the form \(p_{\theta}(A = a \\| l) = \delta(a - \hat{a})\), where \(\delta\) is the Dirac delta function.
This prediction is entirely wrong! It splits the difference between the two true possibilities and comes out with something that has zero probability under the data distribution. As discussed in Chapter 29, we could have done regression with a different loss function (using the \(L_1\) loss for example, rather than \(L_2\)), and we would have come up with a different solution. But we will never get the correct solution. Because the true distribution has two equally probable modes, and a single point prediction can only ever represent one mode.
We can do better by predicting a distribution rather than a point estimate. An example is shown in Figure 34.1 (c), where we predict a Gaussian distribution. In fact, the least-squares regression model can be described as outputting the mean of a max likelihood Gaussian fit to \(p_{\theta}(A \bigm | l)\). Predicting the distribution then just requires also predicting the variance of the Gaussian. This gives us a better sense of the possible colors the shirt could be, but it is still a unimodal distribution, while the data is bimodal.
Naturally, then, we may want to predict a more expressive distribution; a mixture of two Gaussians could, for example, capture the bimodal nature of the data. An easy way to predict a distribution is to predict the parameters of some parametric family of distributions. This is precisely what we did with the Gaussian fit: the parameters of a 1D Gaussian are its mean and variance, so if \(\hat{\mathbf{y}} \in \mathbb{R}^2\) then \(\hat{\mathbf{y}}\) suffices to parameterize a 1D Gaussian. A mixture of \(N\) Gaussians just requires outputting \(3N\) numbers: the mean, variance, and weight of each Gaussian in the mixture. The loss function could then just be the data likelihood under the mixture of Gaussians parameterized by \(\hat{\mathbf{y}} \in \mathbb{R}^{3N}\).
One of the most common choices for an expressive, multimodal family of distributions is the categorical distribution, \(\texttt{Cat}\). This distribution applies only to discrete random variables, so to use it, the first thing we have to do is quantize our possible output values. Figure 34.1 (d) shows an example, where we have quantized the \(a\)-value into ten bins. Then the categorical distribution is simply a ten-dimensional vector of nonnegative numbers that sum to 1 (i.e., a probability mass function). The nice thing about this parameterization is that all probability mass functions over \(k\) classes are members of the family \(\texttt{Cat}(k)\). In other words, this is the most expressive distribution possible over a discrete random variable! That’s great because it means we can use it to represent predictions with any number of modes (well, up to \(k\), the resolution of our quantized data).
In fact, we have already seen one super important use of the categorical distribution: softmax regression Section 9.7.3. Now you might have a better understanding of why classification is such a ubiquitous modeling tool: it models a maximally expressive predictive distribution over a quantized decision space.
Remember that softmax regression is a way to solve a classification problem. It is called regression since we predict a set of continuous numbers (a probability distribution), then take the argmax of this set to perform the classification.
34.2.2 Classification to the Rescue?
Classification solves some of the deficiencies of point prediction. However, it comes with several new problems of its own:
It incurs quantization error.
It may require a number of classes exponential in the data dimensionality.
The first is not such a big issue. You can see its effect in Figure 34.1 (d). The true colors are teal and bright pink but the quantization lowers the color resolution and we cannot know if the prediction is that the shirt is dull pink or bright pink as both fall in the same bin. This is why the pink shirt here appears slightly duller than in the data distribution (we colored each bin with the floor of its range). But generally this isn’t such a big deal. We can always increase the resolution by increasing \(k\). Most image formats only represent 256 possible values for \(a\), so if we set \(k=256\) then we incur no quantization error.
Why 256 values? Because each channel in standard image formats is stored as an array of uint8s.
The second issue is much more severe. If we are predicting the \(a\)-value of a single pixel, then the classification approach says there are \(k\) possible values it could take on. This approach can be extended to predicting \(ab\)-values: we come up with a list of discrete color classes, like red, orange, turquoise, and so forth. But to tile the two-dimensional space of \(ab\)-values will require \(k^2\) color classes, if we wish to retain a resolution of \(k\) for both \(a\) and \(b\). Nonetheless, we can still do this using a reasonable number of classes, and it might look like as shown in Figure 34.2.
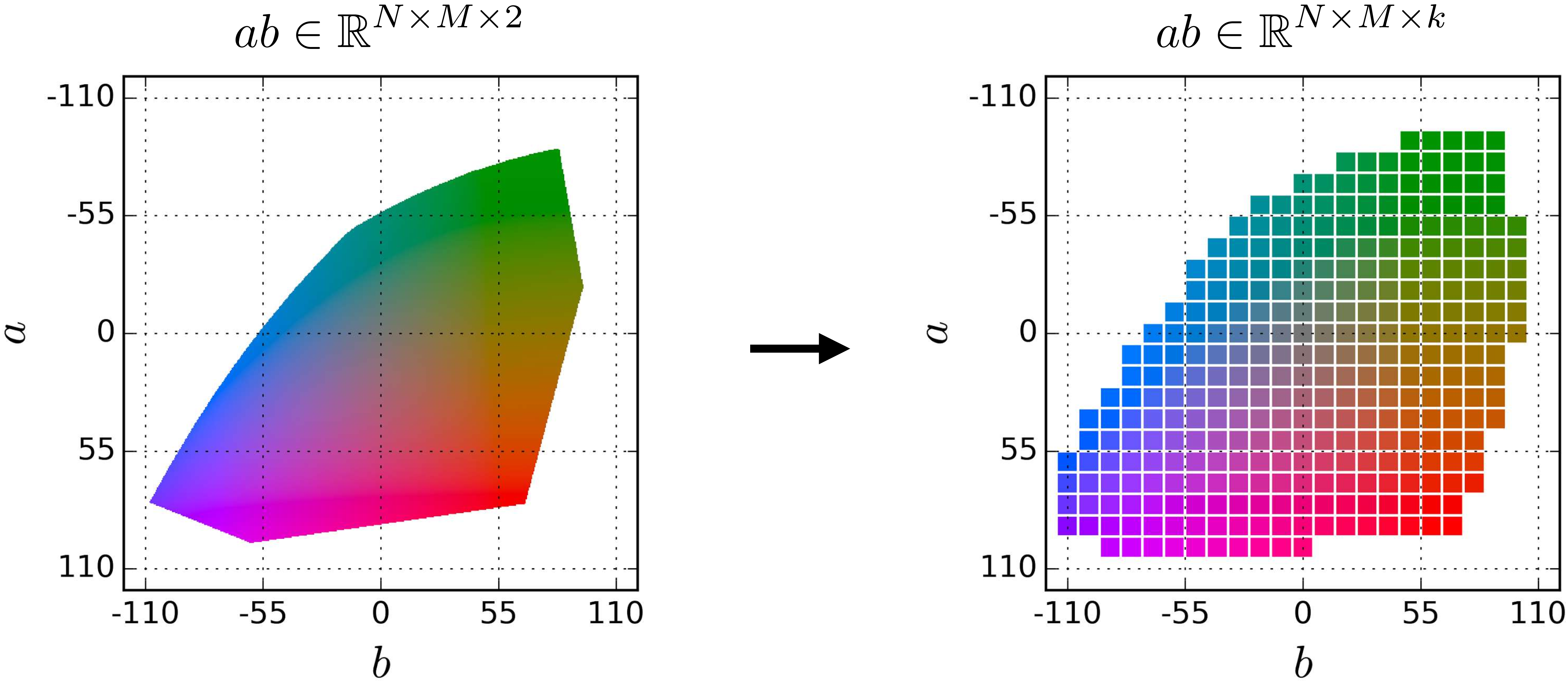
The real problem comes about when predicting more than one pixel. To quantize the \(ab\)-values of \(N\) pixels requires \(k^{2N}\) classes, again assuming we want a resolution of \(k\) for the \(a\) and \(b\) value of each pixel. For a \(256 \times 256\) resolution image, the number of classes required is astronomical (for \(k=10\), the number is a one followed by over 100,000 zeros).
Quantizing on a grid doesn’t scale to high-dimensions, but more intelligent quantization methods can work. These more intelligent methods are called vector quantization or clustering, and we cover them in Chapter 30.
34.2.3 The Failure of Independent Predictions: Joint Structure
To circumvent this curse of dimensionality, we can turn to factorization: rather than treating the whole configuration of pixels as a class, make independent predictions for each pixel in the image. From a probabilistic inference perspective, the corresponds to the following factorization of the joint distribution: \[\begin{aligned} p_{\theta}(\mathbf{ab} \bigm | \mathbf{l}) = \prod_{n=1}^N\prod_{m=1}^M p_{\theta}(ab[n,m,:] \bigm | \mathbf{l}) \end{aligned}\]
Note the similarity between this image model and the “independent pixels” model we saw in Equation 27.1 in Chapter 27. The present model can represent images with more structure because rather than assuming the pixels are all completely independent (i.e., marginally independent), it only assumes the pixel colors are conditionally independent, conditioned on the luminance image (which provides a great deal of structure).
The underlying assumption of this factorization is one of conditional independence: each pixel’s \(ab\) value is considered to be conditionally independent from all other pixels’ \(ab\) values, given the observed luminance (of all pixels). This is a very common assumption in image modeling problems: in fact, whenever you use least-squares regression for a multidimensional prediction, you are implicitly making this same assumption. To see this, suppose you are predicting a vector \(\mathbf{y}\) from an observed vector \(\mathbf{x}\), and your prediction is \(\hat{\mathbf{y}} = f(\mathbf{x})\). Then, we can write the least-squares objective (\(L_2\)) as: \[\begin{aligned} -\left\lVert\hat{\mathbf{y}} - \mathbf{y}\right\rVert^2_2 &= \sum_i -(\hat{y}_i - y_i)^2\\ &= \log \prod_i \phi(\hat{y}_i,y_i) \end{aligned}\] The loss factorizes as a product over pairwise potentials. Therefore, by the Hammersley-Clifford theorem (Chapter 29), the \(L_2\) loss implies a probability distribution that treats all true values \(y_i\) as independent from one another, given all the predictions \(\hat{y}_i\). The predictions are a function of just the input \(\mathbf{x}\), so the implication is that all the true values \(y_i\) are independent from one another given the observation \(\mathbf{x}\). Therefore, we have arrived at our conditional independence assumption: each dimension’s predicted value is assumed to be independent of each other dimension’s predicted values, given the observed input. This is a huge assumption and rarely true of prediction problems in computer vision!
So, whether you are using per-pixel classification, or least-squares regression, you are implicitly fitting a model that assumes independence between all the output pixels, conditioned on the input. This is called unstructured prediction.
This causes problems. Let’s return to our t-shirt example. We will use a per-pixel color classifier and see where it fails. Since the data distribution has two equally probable modes—teal and pink—the classifier will learn to place roughly equal probability mass on these two modes. As training data and time go to infinity, the classifier should recover the exact data distribution, but with finite data and time it will only be approximate, and so we might have a case where for some luminance values the classifier places 51 percent chance on teal and for others it places 49 percent on teal. Then if, as we scan across pixels in the shirt we are observing, the luminance changes very slightly, the model predictions might wiggle back and forth between 49 percent and 51 percent teal. As our application is to colorize the photo, at some point we need to make a hard decision and output a single color for each pixel. Doing so in the present case will cause chaotic transitions from predicting pink (where \(p(\text{teal}) < 0.5\)) and teal (where \(p(\text{teal}) > 0.5\)). An example of this kind of prediction flipping is shown in Figure 34.3.
A real example of color flipping from [1]. The model is unsure whether the shirt, and the background, are blue or red, so it chaotically alternates between these two options. 
34.3 Conditional Generative Models Solve Multimodal Structured Prediction
In the previous section, we learned that standard approaches to prediction are insufficient for making the kinds of predictions we usually care about in computer vision.
Conditional generative models are a general family of prediction methods that:
Model a multimodal distribution of predictions, and
Model joint structure.
Methods that model joint structure in the output space are called structured prediction methods—they don’t factorize the output into independent potentials conditioned on the input. Conditional generative modeling is a structured prediction approach that models a full distribution of possibilities over the joint configuration of outputs.
34.3.1 Relationship to Conditional Random Fields
The conditional random fields (CRFs) from Chapter 29 are one kind of model that fits this definition. Now we will see some other ones. The big difference is that CRFs make predictions via thinking slow [2]: given a query observation, you run belief propagation or another iterative inference algorithm to arrive at a prediction. The conditional generative models we will see in this section think fast: they do inference through a single forward pass of a neural net. Sometimes the thinking fast approach is referred to as amortized inference, where the idea is that the cost of inference is amortized over a training phase. This training phase learns a direct mapping from inputs to outputs that approximates the solution we would have gotten if we did exact inference on that input.
34.4 A Tour of Popular Conditional Models
We saw a bunch of unconditional generative models in the previous chapters. How can we make each conditional? It is usually pretty straightforward. This is because if you can model an arbitrary distribution over a random variable, \(p(Y)\), then you can certainly model the conditional distribution \(p(Y \bigm | X=\mathbf{x})\)—it’s just another arbitrary distribution. Of course, we typically care about modeling \(p(Y \bigm | X=\mathbf{x})\) for all possible settings of \(\mathbf{x}\). We could, but don’t want to, fit a separate generative model for each \(\mathbf{x}\). Instead we want neural nets that take a query \(\mathbf{x}\) as input and produce an output that models or samples from \(p(Y \bigm | X=\mathbf{x})\). We will briefly cover how to do this for several popular models:
In this chapter, \(Y\) is the image we are generating and \(X\) is the data we are conditioning on. Note that this is different than in the previous generative modeling chapters Chapter 32 and Chapter 33, where \(X\) was the image we were generating, unconditionally.
34.4.1 Conditional Generative Adversarial Networks
We can make a generative adversarial network (GAN; Section 32.9 conditional simply by adding \(\mathbf{x}\) as an input to both the generator and the discriminator: \[\begin{aligned} \arg\min_{\theta}\max_{\phi} \mathbb{E}_{\mathbf{z},\mathbf{x},\mathbf{y}} \big[ \log d_{\phi}(\mathbf{x}, g_{\theta}(\mathbf{x},\mathbf{z})) + \log (1 - d_{\phi}(\mathbf{x}, \mathbf{y})) \big] \end{aligned}\] What this does is change the job of the discriminator from asking “is the output real or synthetic?” to asking “is the input-output pair real or synthetic?” An input-output pair can be considered synthetic for two possible reasons:
The output looks synthetic.
The output does not match the input.
If both reasons are avoided, then it can be shown that the produced samples are \(iid\) with respect to the true conditional distribution of the data \(p_{\texttt{data}}(Y \bigm | \mathbf{x})\) (this follows from the analogous proof for unconditional GANs in [3], since that proof applies to modeling any arbitrary distribution over \(Y\), including \(p_{\texttt{data}}(Y \bigm | \mathbf{x})\) for any \(\mathbf{x}\)).
34.4.2 Conditional Variational Autoencoders
Recall that a variational autoencoder (VAE; Section 33.4 is an infinite mixture model which makes use of the following identity: \[\begin{aligned} p_{\theta}(\mathbf{x}) = \int_{\mathbf{z}} p_{\theta}(\mathbf{x} \bigm | \mathbf{z})p_{\mathbf{z}}(\mathbf{z})d\mathbf{z} \end{aligned}\] Analogously, we can define any conditional distribution as the marginal over some latent variable: \[\begin{aligned} p_{\theta}(\mathbf{y} \bigm | \mathbf{x}) = \int_{\mathbf{z}} p_{\theta}(\mathbf{y} \bigm | \mathbf{z}, \mathbf{x})p_{\mathbf{z}}(\mathbf{z} \bigm | \mathbf{x})d\mathbf{z} \end{aligned}\] In conditional VAEs (cVAEs), we restrict our attention to latent variables \(\mathbf{z}\) that are independent of the inputs we are conditioning on, so we have: \[\begin{aligned} p_{\theta}(\mathbf{y} \bigm | \mathbf{x}) = \int_{\mathbf{z}} p_{\theta}(\mathbf{y} \bigm | \mathbf{z}, \mathbf{x})p_{\mathbf{z}}(\mathbf{z})d\mathbf{z} \quad\quad \triangleleft \quad\text{cVAE likelihood model} \end{aligned}\]
This corresponds to this graphical model: 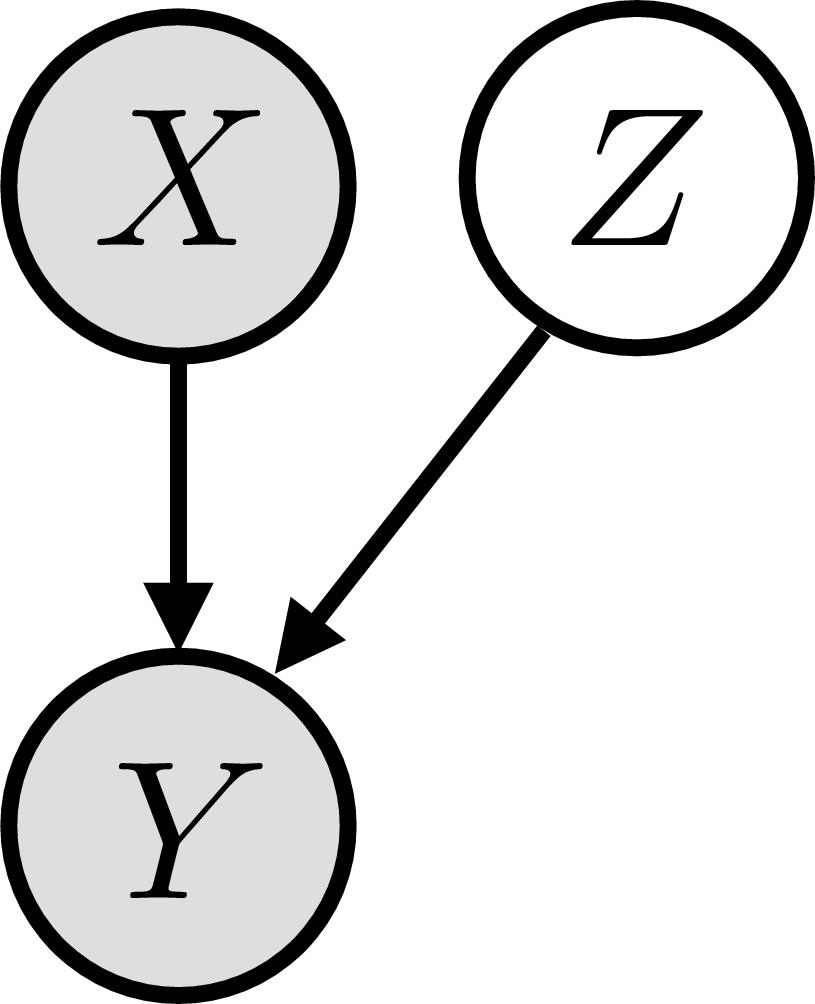
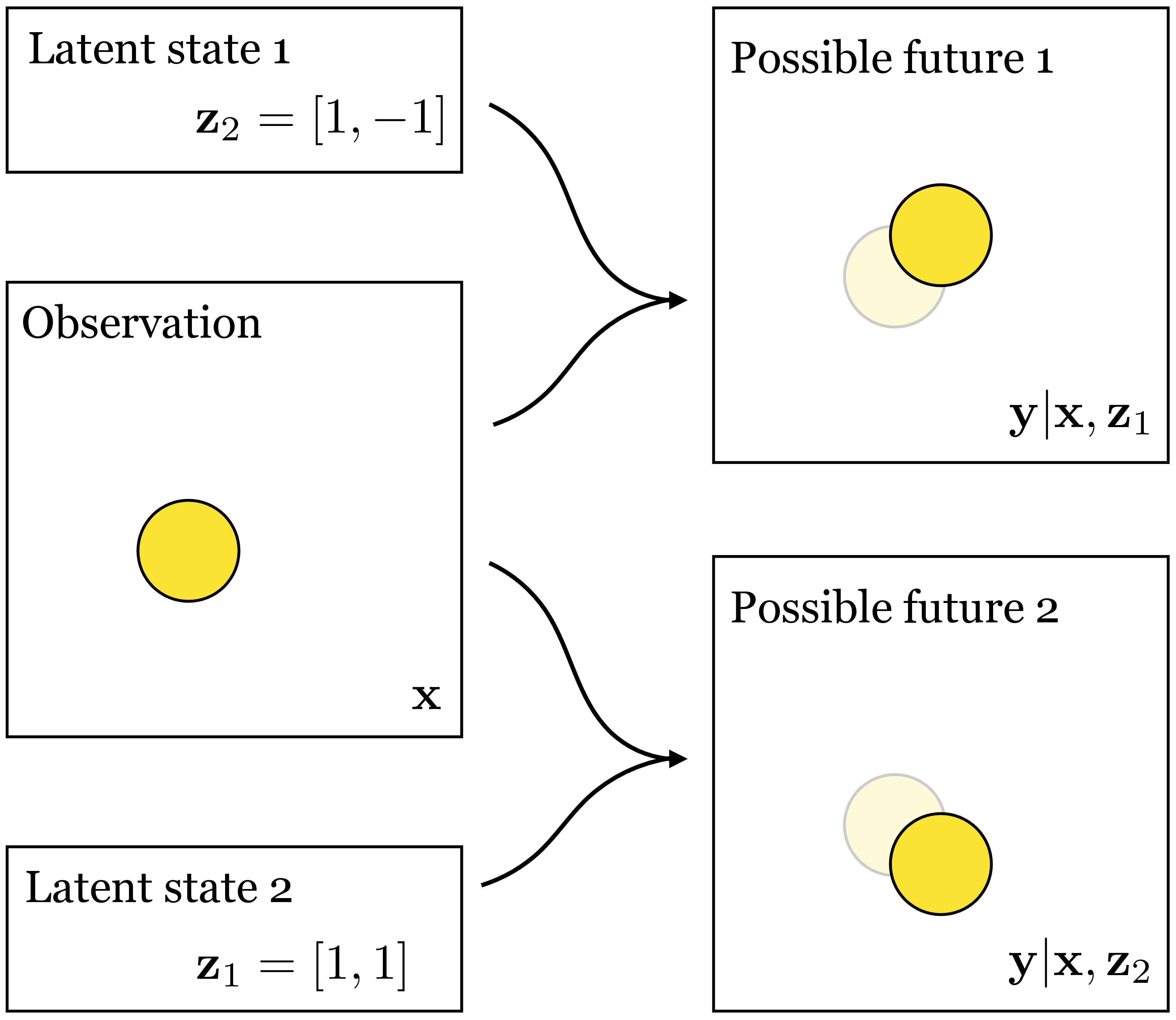
The idea is that \(\mathbf{z}\) should only encode bits of information about \(\mathbf{y}\) that are independent from whatever \(\mathbf{x}\) already tells us about \(\mathbf{y}\). For example, suppose that we are trying to predict the motion of a billiard ball bouncing around in a video sequence. We are given a single frame \(\mathbf{x}\) and asked to predict the next frame \(\mathbf{y}\). Only knowing \(\mathbf{x}\) we can’t know whether the ball will move up, down, diagonally, and so on, but we can know what color the ball will be in the next frame (it must be the same as the previous frame) and the rough position on the screen of the ball (it can’t have moved too far). Therefore, the only missing information about \(\mathbf{y}\), given we know \(\mathbf{x}\), is the velocity of the ball. Naturally, then, if the model learns to interpret \(\mathbf{z}\) as coding for velocity, we would have a perfect prediction \(p_{\theta}(\mathbf{y} \bigm | \mathbf{z}, \mathbf{x})\) (one that places max likelihood on the observed next frame \(\mathbf{y}\)), and marginalizing over all the possible \(\mathbf{z}\) values would place max likelihood on the data (\(p_{\theta}(\mathbf{y} \bigm | \mathbf{x})\)). This is what ends up happening in a cVAE (or, to be precise, it is one solution that maximizes the cVAE objective; it is not guaranteed to be the solution that is arrived at, but it is a good model of what tends to happen in practice). Figure 34.4 shows this scenario.
Just like regular VAEs, cVAEs also have an encoder, which acts to predict the optimal importance sampling distribution \(p_{\theta}(Z \bigm | \mathbf{x}, \mathbf{y})\). In practice, this means that a cVAE can be trained just like a regular VAE except that the encoder takes the conditioning information, \(\mathbf{x}\), as input (in addition to \(\mathbf{y}\)), and the decoder also takes in \(\mathbf{x}\) (in addition to \(\mathbf{z}\)). Figure 34.5 depicts this setting.

34.4.3 Conditional Autoregressive Models
Autoregressive models Section 32.7 are already modeling a sequence of conditional distributions. So, to condition them on some inputs \(\mathbf{x}\), we can simply concatenate \(\mathbf{x}\) as a prefix to the sequence of \(y\) values we are modeling, yielding the new sequence: \([x_1, \ldots, x_m, y_1, \ldots, y_n]\). The probability model factorizes as: \[\begin{aligned} p_{\theta}(\mathbf{y} \bigm | \mathbf{x}) &= \prod_{i=1}^n p_{\theta}(y_i \bigm | y_1, \ldots, y_{i-1}, x_1, \ldots, x_m) \end{aligned}\] Each distribution in this product is a prediction of the next item in a sequence given the previous items, which is no different than what we had for unconditional autoregressive models. Therefore, the tools for modeling unconditional autoregressive distributions are also appropriate for modeling conditional autoregressive distributions. From an implementation perspective, the same exact code will handle both cases, just depending on whether you prefix the sequence or not.
34.4.4 Conditional Diffusion Models
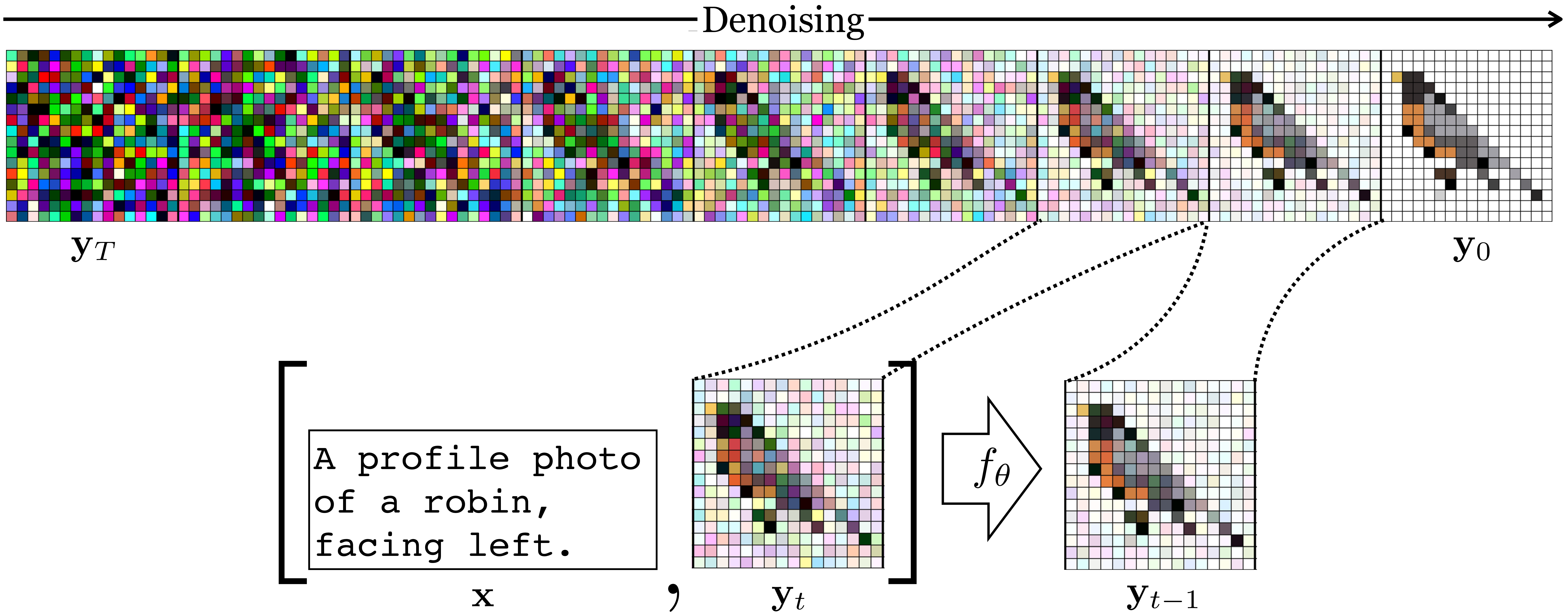
Diffusion models Section 32.8 are quite similar to autoregressive models and they can be made conditional in a similar way. All we need to do is concatenate the conditioning variables, \(\mathbf{x}\), into the input to the denoising function: \[\begin{aligned} \hat{\mathbf{y}}_{t-1} = f_{\theta}(\mathbf{y}_t, t, \mathbf{x}) \end{aligned}\]
Both diffusion models and autoregressive models convert generative modeling into a sequence of supervised prediction problems. To make them conditional is therefore just as easy as conditioning a supervised learner on more observations. If the original training pairs are \(\{\mathbf{x}^{(i)}, \mathbf{y}^{(i)}\}_{i=1}^N\), we can condition on additional paired observations \(\mathbf{c}\) by augmenting the pairs to become \(\{[\mathbf{x}^{(i)}, \mathbf{c}^{(i)}], \mathbf{y}^{(i)}\}_{i=1}^N\).
An example where we condition on text is shown in Figure 34.6. The intuition is that if we give \(f_{\theta}\) a description of the image as an additional input, then it can do a better job at solving its prediction task. Because of this, \(f_{\theta}\) will become sensitive to the text command, and if you give different text it will denoise toward a different image—an image that matches that text! In Section 51.3 we will describe in more detail a particular neural architecture for text-to-image synthesis, which is based on this intuition.
34.5 Structured Prediction in Vision
Whenever you want to make a prediction of an image, conditional generative models are a suitable modeling choice. But how often do we really want to predict images? Yes, image colorization is one example, but isn’t that more of a graphics problem? Most problems in vision are about predicting labels or geometry, right?
Well yes, but what does label prediction look like? The input is an image and the output is label map. In image classification the output might just be a single class, but more generally, in object detection and semantic segmentation, we want a label for each part of the image. The target output in these problems is high-dimensional and structured. Or consider geometry estimation: the output is a depth map, or a voxel grid, or a mesh, and so on. All these are high-dimensional structured objects. The tool we need for solving these problems is structured prediction, and conditional generative models are therefore a good choice. In the next sections we will see two important families of structured prediction methods used in vision.
34.6 Image-to-Image Translation
Image-to-image problems are mapping problems where the input is an image and the output is also an image, where we will here think of an image as any array of size \(N \times M \times C\) (height by width by number of channels). These problems are very common in computer vision. Examples include colorization, next frame prediction, depth map estimation, and semantic segmentation (a per-pixel label map is also an image, just with \(K\) channels, one for each label, rather than three channels, one for each color channel). One way to think about all these problems is as translating from one view of the data to another; for example, semantic segmentation is a translation from viewing the world in terms of its colors to viewing the world in terms of its semantics. This perspective yields the problem of image-to-image translation [4]; just like we can translate from English to French, can we translate from pixels to semantics, or perhaps from a photographic depiction of scene to a painting of that same scene?
34.6.1 Image-to-Image Translation with a Conditional GAN
One approach to image-to-image translation is to use a conditional GAN, as was popularized in the “pix2pix” paper [4] (whose method we will follow here). To illustrate this approach, we will look at the problem of translating a facade layout map into a photo. In this setting, the conditioning information (input) is a layout map showing where all the architectural elements are positioned on the facade (i.e., a semantic segmentation image of the facade, with colors indicating where the windows, doors, and so on are located), and the output is a matching photo. The generator therefore maps an image to an image so we will implement it with an image-to-image neural architecture. This could be a convolutional neural network (CNN), or a transformer; following the pix2pix paper we will use a U-Net (a CNN with accordion-shaped skip connections; see Section 24.11.2. The discriminator maps the output image to a real-versus-synthetic score (a scalar), so for the discriminator we will use a regular CNN (just like the ones used for image classification). Here is the full architecture (Figure 34.7):
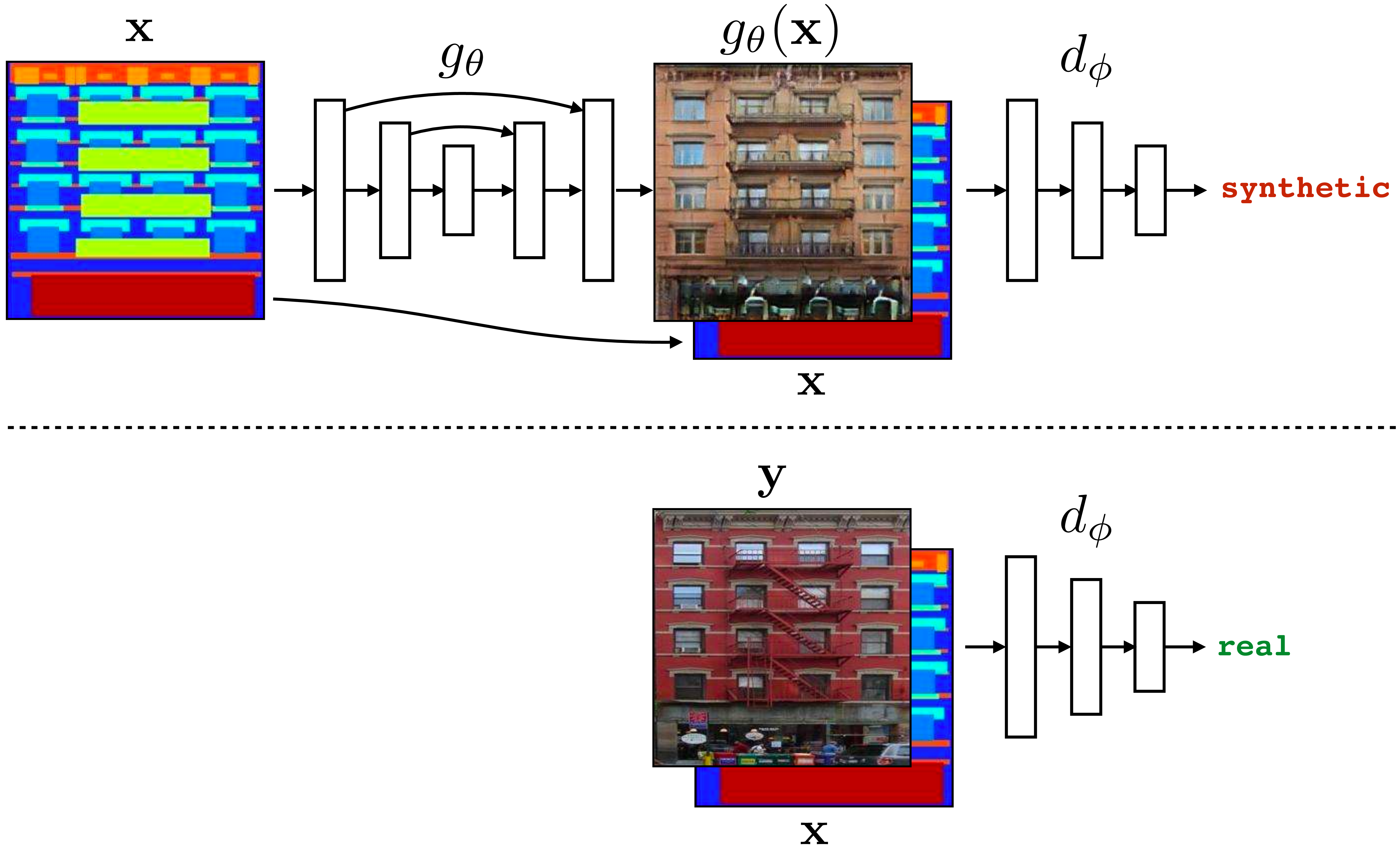
Notice that we have omitted the noise inputs here; instead the generator only takes as input the image \(\mathbf{x}\). It turns out that in this setting the noise is not really a necessary input, and many implementations omit it. This is because the input image \(\mathbf{x}\) has enough entropy by itself, and you don’t necessarily need additional noise to create variety in the outputs of the model. The downside of this approach is that you only get one prediction \(\mathbf{y}\) for each input \(\mathbf{x}\).
One way to think about this setup is that it is a regression problem with a learned loss function \(d_{ \phi}\), a view shown in Figure 34.8.
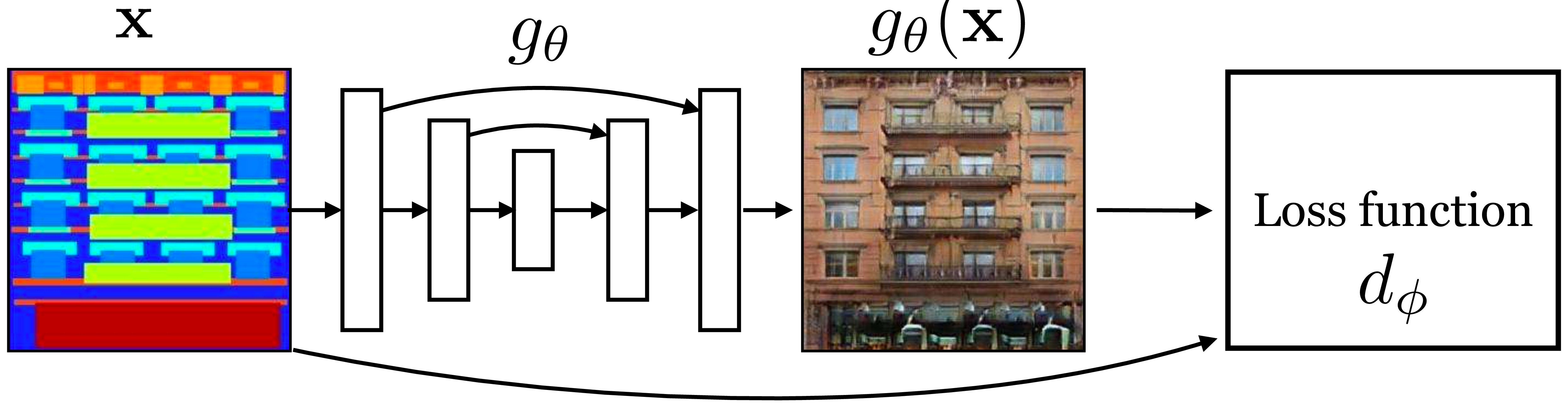
This loss function adapts to the structure of the data and the behavior of the generator to penalize just the relevant errors the generator is currently making. It can help to also add a conventional regression loss, such as the \(L_1\) loss, to stabilize the optimization process, yielding the following objective: \[\begin{aligned} \arg\min_G\max_D \mathbb{E}_{\mathbf{z},\mathbf{x},\mathbf{y}} \big[ \log d_{\phi}(\mathbf{x}, g_{\theta}(\mathbf{x},\mathbf{z})) + \log (1 - d_{\phi}(\mathbf{x}, \mathbf{y})) + \left\lVert g_{\theta}(\mathbf{x}) - \mathbf{y}\right\rVert_1 \big] \end{aligned} \tag{34.1}\]
Thinking of \(d_{\phi}\) as a learned loss function raises new questions: What does this loss function penalize, and how can we control its properties. One of the main levers we have is the architecture of \(d_{\phi}\); different architectures will have the capacity, and/or inductive bias, to penalize different kinds of errors. One popular architecture for image-to-image tasks is a PatchGAN discriminator [4], in which we score each patch in the output image as real or fake and take the average over patch scores as our total loss: \[\begin{aligned} d_{\phi}(\mathbf{x}, \mathbf{y}) = \frac{1}{NM} \sum_{i=0}^N \sum_{j=0}^M d_{\phi}^{\texttt{patch}}(\mathbf{x}[i:i+k,j:j+k], \mathbf{y}[i:i+k,j:j+k]) \end{aligned} \tag{34.2}\] where \(k \times k\) is the patch size. Notice that this operation is equivalent to the sliding window action of CNN, so \(d_{\phi}^{\texttt{patch}}\) can simply be implemented as a CNN that outputs a \(2 \times N \times M\) feature map of real-versus-synthetic scores. Naturally, patches can be sampled at different strides and resolutions, depending on the exact architecture of the CNN \(d_{\phi}^{\texttt{patch}}\).
The PatchGAN strategy has two advantages over just scoring the whole image as real or synthetic with a classifier architecture: (1) it can be easier to model if a patch is real or synthetic than to model if an entire image is real or synthetic (\(d_{\phi}^{\texttt{patch}}\) needs fewer parameters), (2) there are more patches in the training data than their are images. These two properities give PatchGAN discriminators a statistical advantage over whole image discrimatinators (fewer parameters fit to more data). The disadvantage is that the PatchGAN only has the architectural capacity to penalize errors that are observable within a single patch. This can be seen by training models with different discriminator patch sizes and observing the results. We show this in Figure 34.9.

A \(1\times1\) discriminator can only observe a single pixel at a time and cannot penalize errors in joint pixel statistics such as edge structure, hence the blurry results. Larger receptive fields can enforce higher order patch realism, but cannot model structure larger than the patch size (hence the tiling artifacts that are occur with a period roughly equal to the patch size). Quality degrades with the \(286\times286\) discriminator possibly because this disciminator has too hard a task given the limited training data (in any given training set, there are fewer examples of \(286\times286\) regions than there are of, say, \(70\times70\) regions).
34.6.2 Unpaired Image-to-Image Translation
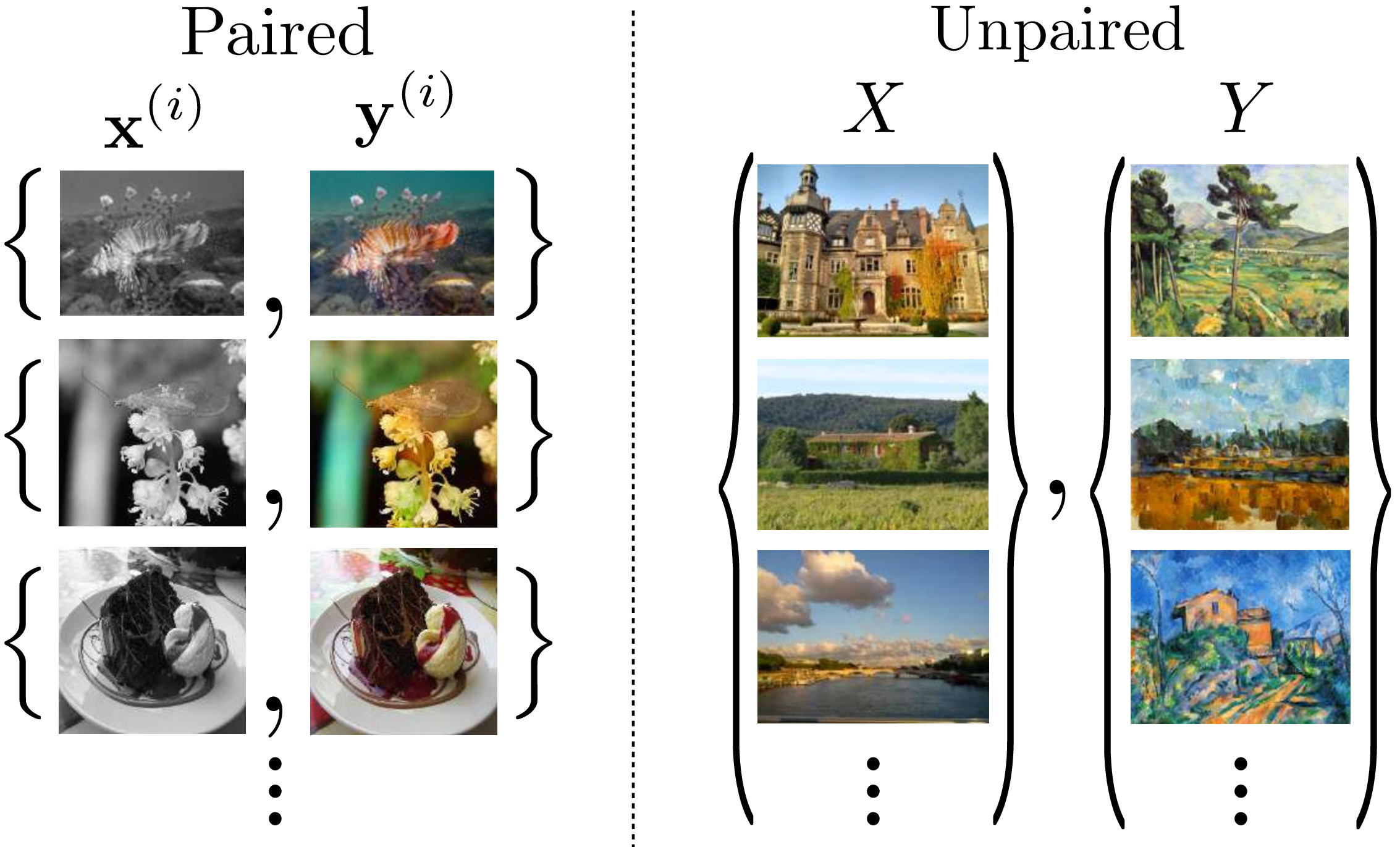
In the preceding section we saw how to solve image-to-image translation by treating it just like a supervised regression problem, except using a learned loss function given by a GAN discriminator. This approach works great when we have lots of training data pairs \(\{\mathbf{x}, \mathbf{y}\}\) to learn from. Unfortunately, very often, paired training data is hard to obtain. For example, consider the task of translating a photo into a Cezanne painting (Figure 34.10):

The task depicted here is to predict: What would it have looked like if Cezanne had stood at this riverbank and painted it?
How could this be done? We can’t have solved it with paired training data because, in this setting, paired data is extremely hard to come by. We would have to resurrect Cezanne and ask him to paint for us a bunch of new scenes, one for each photo in our desired training set. But is all that effort really necessary? You and I, as humans, can certainly imagine the answer to the previous question. We know what Cezanne’s style looks like and can reason about the changes that would have to occur to make the photo match his style. Dabs of paint would have to replace the photographic pixels, and the colors should take on more pastel tones. We can imagine the necessary stylistic changes because we have seen many Cezanne paintings before, even though we didn’t see them paired with a photograph of the exact same scenes. Let’s now see how we can give a machine this same ability. We call this setting the unpaired translation setting, and distinguish it from paired translation as indicated in Figure 34.11.
It turns out that GANs have a very useful property that makes them well-suited to solving this task. GANs train a mapping from a noise distribution to a data distribution \(p(Z) \rightarrow p(X)\). They do this without knowing the pairing between \(\mathbf{z}\) and \(\mathbf{x}\) values in the training data. Instead this pairing is emergent. Which \(\mathbf{z}\)-vector corresponds to which \(\mathbf{x}\) is not predetermined but self-organizes to satisfy the GAN objective (all \(\mathbf{z}\)-vectors should map to realistic images, and, collectively they should map to the data distribution).
Now consider training a GAN to map from \(\mathbf{x}\) to \(\mathbf{y}\) values:
\[\begin{aligned} \arg\min_{\theta}\max_{\phi} \mathbb{E}_{\mathbf{x},\mathbf{y}} \big[ \log d_{\phi}(g_{\theta}(\mathbf{x})) + \log (1 - d_{\phi}(\mathbf{y})) \big] \end{aligned} \tag{34.3}\]
Note that this is a regular GAN objective rather than a conditional GAN, except that we have relabeled the variables compared to \(\eqref{eq-conditional_generative_models-x_to_y_GAN_learning_problem}\), with \(\mathbf{y}\) playing the role of \(\mathbf{x}\) and \(\mathbf{x}\) playing the role of \(\mathbf{z}\).
Such a GAN would self-organize so that the outputs are realistic \(\mathbf{y}\) values and so that different inputs map to different outputs (collectively they must map to the data distribution over possible \(\mathbf{y}\) values). No paired supervision is required to achieve this.
Such a GAN may indeed learn the correct mapping from \(\mathbf{x}\) to \(\mathbf{y}\) values—that’s one of the solutions that minimizes the loss—but there are many symmetries in this learning problem, that is, many different mappings achieve equivalent loss. For example, consider that we permute the mapping: if \(\{\mathbf{x}^{(i)}, \mathbf{y}^{(i)}\}\) is the true mapping then consider we instead recover \(\{\mathbf{x}^{(i)}, \mathbf{y}^{(i+1)}\}\) after learning (circularly shifting at the boundary). This mapping achieves equal loss to the true mapping, under the standard GAN objective Equation 34.3.
This is because any permutation in the mapping does not affect the output distribution, and the GAN objective only cares about the output distribution.
Put another away, the GAN discriminator is different than a normal loss function. Rather than checking if the output matches a target instance (that \(g_{\theta}(\mathbf{x}^{(i)})\) matches \(\mathbf{y}^{(i)})\), it checks if the output is part of an admissible set, that is, the set of things that look like realistic \(\mathbf{y}\) values. This property makes GANs perfect for working with unpaired data, where we don’t have instance-level supervision but only have set-level superversion.
We call this unpaired learning rather than unsupervised because we still have supervision in the form of labels indicating which set each datapoint belongs to. That is, we know whether each image is an \(\mathbf{x}\) or a \(\mathbf{y}\).
So, a regular GAN objective, applied to mapping from \(X\) to \(Y\), solves the unpaired translation problem, but it does not distinguish between the correct mapping and the many other mappings that achieve the same output distribution. To break the symmetry we need to add additional constraints or inductive biases. One that works especially well is cycle-consistency, which was introduced in this context by CycleGAN [6], DualGAN [7], and DiscoGAN [8], which are all essentially the same model. The idea of cycle-consistency is that if we translate from \(X\) to \(Y\) and then translate back (from \(Y\) to \(X\)) we should arrive where we started. Think about translating from English to French, for example. If we translate “apple” to French, “apple”\(\rightarrow\)“pomme,” and then translate back, “pomme”\(\rightarrow\)“apple,” we arrive where we started.
In natural language processing, the idea of cycle-consistency is known as backtranslation.
We can check the quality of a translation system, for a language we are unfamiliar with, by using this trick. If translating back does not return the word we started with then something went wrong with the translation model. This is because we expect language translation to be roughly one-to-one: for each word in English there is usually an equivalent word in French. Cycle-consistency losses are regularizers that encourage a learned mapping to be roughly one-to-one. The cycle-consistency losses from CycleGAN are simply:
\[ \begin{aligned} \mathcal{L}_{\texttt{cyc}}(\mathbf{x};g_{\theta},f_{\psi}) &= \left\lVert\mathbf{x} - f_{\psi}(g_{\theta}(\mathbf{x}))\right\rVert_1\\ \mathcal{L}_{\texttt{cyc}}(\mathbf{y};g_{\theta},f_{\psi}) &= \left\lVert\mathbf{y} - g_{\theta}(f_{\psi}(\mathbf{y}))\right\rVert_1 \end{aligned} \]
Adding this loss to Equation 34.3 yields the complete CycleGAN objective: \[ \begin{aligned} \arg\min_{\theta,\psi}\max_{\phi} \mathbb{E}_{\mathbf{x},\mathbf{y}} \big[ \log d_{\phi}^{Y}(g_{\theta}(\mathbf{x})) + \log (1 - d_{\phi}^{Y}(\mathbf{y})) + \left\lVert\mathbf{x} - f_{\psi}(g_{\theta}(\mathbf{x}))\right\rVert_1 + \\ \log d_{\phi}^{X}(f_{\psi}(\mathbf{y})) + \log (1 - d_{\phi}^{X}(\mathbf{x})) + \left\lVert\mathbf{y} - g_{\theta}(f_{\psi}(\mathbf{y}))\right\rVert_1 \big] \end{aligned} \]
This model translates from domain \(X\) to domain \(Y\) and back, such that the outputs in domain \(Y\) look realistic according to a domain \(Y\) discriminator, and vice versa for domain \(X\), and the mappings are cycle-consistent: one complete cycle from \(X\) to \(Y\) and back should arrive where it started (and, again, vice versa). A diagram for this whole process is given in Figure 34.12:
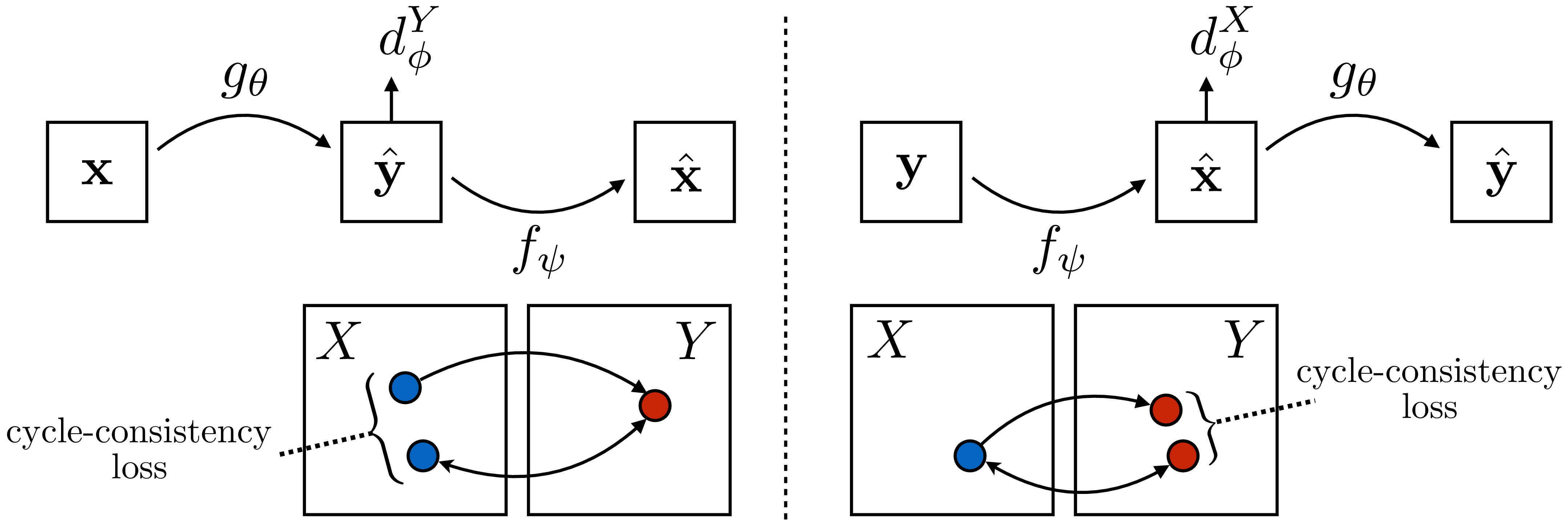
The cycle-consistency losses encourage that the translation is a one-to-one function, and thereby reduce the number of valid solutions. This is a good idea when the true solution is indeed one-to-one, as is often the case in translation problems. However, other symmetries still exist and may confound methods like CycleGAN: if we permute the correct \(X\)-to-\(Y\) mapping and apply the inverse permutation to the \(Y\)-to-\(X\) mapping, then CycleGAN will still be satisfied but the mapping will now be incorrect.
34.7 Concluding Remarks
Many problems in vision can be phrased as structured prediction, and conditional generative models are a great approach to these problems. They provide a unified and simple solution to a diverse array of problems. A current trend in computer vision (and all of artificial intelligence) is to replace bespoke systems for specific kinds of structured prediction—object detectors, image captioning systems, and so on—with general-purpose conditional generative models. This is one reason why this book does not focus much on special-purpose systems that solve specific problems in vision—because the trend is toward general-purpose modeling tools.