50 Object Recognition
50.1 Introduction
There are many tasks that researchers use to address the problem of recognition. Although the ultimate goal is to tell what something it is by looking at it, the way that you will answer the question will change the approach that you will use. For instance, you could say, “That is a chair” and just point at it, or we could ask you to indicate all of the visible parts of the chair, which might be a lot harder if the chair is partially occluded by other chairs producing a sea of legs. It can be hard to precisely delineate the chair if we cannot tell which legs belong to it. In other cases, identifying what a chair is might be difficult, requiring understanding of its context and social conventions (Figure 50.1).

In this chapter we will study three tasks related to the recognition of objects in images (classification, localization, and segmentation). We will introduce the problem definitions and the formulation that lays the foundations for most existing approaches.
50.2 A Few Notes About Object Recognition in Humans
Object perception is very rich and diverse area of interdiciplinary research. Many of the approached in computer vision are rooted on hypothesis formulated in trying to model the mechanism used by the human visual system. It is useful to be familiar with the literature in cognitive science and neuroscience to understand the origin of existing approaches and to gain insights on how to build new models. Here we will review only a few findings, and we leave the reader with the task of going deeper into the field.
50.2.1 Recognition by Components
One important theory of how humans represent and recognize objects from images is the recognition-by-components theory proposed by Irving Biederman in 1987 [1]. He started motivating his theory with the experiment illustrated in Figure 50.2. Can you recognize the object depicted in the drawing? Does it look familiar? The first observation one can make when looking at the drawing in Figure 50.2 is that it does not seem to be any object we know, instead it seems to be a made-up object that does not correspond to anything in the world. The second observation is that the object seems to be decomposable into parts and that different observers will probably make the same decomposition. The figure can be separated into parts by breaking the object in “regions of sharp concavity”. And the third observation is that the object resembles other known objects. Does it look like an ice cream or hot-dog cart to you?
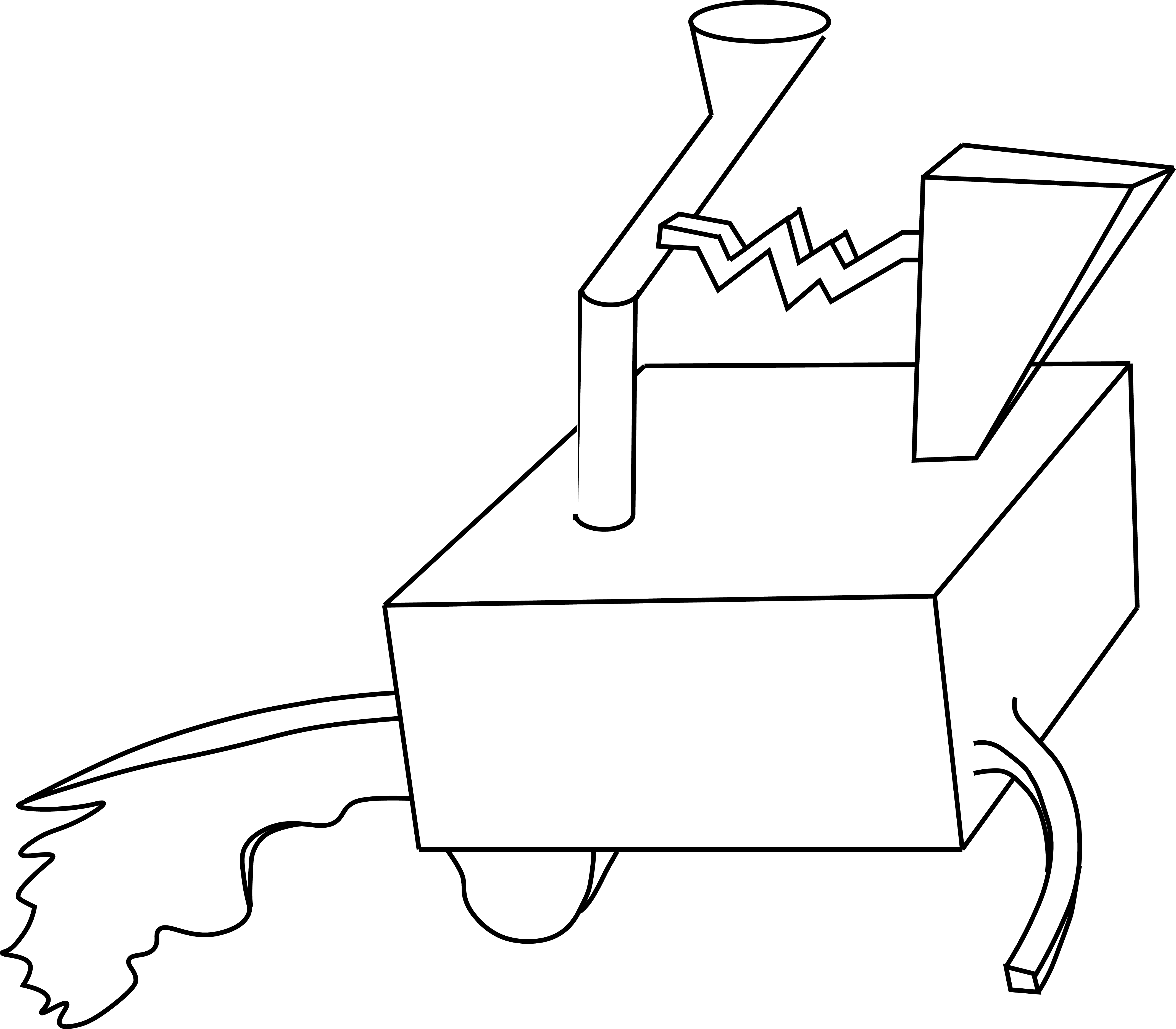
Biederman postulated that objects are represented by decomposing the object into a small set of geometric components (e.g., blocks, cylinders, cones, and so on.) that he called Geons. He derived 36 different Geons that we can discriminate visually. Geons we defined by non-accidental attributes such as symmetry, colinearity, cotermination, parallelism, and curvature. An object is defined by a particular arrangement of a small set of Geons. Object recognition consists in a sequence of stages: (1) edge detection, (2) detection of non-accidental properties, (3) detection of Geons, and (4) matching the detected Geons to stored object representations.
One important aspect of his theory is that objects are formed by compositing simpler elements (Geons), which are shared across many different object classes. Compositionality in the visual world is not as strong as the one found in language, where a fix set of words are composed to form sentences with different meanings. In the visual world, components shared across different object classes will have different visual appearances (e.g., legs of tables and chairs share many properties but are not identical). Geons are great to represent artificial objects (e.g., tables, cabinets, and phones) but fail when applied to represent stuff (e.g., grass, clouds, and water) or highly textured objects such as trees or food.
Decomposing an object into parts has been an important ingredient of many computer vision object recognition systems [2], [3], [4].
50.2.2 Invariances
Object recognition in humans seems to be quite robust to changes in viewpoint, illumination, occlusion, deformations, styles, and so on. However, perception is not completely invariant to those variables.
One well studied property of the human visual system is its invariance to image and 3D rotations. As we discussed in chapter Chapter 35, studies in human visual perception have shown that objects are recognized faster when they appear in canonical poses. In a landmark study, Roger N. Shepard and Jaqueline Metzler [5] showed to participants pairs of drawings of three-dimensional objects (Figure 50.3). The pair of drawings could show the same object with a mirror or the same object with an arbitrary 3D rotation. The task consisted in deciding if the two objects were identical (up to a 3D rotation) or mirror images of each other. During the experiment, they recorded the success rate and the reaction time (how long did participant took to answer). The result showed that participants had a reaction time proportional to the rotation angle between the two views. This supported the idea that participants were performing a mental rotation in order to compare both views. Whether humans actually perform mental rotations or not still remains controversial.
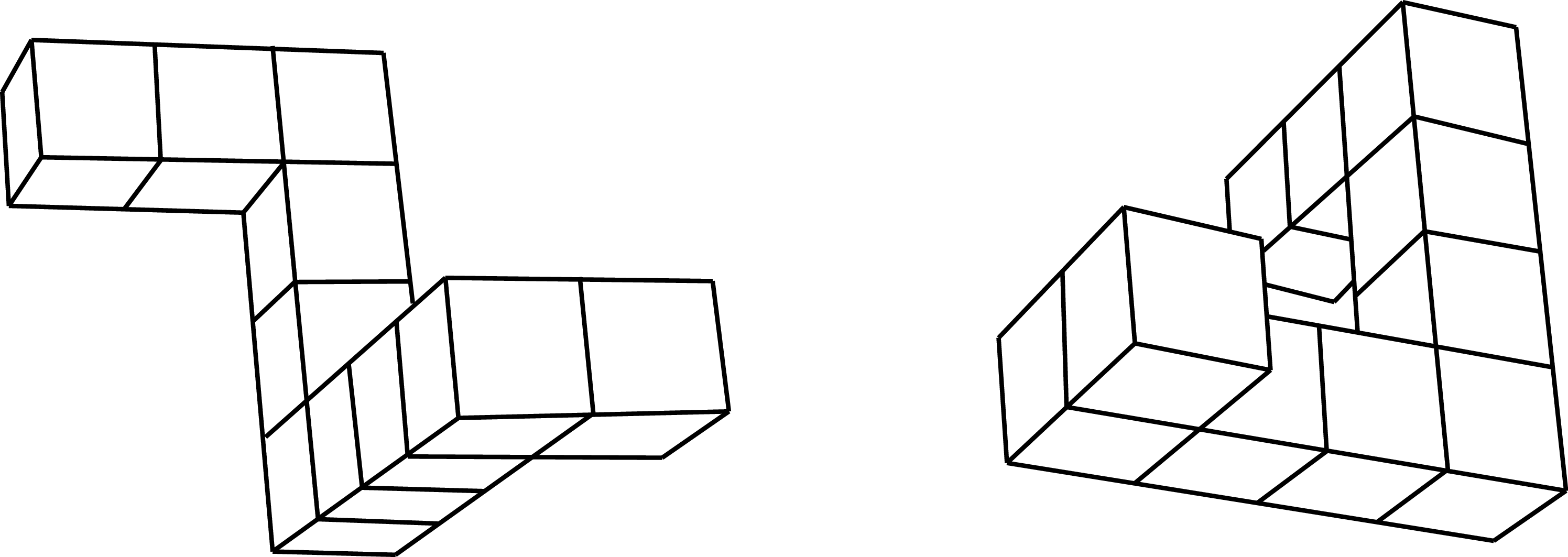
Michael Tarr and Steven Pinker [6] showed that similar results where obtained on a learning task. When observers learn to recognize a novel object from a single viewpoint they are able to generalize to new viewpoints but they do that at a cost: recognition time increases with the angle of rotation as if they had to mentally rotate the object in order to compare it with the view viewed during training. When trained with multiple viewpoints, participants recognized equally quickly all the familiar orientations.
The field of cognitive science has formulated a number hypothesis about the mechanisms used for recognizing objects: geometry based models, view-based templates, prototypes, and so on. Many of those hypothesis have been the inspiration for computer vision approaches for object recognition.
50.2.3 Principles of Categorization
When working on object recognition, one typical task is to train a classifier to classify images of objects into categories. A category represents a collection of equivalent objects. Categorization offers a number of advantages. As described in [7] “It is to the organism’s advantage not to differentiate one stimulus from others when that differentiation is irrelevant for the purposes at hand.” Eleanor Rosch and her collaborators proposed that categorization occurred at there different levels of abstraction: superordinate level, basic-level, and subordinate level. The following example, from [8], illustrates the three different levels of categorization:
| Superordinate | Basic Level | Subordinate |
|---|---|---|
| Furniture | Chair | Kitchen chair |
| Living-room chair | ||
| Table | Kitchen table | |
| Dining-room table | ||
| Lamp | Floor lamp | |
| Desk lamp | ||
| Tree | Oak | White oak |
| Red oak | ||
| Maple | Silver maple | |
| Sugar maple | ||
| Birch | River birch | |
| White birch |
Superordinate categories are very general and provide the a high degree of abstraction. Basic level categories correspond to the most common level of abstraction. The subordinate level of categorization is the most specific one. Two objects that belong to the same superordinate categories share fewer attributes than two objects that belong to the same subordinate category.
Object categorization into discrete classes has been a dominant approach in computer vision. One example is the ImageNet dataset that organizes object categories into the taxonomy provided by WordNet [9].
However, as argued by E. Rosch [8], “natural categories tend to be fuzzy at their boundaries and inconsistent in the status of their constituent members.” Rosch suggested that categories can be represented by prototypes. Prototypes are the clearest members of a category. Rosch hypothesized that humans recognize categories by measuring the similarity to prototypes. By using prototypes, Rosch [8] suggested that it is easier to work with continuous categories, as the categories are defined by the “clear cases rather than its boundaries.”
But object recognition is not as straightforward as a categorization task and using categories can result in a number of issues. One example is dealing with the different affordances that an object might have as a function of context. In language, a word or a sentence can have a standing meaning and an occasion meanings. An standing meaning corresponds to the conventional meaning of an expression. The occasion meaning is the particular meaning that the same expression might have when used in a specific context. Therefore, when an expression is being used, it has an occasion meaning that differs from its conventional meaning. The same thing happens with visual objects as illustrated in Figure 50.4.


Avoiding categorization all together has been also the focus on some computer vision approaches to image understanding like the Visual Memex by T. Malisiewicz and A. Efros [10].
We will now study a sequence of object recognition models with outputs of increasing descriptive power.
50.3 Image Classification
In Section 50.3 we will repeat material already presented in the book. Read this section as if it were written by Pierre Menard, from the short story by Jorges Luis Borges~. This character rewrote word for word, but the same words did not mean the same thing, because the context of the writing (who wrote it, why they wrote it, and when they wrote it) was entirely different.
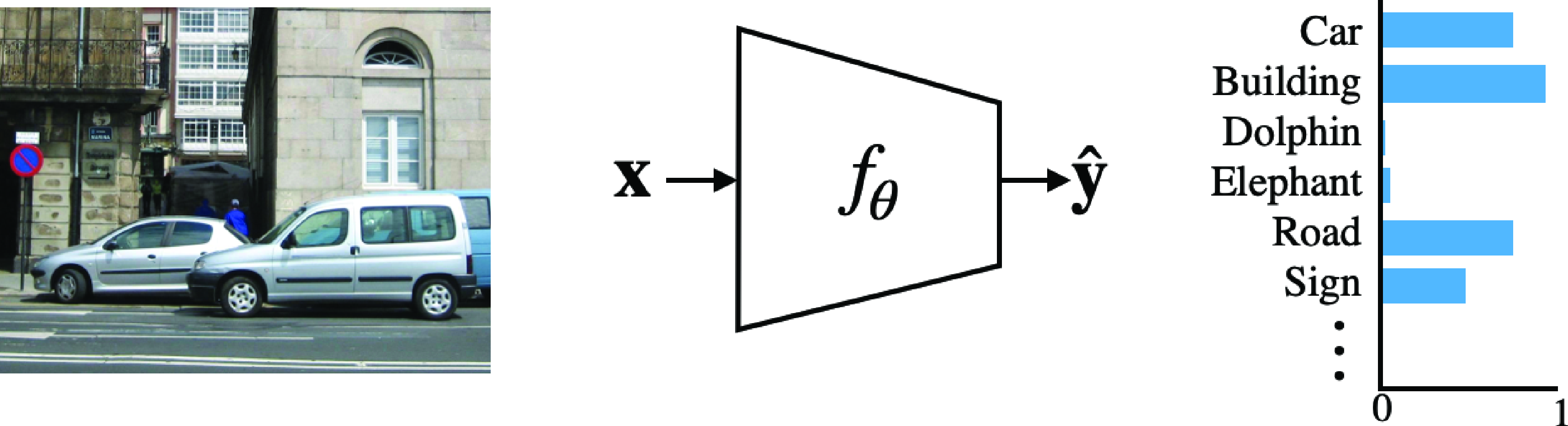
Image classification is one of the simplest tasks in object recognition. The goal is to answer the following, seemingly simple, question: Is object class \(c\) present anywhere in the image \({\bf x}\)? We also covered image classification as a case study of machine learning in section Section 9.7.3. Even though we will use the same words now, and even the same sentences, you should read them in a different way. The same words will mean something different. Before, we emphasized the problem of learning; now we are focusing on the problem of object understanding. So, when we say \(\mathbf{y} = f(\mathbf{x})\), before the focus of our attention was \(f\), now the focus is \(\mathbf{y}\).
Image classification typically assumes that there is a closed vocabulary of object classes with a finite number of predefined classes. If our vocabulary contains \(K\) classes, we can loop over the classes and ask the same question for each class. This task does not try to localize the object in the image, or to count how many instances of the object are present.
50.3.1 Formulation
We can answer the previous question in a mathematical form by building a function that maps the input image \({\bf x}\) into an output vector \(\hat {\bf y}\): \[\hat {\bf y} = f({\bf x})\] The output,\(\hat {\bf y}\), of the function will be a binary response: \(1=yes\), the object is present; and \(0=no\), the object is not present.

In general we want to classify an image according to multiple classes. We can do this by having as output a vector \(\hat {\bf y}\) of length \(K\), where \(K\) is the number of classes. Component \(c\) of the vector \(\hat {\bf y}\) will indicate whether class \(c\) is present or absent in the image. For instance, the training set will be composed of examples of images and the corresponding class indicator vectors as shown in Figure 50.6 (in this case, \(K=3\)).

We want to enrich the output so that it also represents the uncertainty in the presence of the object. This uncertainty can be the result of a function \(f_{\theta}\) that does not work very well, or from a noisy or blurry input image \(\mathbf{x}\) where the object is difficult to see. One can formulate this as a function \(f_{\theta}\) that takes as input the image \({\bf x}\) and outputs the probability of the presence of each of the \(K\) classes. Letting \(Y_c \in \{0,1\}\) be a binary random variable indicating the presence of class \(c\), we model uncertainty as, \[\begin{aligned} p(Y_c=1 \bigm | \mathbf{x}) &= \hat{y}_c \end{aligned} \tag{50.1}\]
50.3.1.1 Exclusive classes
One common assumption is that only one class, among the \(K\) possible classes, is present in the image. This is typical in settings where most of the images contain a single large object. Multiclass classification with exclusive classes results is given in the following constraint:
\[\sum_{c=1}^K \hat{y}_c=1 \tag{50.2}\]
where \(0>\hat{y}_c>1\). In the toy example with three classes shown previously, the valid solutions for \(\hat{\mathbf{y}}=[\hat{y}_1, \hat{y}_2, \hat{y}_3]^\mathsf{T}\) are constrained to lie within a simplex.
Simplex with three exclusive classes:
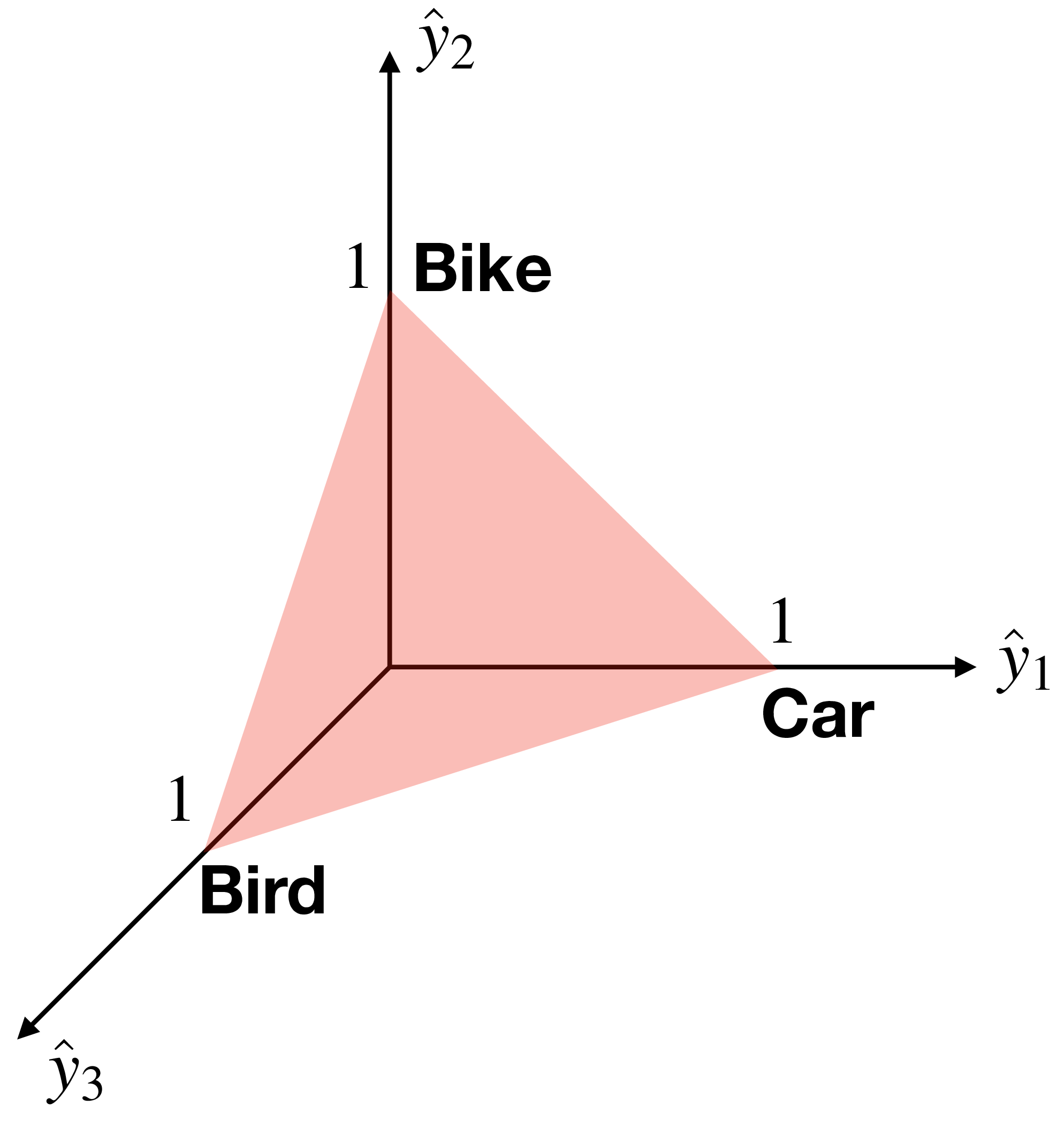
Under this formulation, the function \(f\) is a mapping \(f:\mathbb{R}^{N \times M \times 3} \rightarrow \vartriangle^{K-1}\) from the set of red-green-blue (RGB) images to the \((K-1)\)-dimensional simplex, \(\vartriangle^{K-1}\).
The function \(f\) is constrained to belong to a family of possible functions. For instance, \(f\) might belong to the space of all the functions that can be built with a neural network. In such a case the function is specified by the network parameters \(\theta: f_\theta\). When using a neural net, the vector \(\hat{\mathbf{y}}\) is usually computed as the output of a softmax layer.
This yields the softmax regression model we saw previously in section Section 9.7.3. Given the constraint of Equation 50.2, the output of \(f_{\theta}\) can be interpreted as a probability mass function over \(K\) classes:
\[\begin{aligned} p_{\theta}(Y \bigm | \mathbf{x}) &= \hat{\mathbf{y}} = f_{\theta}(\mathbf{x}) \end{aligned}\]
where \(Y\) is the random variable indicating the single class per image. This relates to our previous model in Equation 50.1 as: \[\begin{aligned} p(Y_c=1 \bigm | \mathbf{x}) &= p_{\theta}(Y=c \bigm | \mathbf{x}) \end{aligned}\]
50.3.1.2 Multilabel classification
When the image can have multiple labels simultaneously, the classification problem can be formulated as \(K\) binary classification problems (where \(K\) is the number of classes).
In such a case, the function \(f_\theta\) can be a neural network shared across all classes (Figure 50.7), and the output vector \(\hat{\mathbf{y}}\), of length \(K\), is computed using a sigmoid nonlinearity for each output class. In this case the output can still be interpreted as the probability \(\hat{y}_c = p_\theta(Y_c=1 \bigm | \mathbf{x})\), but without the constraint that the sum across classes is 1.
50.3.2 Classification Loss
In order to learn the model parameters, we need to define a loss function that will capture the task that we want to solve. One natural measure of classification error is the missclassication error. The errors that the function \(f\) makes are the number of misplaced ones (i.e., the misclassification error) over the dataset, which we can write as:
\[\begin{aligned} \mathcal{L}(\hat{\mathbf{y}},\mathbf{y}) = \sum_{t=1}^T \sum_{c=1}^{K} \mathbb{1}(\hat{y}^{(t)}_c \neq y^{(t)}_c ). \end{aligned}\] where \(T\) is the number of images in the dataset.
However, it is hard to learn the function parameters using gradient descent with this loss as it is not differentiable. Finding the optimal parameters of function \(f_\theta\) requires defining a loss function that we will be tractable to optimize during the training stage.
50.3.2.1 Exclusive classes
If we interpret the function \(f\) as estimating the probability \(p(Y_c=1 \bigm | {\bf x}) = \hat{y}_c\), with \(\sum_c \hat{y}_c =1\). The likelihood of the ground truth data is: \[ \prod_{t=1}^T \prod_{c=1}^K \left( \hat{y}^{(t)}_c \right) ^{y^{(t)}_c} \tag{50.3}\]
where \(y^{(t)}_c\) is the ground truth value of \(Y_c\) for image \(t\), and the first product loops over all \(T\) training examples while the second product loops over all the classes \(K\). We want to find the parameters \(\theta\) that maximize the likelihood of the ground truth labels for whole training image. As we have seen in chapter Chapter 24, maximizing the likelihood corresponds to minimizing the cross-entropy loss (which we get by just taking the negative log of the equation Equation 50.3, resulting in a total classification loss:
\[ \mathcal{L}_{cls}(\hat{\mathbf{y}},\mathbf{y}) = -\sum_{t=1}^{T} \sum_{c=1}^{K} y^{(t)}_c \log(\hat{y}^{(t)}_c) \]
The cross-entropy loss is differentiable and it is commonly used in image classification tasks.
50.3.2.2 Multilabel classification
If classes are not exclusive, the likelihood of the ground truth data is: \[\prod_{t=1}^T \prod_{c=1}^K \left( \hat{y}^{(t)}_c \right) ^{y^{(t)}_c} \left( 1-\hat{y}^{(t)}_c \right) ^{1-y^{(t)}_c}\] where the outputs \(\hat{y}_c\) are computed using a sigmoid layer. Taking the negative log of the likelihood gives the multiclass binary cross-entropy loss:
\[\mathcal{L}_{cls}(\hat{\mathbf{y}},\mathbf{y}) = -\sum_{t=1}^{T} \sum_{c=1}^{K} y^{(t)}_c \log(\hat{y}^{(t)}_c) + (1-y^{(t)}_c) \log(1-\hat{y}^{(t)}_c)\]
50.3.3 Evaluation
Once the function \(f_\theta\) has been trained, we have to evaluate its performance over a holdout test set. There are several popular measures of performance.
Classification performance uses the output of the classifier, \(f\), as a continuous value, the score \(\hat{y}_c\), for each class. We can rank the predicted classes according to that value. The top-1 performance measures the percentage of times that the true class-label matches the highest scored prediction, \(\hat{y} = \underset{c}{\mathrm{argmax}} ( \hat{y}_c )\), in the test set:
\[\text{TOP-1} = \frac{100}{T} \sum_{t=1}^T \mathbb{1}( \hat{y}^{(t)} = y^{(t)}) \]
where \(y^{(t)}\) is the ground truth class of image \(t\). This evaluation metric only works for the exclusive class case since we assume a single ground truth class per image. For the multilabel case, we may instead check if each label’s is predicted correctly.
In some benchmarks (such as ImageNet), researchers also measure the top-5 performance, which is the percentage of times that the true label is within the set of five highest scoring predictions. Top-5 is useful in settings where the labels might be ambiguous, or where multiple labels for one image might be possible. In the case of multiple labels, ideally, the test set should specify which labels are possible and evaluate only using those. The top-5 measure is less precise and it is used when the test set only contains one label despite that multiple labels might be correct.
For multiclass prediction problems it is often useful to look at what is the structure of mistakes made by the model. The confusion matrix summarizes both the overall performance of the classifier and also the percentage of times that two classes are confused by the classifier. For instance, the following matrix shows the evaluation of a three-way classifier. The diagonal elements are the same as the top-1 performance for each class. The off-diagonal elements show the confusions. In this case, it seems that the classifier confuses cats as dogs the most.
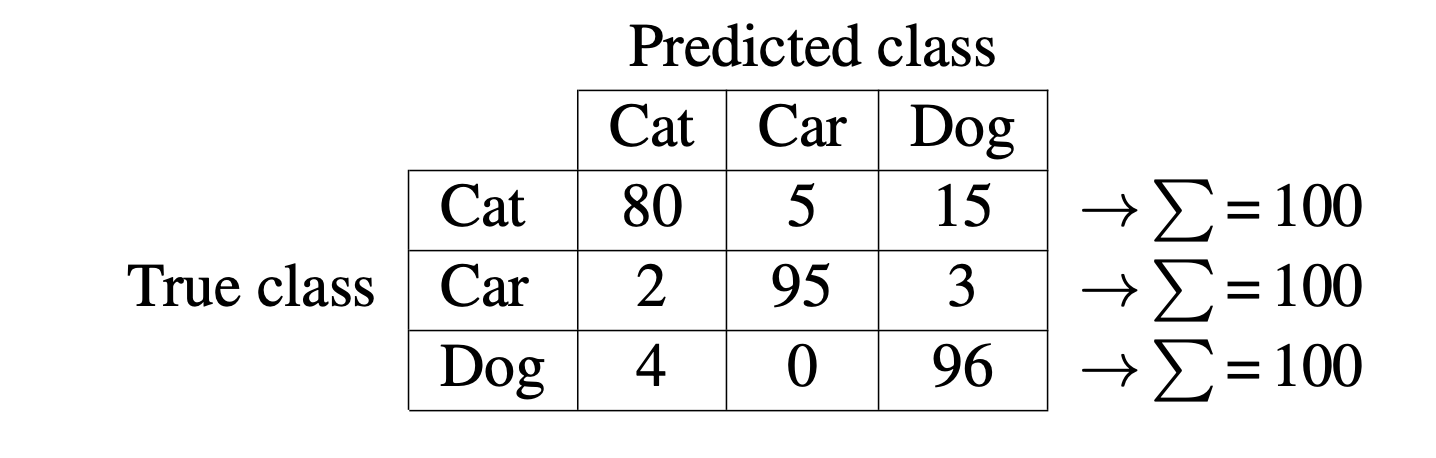
The elements of the confusion matrix are:
\[C_{i,j} = 100 \frac{ \sum_{i=1}^N \mathbb{1}( \hat{y}^{(t)} = j) \mathbb{1} (y^{(t)} = i) }{ \sum_{i=1}^N \mathbb{1}(y^{(t)} = i) } \] where \(C_{i,j}\) measures the percentage of times that true class \(i\) is classified as class \(j\).
In this toy example ( Table 50.1), we can see that 80 percent of the cat images are correctly classified, while 5 percent of cat images are classified as car images, and 15 percent are classified as pictures of dogs.
50.3.4 Shortcomings
The task of image classification is plagued with issues. Although it is a useful task to measure progress in computer vision and machine learning, one has to be aware of its limitations when trying to use it to produce a meaningful description of a scene, or when developing a classifier for consumption in the real world.
One very important shortcoming of this task is that it assumes that we can actually answer unambiguously the question does the image contains object c? But what happens if class definitions are ambiguous or class boundaries are soft? Even in cases were we believe that the boundaries might be well defined, it is east to find images that will challenge our assumption, as shown in Figure 50.8.






Which of this images of Figure 50.8 contains a car? A simple question that does not have a simple answer. The top three images contain cars, although with increasing difficulty. However, for the three images on the second row, it is not clear what the desired answer it is. We can clearly recognize the content of those images, but it feels as if using a single word for describing those images leaves too much ambiguity. Is a car under construction already a car? Is the toy car a car? And if we play with food and make a car out of watermelon, would that be a car? Probably not. But if a vision system classifies that shape as a car, would that be a mistake like any other?
Although it is not clearly stated in the problem definition, language plays a big role in object classification. The objects in Figure 50.9 are easily recognizable to us, but if we ask the question "Is there a fruit in this picture?," the answer is a bit more complex than it might appear at first glance.

What if the object is present in the scene but invisible in the image? What if there are infinite classes? In our formulation, \(\hat {\bf y}\) is a vector of a fixed length. Therefore, we can only answer the question “is object class \(c\) present in the image?” for a finite set of classes. What if we want to be able to answer an infinite set of questions? The next sections introduce more sophisticated formulations of object recognition that address some of these questions.
Is it possible to classify an image without localizing the object? How can we answer the question “Is object class \(c\) present in the image?” without localizing the object? One possibility is that the function \(f\) has learned to localize the object internally, but the information about the location is not being recorded in the output. Another possibility is that the function has learned to use other cues present in the image (biases in the dataset). As it is not trying to localize an object, the function \(f\) will not get penalized if it uses shortcuts such as only recognizing one part of the object (e.g., such as the head of a dog, or car wheels), or if it makes use of contextual biases in the dataset (e.g., all images with grass and blue skies have horses, or all streets have cars) or detects unintended correlations between low-level image properties and the image content (e.g., all images of insects have a blurry background). As a consequence, image classification performance could mislead us into believing that the classifier works well and that it has learned a good representation of the object class it classifies.
50.4 Object Localization
For many applications, saying that an object is present in the image is not enough. Suppose that you are building a visual system for an autonomous vehicle. If the visual system only tells the navigation system that there is a person in the image it will be insufficient for deciding what to do. Object localization consists of localizing where the object is in the image. There are many ways one can specify where the object is. The most traditional way of representing the object location is using a bounding box (Figure 50.10), that is, finding the image-coordinates of a tight box around each of the instances of class \(c\) in the image \(\bf x\).
50.4.1 Formulation
How you look at an object does not change the object itself (whether you see it or feel it, etc.). This induces translation and scale invariance. Let’s build a system that has this property.
We will formulate object detection as a function that maps the input image \({\bf x}\) into a list of bounding boxes \(\hat {\bf b}_i\) and the associated classes to each bounding box encoded by a vector \(\hat {\bf y}_i\), as illustrated in Figure 50.10.

The class vector, \(\hat {\bf y}_i\), has the same structure as in the image classification task but now it is applied to describe each bounding box. Bounding boxes are usually represented as a vector of length 4 using the coordinates of the two corners, \({\bf b} = \left[ x_1, y_1, x_2, y_2 \right]\), or with the center coordinates, width, and height, \({\bf b} = \left[ x_c, y_c, w, h \right]\). Our goal is a function \(f\) that outputs a set of bounding boxes, \(\mathbf{b}\), and their classes \(\mathbf{y}\): \[\{\hat {\bf y}_i, \hat {\bf b}_i\} = f({\bf x})\]
Most approaches for object detection have three main steps. In the first step, a set of candidate bounding boxes are proposed. In the second step, we loop over all proposed bounding boxes, and for each one, we apply an classifier the image patch inside the bounding box. In the third and final step, the selected bounding boxes are postprocessed to remove any redundant detections.
50.4.1.1 Window scanning approach
In its simplest form, the problem of object localization is posed as a binary classification task, namely distinguishing between a single object class and background class. Such a classification task can be turned into a detector by sliding it across the image (or image pyramid), and classifying each local window as shown in Algorithm 50.1.

The window scanning algorithm is the following:

In this approach, location and translation invariance are achieved by the bounding box proposal mechanism. We can add another invariance, such as rotation invariance, by proposing rotated bounding boxes.
50.4.1.2 Selective search
The window scanning approach can be slow as the same classifier needs to be applied to tens of thousands of image patches. Selective search makes the process more efficient by proposing an initial set of bounding boxes that are good candidates to contain an object (Figure 50.13). This proposal mechanism is performed by a selection mechanism simpler than the object classifier. This approach was motivated by the strategy used by the visual system in which attention is first directed toward image regions likely to contain the target [11], [12], [13]. This first attentional mechanism is very fast but might be wrong. Therefore, a second, more accurate but also more expensive, processing stage is required in order to take a reliable decision. The advantage of this cascade of decisions is that the most expensive classifier is only applied to a sparse set of locations (the ones selected by the cheap attentional mechanism) dramatically reducing the overall computational cost.
The algorithm for selective search only differs from the window scanning approach on how the list of candidate bounding boxes is generated. Some approaches also add a bounding box refinement step. The overall approach is described in algorithm Figure 50.12.

This algorithm has four main steps. In the first step, the algorithm uses an efficient window scanning approach to produce a set of candidate bounding boxes. In the second step, we loop over all the candidate bounding boxes, we crop out the box and resize it to a canonical size, and then we apply an object classifier to classify the cropped image as containing the object we are looking for or not. In the third step, we refine the bounding box for the crops that are classified as containing the object. And finally, in the fourth step, we remove low-scoring boxes and we use nonmaximum suppression (NMS) to discard overlapping detections likely to correspond to the same object, so as to output only one bounding box for each instance present in the image.
The nonmaximum suppression algorithm takes as input a set of object bounding boxes and confidences, \(S=\{\hat{\mathbf{b}}_i, \hat{\mathbf{y}}_i\}_{i=1}^B\), and outputs a smaller set removing overlapping bounding boxes. It is an iterative algorithm as follows: (1) Take the highest confidence bounding box from the set \(S\) and add it to the final set \(S^*\). (2) Remove from \(S\) the selected bounding box and all the bounding boxes with an IoU larger than a threshold. (3) Go to step 1 until \(S\) is empty.
Each step can be implemented in several different ways, giving rise to different approaches. The whole pipeline is summarized in Figure 50.13.

Bounding box proposal (represented as \(f_0\) in Figure 50.14) can be implemented in several ways (e.g., using image segmentation [14], a neural network [15], or a window scanning approach with a low-cost classifier). The classification and bounding box refinement, \(f_1\), can be implemented by a classifier and a regression function.
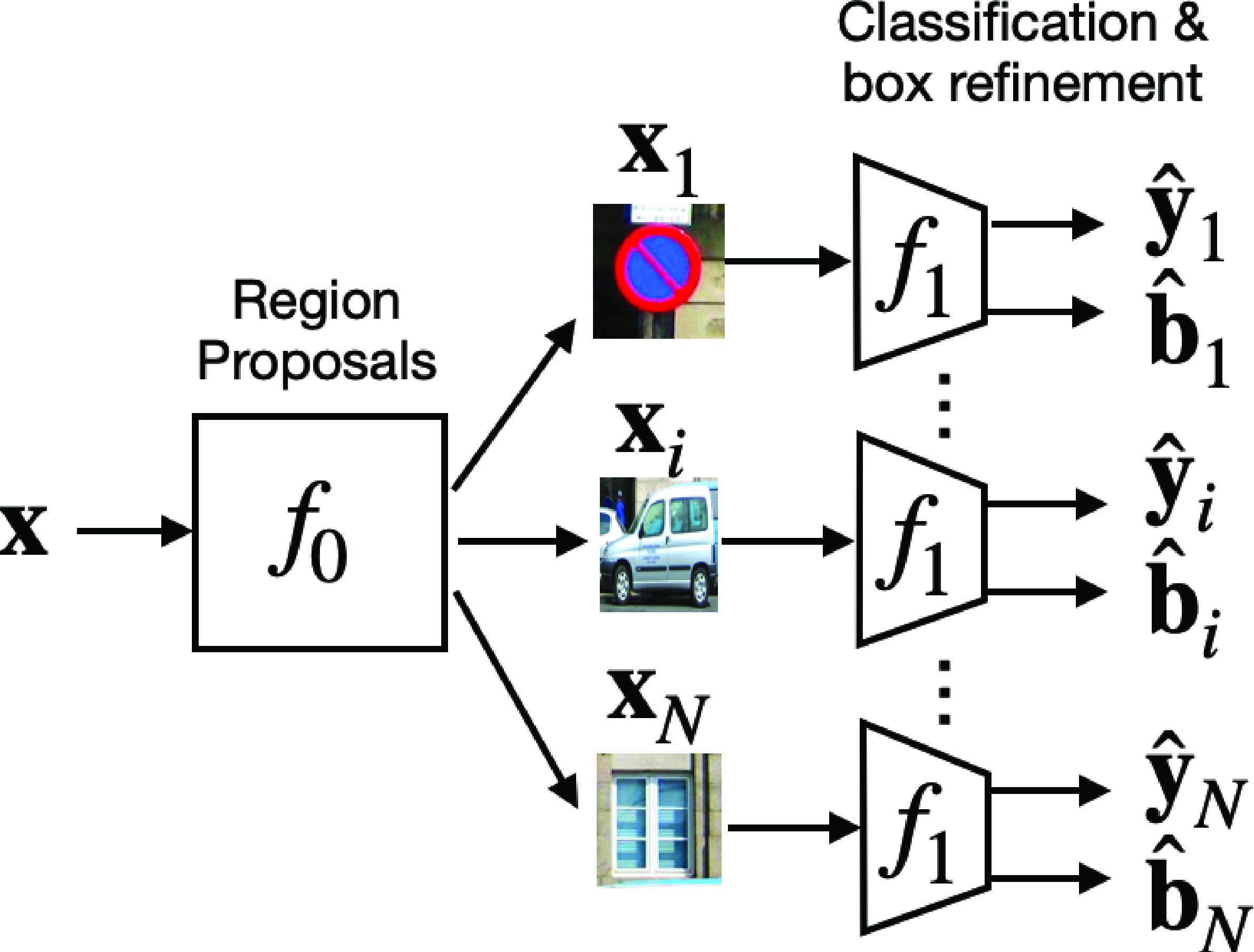
50.4.1.3 Cascade of classifiers
Trying to localize an object in an image is like finding a needle in a haystack: the object is usually small and might be surrounded by a complex background. Selective search reduced the complexity of the search by dividing the search in two steps: a first, fast, and cheap classification function that detects good candidate locations; and a second, slow, and expensive classification function capable of accurately classifying the object and that only needs to be applied in a subset of all possible locations and scales. Cascade of classifiers pushes this idea to the limit by dividing the search in a sequence of classifiers of increasing computational complexity and accuracy.
The algorithm for the cascade of classifiers is:

Cascades of classifiers became popular in computer vision when Paul Viola and Michael Jones [16] introduced it in 2001 with a ground-breaking real-time face detector based on a cascade of boosted classifiers. In parallel, Fleuret and Geman [17] also proposed a system that performs a sequence of binary tests at each location. Each binary test checks for the presence of a particular image feature. Early versions of this strategy were also inspired by the game “Twenty Questions” [18].
In a cascade, computational power is allocated into the image regions that are more likely to contain the target object while regions that are flat or contain few features are rejected quickly and almost no computations are allocated in them. The following figure, from [17], shows a beautiful illustration of how a cascaded classifier allocates computing power in the image when trained to detect faces. The intensity shown in the heat map is proportional to the number of levels in the cascade applied to each location.
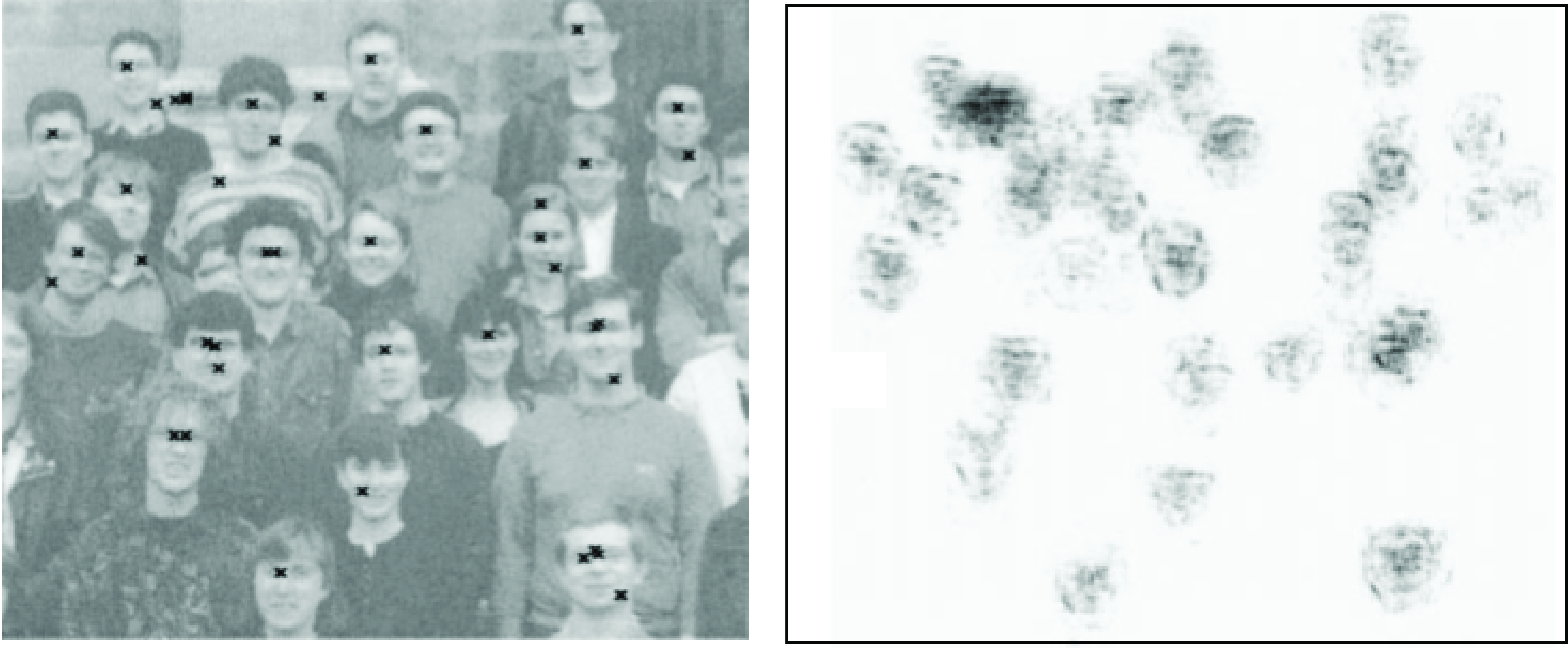
It is interesting to point out that the scanning window approach (\(Levels = 1\)) and the selective search procedure (\(Levels = 2\)) are special cases of this algorithm. The cascade of classifiers usually does not have a bounding box refinement stage as it already started with a full list of all bounding boxes, but it could be added if we wanted to add new transformations not available in the initial set (e.g., rotations).
50.4.1.4 Other approaches
Object localization is an active area of research and there are a number of different formulations that share some elements with the approaches we shared previously. One example is YOLO [19], which makes predictions by looking at the image globally. It is not as accurate as some of the scanning methods but it can be computationally more efficient. There are many other approaches that we will not summarize here as the list will be obsolete shortly. Instead, we will continue focusing on general concepts that should help the reader understand other approaches.
50.4.2 Object Localization Loss
The object localization loss has to take into account two complementary tasks: classification and localization.
Classification loss (\(\mathcal{L}_{\text{cls}}\)): For each detected bounding box, does the predicted label matches the ground truth at that location?
Localization loss (\(\mathcal{L}_{\text{loc}}\)): How close is the detected location to the ground truth object location?
For each image, the output of our object detector is a set of bounding boxes \(\{\hat{\mathbf{b}}_i, \hat{\mathbf{y}}_i\}_{i=1}^B\), where \(B\) is likely to be larger than the number of ground truth bounding boxes in the training set. The first step in the evaluation is to associate each detection with a ground truth label so that we have a set \(\{\mathbf{b}_i, \mathbf{y}_i\}_{i=1}^B\). For each of the predicted bounding boxes that overlaps with the ground truth instances, we want to optimize the system parameters to improve the predicted locations and labels. The remaining predicted bounding boxes that do not overlap with ground truth instances are assigned to the background class, \(\mathbf{y}_i=0\). For those bounding boxes, we want to optimize the model parameters in order to reduce their predicted class score, \(\hat{\mathbf{y}}_i\). This process is illustrated in the following figure. The detector produces a set of bounding boxes for candidate car locations. Those are compared with the ground truth data. Each detected bounding box is assigned one ground truth label (indicated by the color) or assigned to the background class (indicated in white). Note that several detections can be assigned to the same ground truth bounding box.

Now that we have assigned detections to ground truth annotations, we can compare them to measure the loss. For the classification loss, as each bounding box can only have one class, we can use the cross-entropy loss:
\[\mathcal{L}_{\text{cls}}(\hat{\mathbf{y}}_i, \mathbf{y}_i) = - \sum_{c=1}^{K} y_{c,i} \log(\hat{y}_{c,i}) \] where \(K\) is the number of classes.
Let’s now focus on the second part; how do we measure the localization loss \(\mathcal{L}_{\text{loc}} (\hat{\mathbf{b}}_i, \mathbf{b}_i)\)? One typical measure of similarity between two bounding boxes is the Intersection over Union (IoU) as shown in the following drawing:
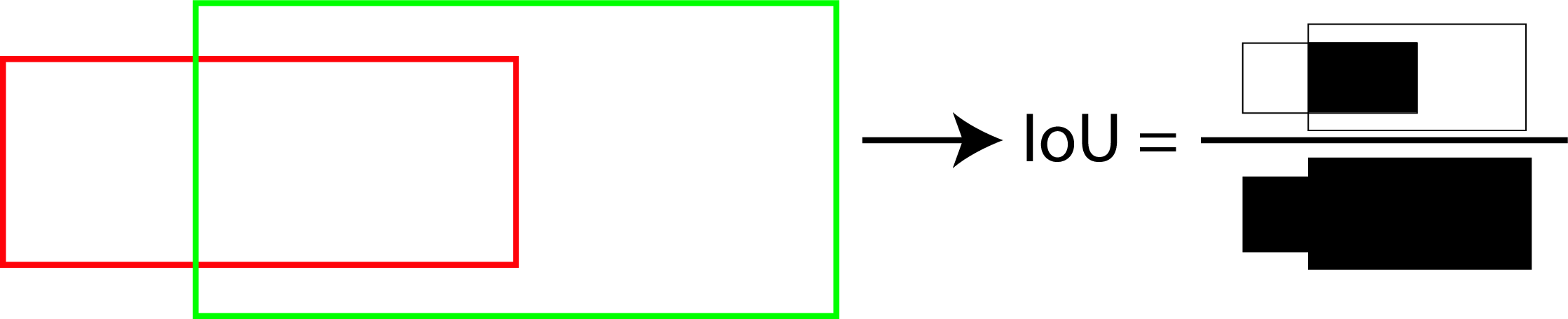
The IoU is a quantity between 0 and 1, with 0 meaning no overlap and 1 meaning that both bounding boxes are identical. As the IoU is a similarity measure, the loss is defined as: \[\mathcal{L}_{\text{loc}} (\hat{\mathbf{b}}, \mathbf{b})= 1-IoU (\hat{\mathbf{b}}, \mathbf{b}).\] The IoU is translation and scale invariant, and it is frequently used to evaluate object detectors. A simpler loss to optimize is the L2 regression loss: \[\mathcal{L}_{\text{loc}} (\hat{\mathbf{b}}, \mathbf{b}) = (\hat{x}_1 - x_1)^2 + (\hat{x}_2 - x_2)^2 + (\hat{y}_1 - y_1)^2 + (\hat{y}_2 - y_2)^2\] The L2 regression loss is translation invariant, but it is not scale invariant. The L2 loss is larger for big bounding boxes. The next graph (Figure 50.18) compares the IoU loss, and the L2 regression loss for two square bounding boxes, with an area equal to 1, as a function of the relative \(x\)-displacement.
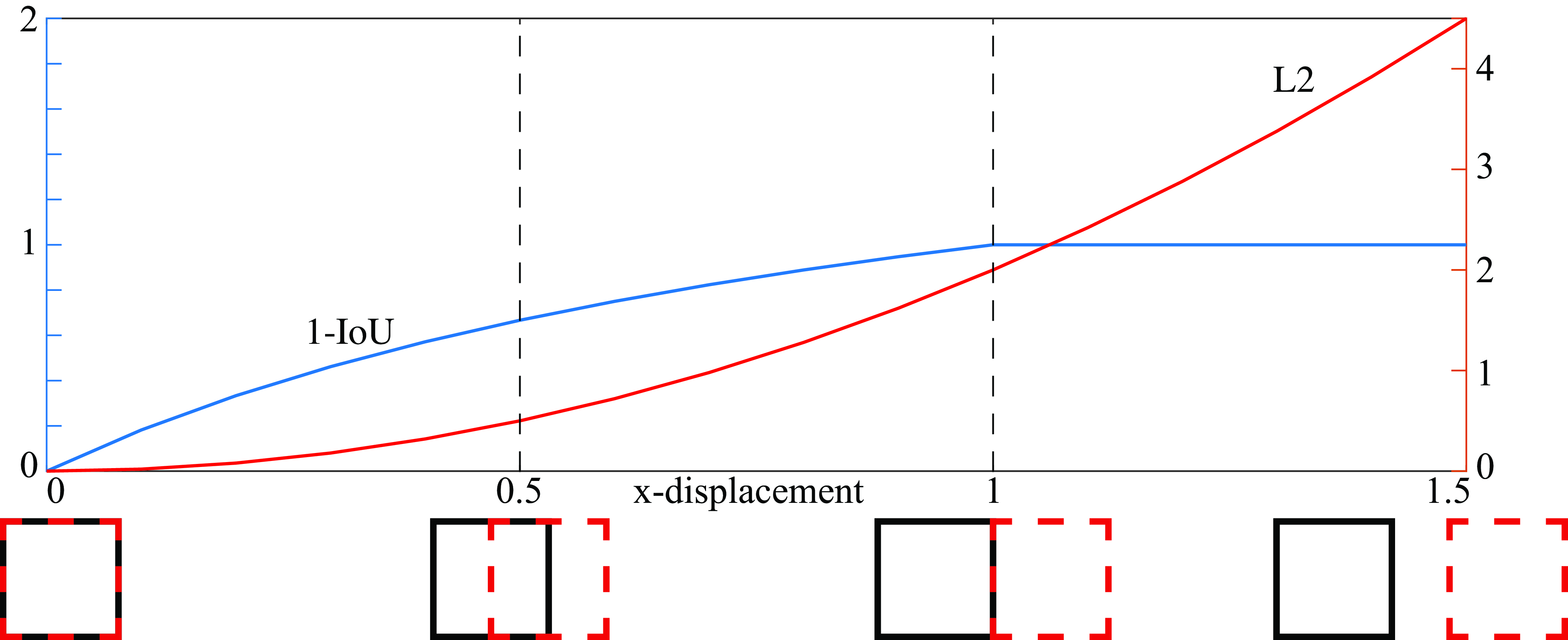
The IoU loss becomes 1 when the two bounding boxes do not overlap, which means that there will be no gradient information when running backpropagation.
Now we can put together the classification and the localization loss to compute the overall loss:
\[ \mathcal{L}( \{\hat{\mathbf{b}}_i, \hat{\mathbf{y}}_i\}, \{\mathbf{b}_i, \mathbf{y}_i\}) = \mathcal{L}_{\text{cls}}(\hat{\mathbf{y}}_i, \mathbf{y}_i) + \lambda \mathbb{1} (\mathbf{y}_i \neq 0) \mathcal{L}_{\text{loc}} (\hat{\mathbf{b}}_i, \mathbf{b}_i) \] where the indicator function \(\mathbb{1} (\mathbf{y}_i \neq 0)\) sets to zero the location loss for the bounding boxes that do not overlap with any of the ground truth bounding boxes. The parameter \(\lambda\) can be used to balance the relative strength of both losses. This loss makes it possible to train the whole detection algorithm end-to-end. It is possible to train the localization and the classification stages independently and some approaches follow that strategy.
50.4.3 Evaluation
There are several ways of evaluating object localization approaches. The most common approach is measuring the average precision-recall.
Just as we did when defining the localization loss, we need to assign detection outputs to ground truth labels. We can do this in several ways, and they can result in different measures of performance. The methodology introduced in the PASCAL challenge used the following procedure.
Assign detections to ground truth labels: For each image, sort all the detections by their score, \(\hat{\mathbf{y}}_i\). Then, loop over the sorted list in decreasing order. For each bounding box, compute the IoU with all the ground truth bounding boxes. Select the ground truth bounding box with the highest IoU. If the IoU is larger than a predefined threshold, (a typical value is 0.5) mark the detection as correct and remove the ground truth bounding box from the list to avoid double counting the same object. If the IoU is below the threshold, mark the detection as incorrect and do not remove the ground truth label. Repeat this operation until there are no more detections to evaluate. Mark remaining ground-truth bounding boxes as missed detections.
Precision-recall curve measures the performance of the detection as a function of the decision threshold. As each bounding box comes with a confidence score \(\hat{\mathbf{y}}_i\), we need to use a threshold, \(\beta\), to decide if an object is present at the bounding box location \(\hat{\mathbf{b}}_i\) or not. Given a threshold \(\beta\), the number of detections is \(\sum_i \mathbb{1} (\hat{\mathbf{y}}_i > \beta)\) and the number of correct detections is \(\sum_i \mathbb{1} (\hat{\mathbf{y}}_i > \beta) \times \mathbf{y}_i\). From these two quantities we compute the precision as the percentage of correct detections:
\[ Precision(\beta) = \frac{\sum_i \mathbb{1} (\hat{\mathbf{y}}_i > \beta) \times \mathbf{y}_i} {\sum_i \mathbb{1} (\hat{\mathbf{y}}_i > \beta)} \]
The precision only gives a partial view on the detector performance as it does not account for the number of ground truth instances that are not detected (misdetections). The recall measures the proportion of ground truth instances that are detected for a given decision threshold \(\beta\):
\[Recall (\beta) = \frac{\sum_i \mathbb{1} (\hat{\mathbf{y}}_i > \beta) \times \mathbf{y}_i} {\sum_i \mathbf{y}_i}\]
Both, the precision and recall, are quantities between 0 and 1. High values of precision and recall correspond to high performance. The next graph (Figure 50.19) shows the precision-recall curve as a function of \(\beta\) (decision threshold).
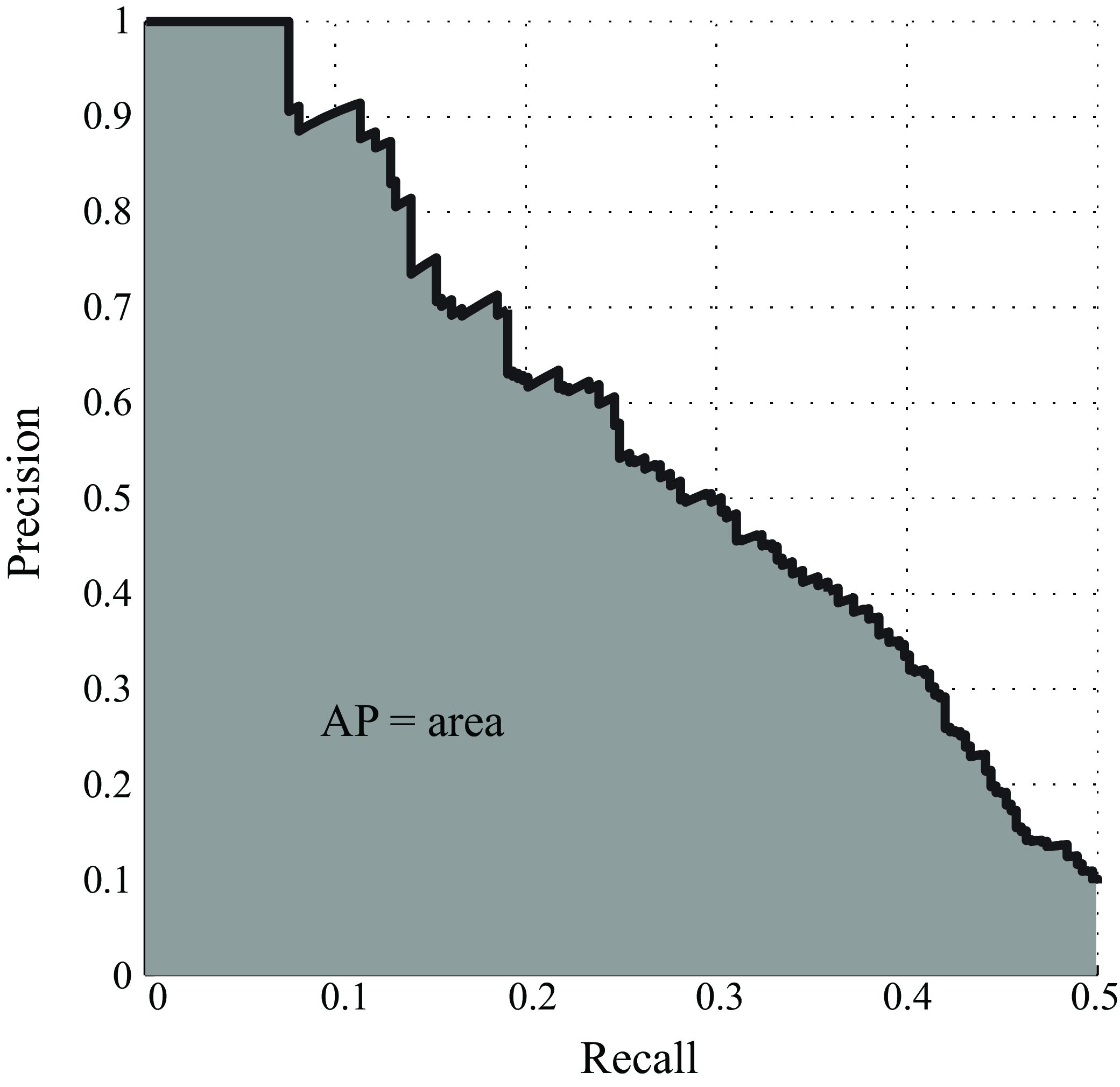
The precision-recall curve is non-monotonic. The average precision (AP) summarizes the entire curve with one number. The AP is the area under the precision-recall curve, and it is a number between 0 and 1.
50.4.4 Shortcomings
Bounding boxes can be very powerful in many applications. For instance, digital cameras detect faces and use bounding boxes to encode their location. The camera uses the pixels inside the bounding box to automatically set the focus and exposure time.
But using bounding boxes to represent the location objects will not be appropriate for objects with long and thin structures or for regions that do not have well-defined boundaries (Figure 50.20). It is useful to differentiate between stuff and objects. Stuff refers to things that do not have well-defined boundaries such as grass, water, and sky (we already discussed this in chapter Chapter 28). But the distinction between stuff and objects is not very sharp. In some images, object instances might be easy to separate like the two trees in the left image below, or become a texture where instances cannot be detected individually (as shown in the right image). In cases with lots of instances, bounding boxes might not appropriate and it is better to represent the region as “trees” than to try to detect each instance.

Even when there are few instances, bounding boxes can provide an ambiguous localization when two objects overlap because it might not be clear which pixels belong to each object.
Bounding boxes are also an insufficient object description if the task is robot manipulation. A robot will need a more detailed description of the pose and shape of an object to interact with it.
Let’s face it, localizing objects with bounding boxes does not address most of the shortcomings present in the image classification formulation. In fact, it adds a few more.
50.5 Class Segmentation
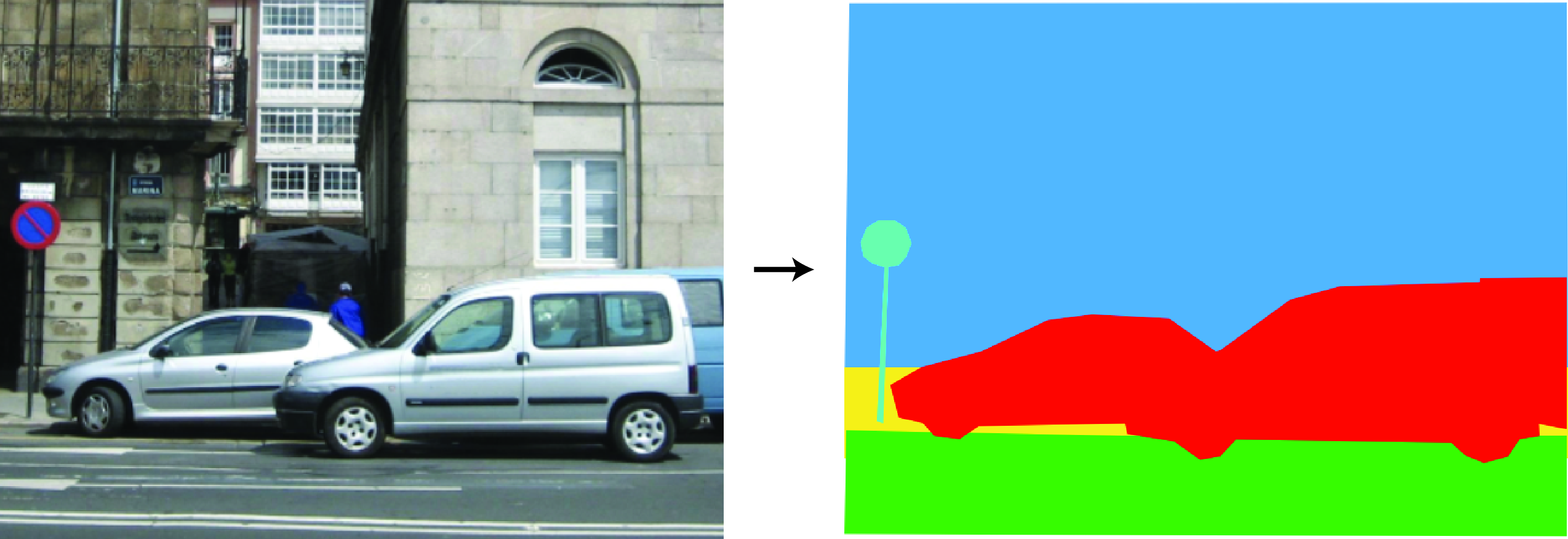
An object is something localized in space. There are other things that are not localized such as fog, light, and so on. Not everything is well-described by a bounding box (stuff, wiry objects, etc.). Instead we can try to classify each pixel in an image with an object class. Per-pixel classification of object labels, illustrated in Figure 50.21, is referred to as semantic segmentation.
In the most generic formulation, semantic segmentation takes an image as input, \(\mathbf{x}(n,m)\), and it outputs a classification vector at each location \(\mathbf{y}(n,m)\): \[\hat{\mathbf{y}} \left[n,m \right] = f(\mathbf{x} \left[n,m \right])\]
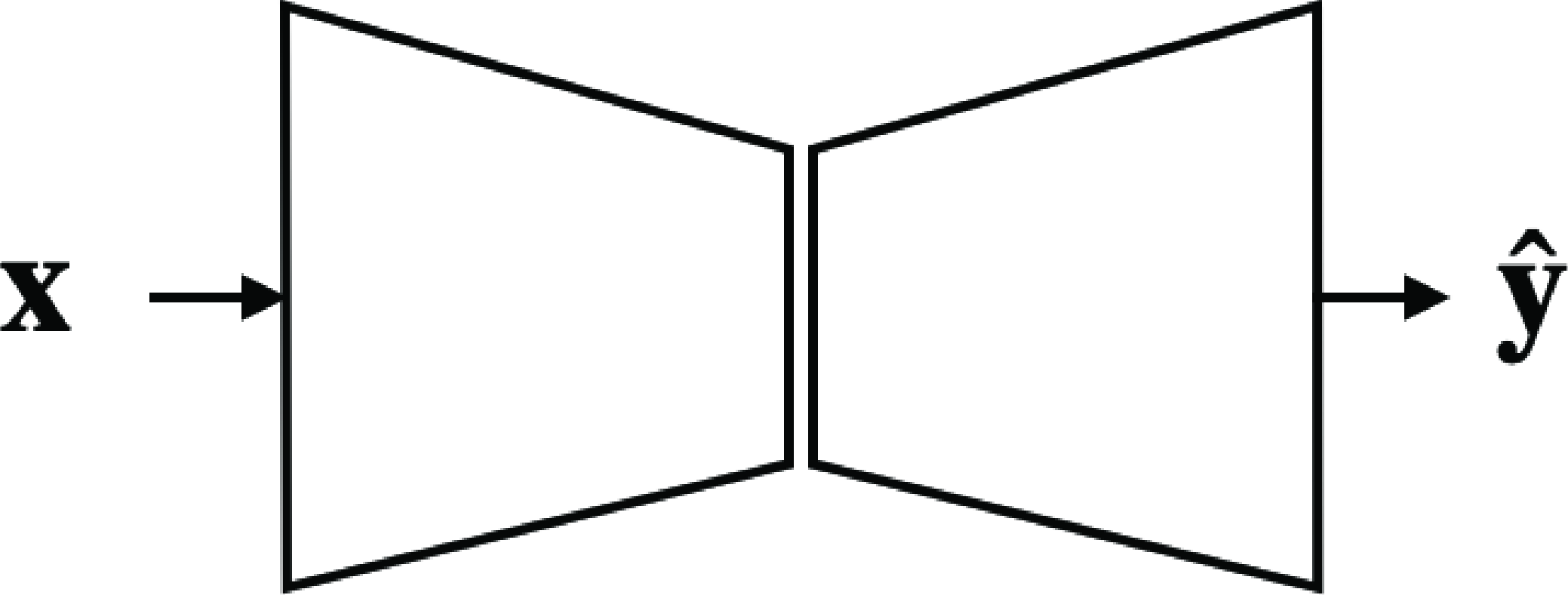
There are many ways in which such a function can be implemented. Generally the function \(f\) is a neural network with an encoder-decoder structure (Figure 50.22), first introduced in [20].
Another formulation consists of implementing a window-scanning approach where the function \(f\) scans the image and takes as input an image patch and it outputs the class of the central pixel of each patch. This is like a convolutional extension of the image classifier that we discussed in Section 50.3 and several architectures are variations over this same theme.
Training this function requires access to a dataset of segmented images. Each image in the training set will be associated with a ground truth segmentation, \(y^{(t)}_c \left[n,m \right]\) for each class \(c\). The multiclass semantic segmentation loss is the cross-entropy loss applied to each pixel:
\[\mathcal{L}_{seg}(\hat{\mathbf{y}},\mathbf{y}) = -\sum_{t=1}^{T} \sum_{c=1}^{K} \sum_{n,m} y^{(t)}_c \left[n,m \right] \log(\hat{y}^{(t)}_c \left[n,m \right])\] where the sum is over all the training examples, all classes, and all pixel locations.
This loss might focus too much on the large objects and ignore small objects. Therefore, it is useful to add a weight to each class that normalizes each class according to its average area in the training set.
In order to evaluate the quality of the segmentation, we can measure the percentage of correctly labeled pixels. However, this measure will be dominated by the large objects (sky, road, etc.). A more informative measure is the average IoU across classes. The IoU is a measure that is invariant to scale and will provide a better characterization of the overall segmentation quality across all classes.
50.5.1 Shortcomings
In this representation we have lost something that we had with the bounding boxes: this representation cannot count instances. The semantic segmentation representation, as formulated in this section, cannot separate two instances of the same class that are in contact; these will appear as a single segment with the same label.
Another important limitation is that each pixel is labeled as belonging to a single class. This means it cannot deal with transparencies. In such a cases, we would like to be able to provide multiple labels to each pixel and also provide a sense of depth ordering.
50.6 Instance Segmentation
We can combine the ideas of object detection and semantic segmentation into the problem of instance segmentation. Here the idea is to output a set of localized objects, but rather than representing them as bounding boxes we represent them as pixel-level masks as shown in Figure 50.23.
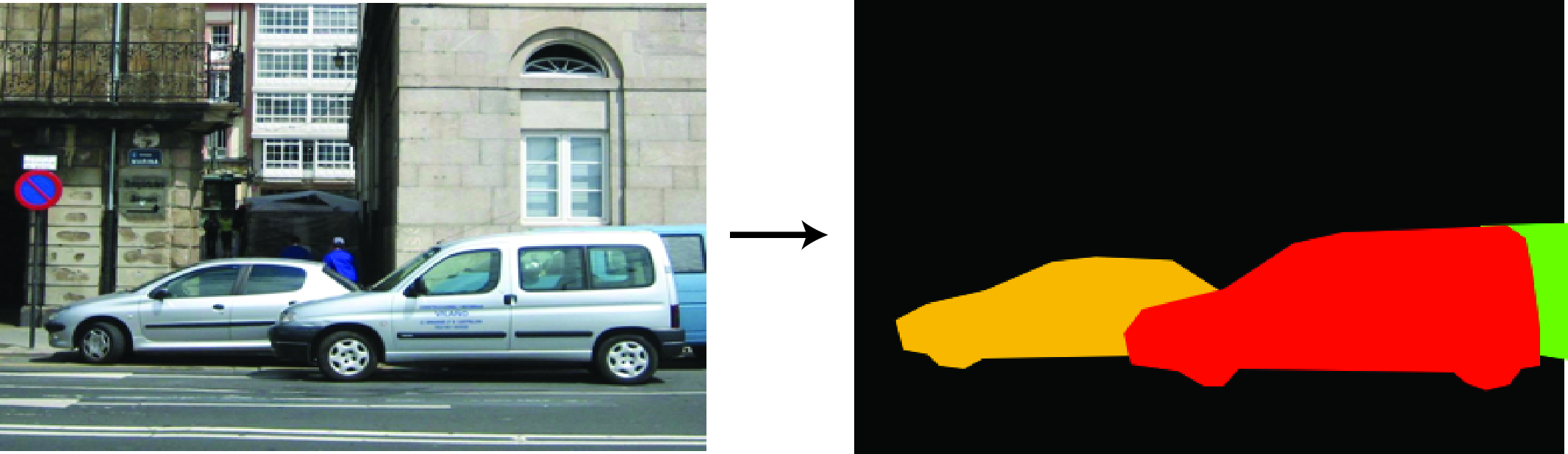
The difference from semantic segmentation is that if there are \(K\) objects of the same type, we will output \(K\) masks; conversely, semantic segmentation has no way to telling us how many objects of the same type there are, nor can it delineate between two objects of the same type that overlap; it just gives us an aggregate region of pixels that are all the pixels of the same object type.
One approach to instance segmentation is to follow the object localization pipeline but, after the bounding boxes have been proposed and labeled, feed the cropped image within each bounding box to a binary semantic segmentation function that simply predicts, for each pixel in box \(\hat{\mathbf{b}}_i\) whether it belongs to the object or not. This way we get an instance mask for each box. Such an approach was introduced in [21]. The architecture is illustrated in Figure 50.24.
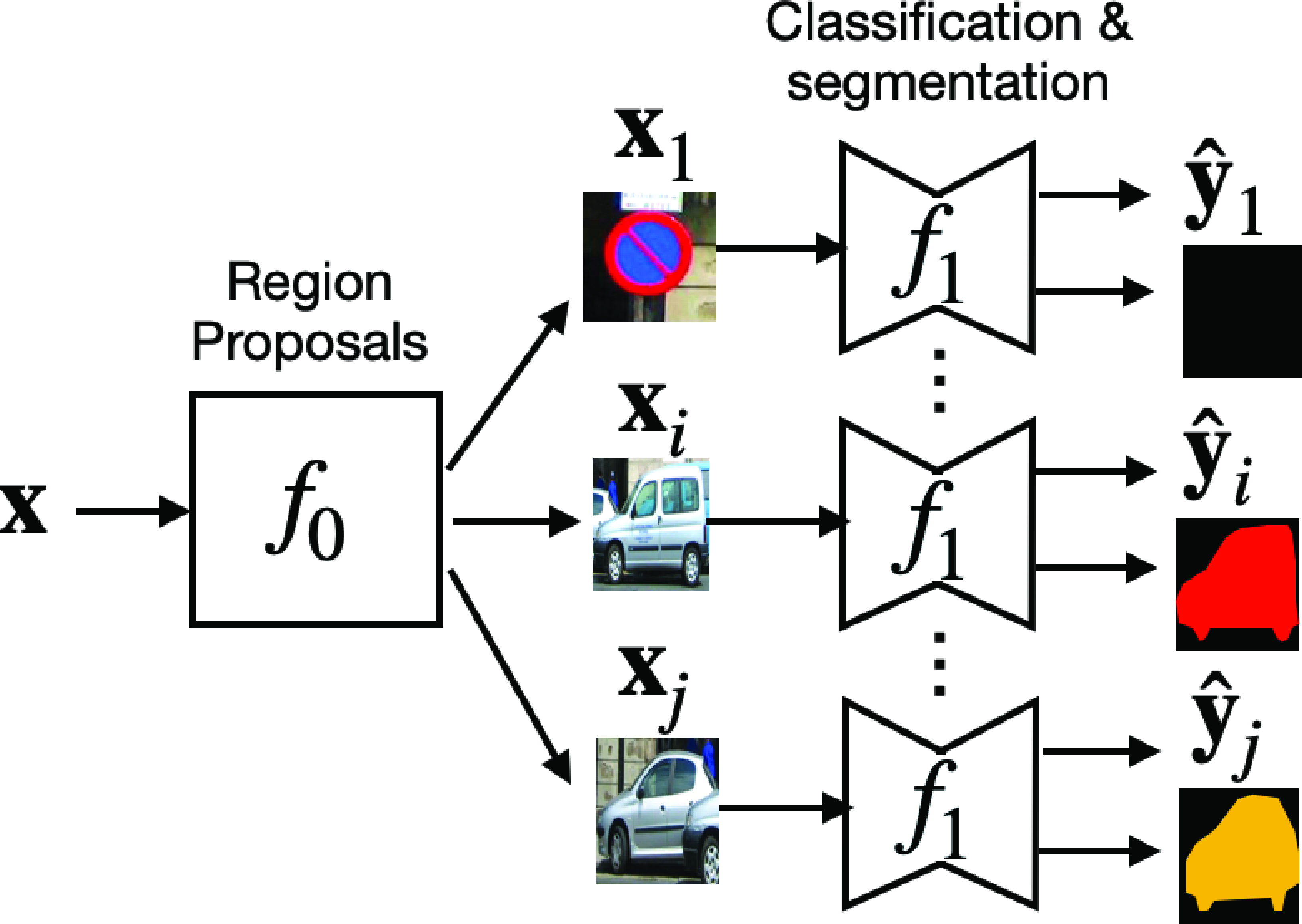
As before, \(f_0\) is a low-cost detector that proposes regions likely to contain instances of the target object. The function \(f_1\) performs classification and segmentation of the instance: \[\left[\hat{\mathbf{y}}_i, \hat{\mathbf{s}}_i \right]= f_j(\mathbf{x}, \hat{\mathbf{b}}_i)\] where \(\hat{\mathbf{y}}_i\) is the binary label confidence, and \(\hat{s}_i \left[ n,m \right]\) is the instance segmentation mask.
The loss can be written as a combination of the classification, localization, and segmentation losses that we discussed before: \[ \mathcal{L}( \{\hat{\mathbf{b}}_i, \hat{\mathbf{y}}_i\}, \{\mathbf{b}_i, \mathbf{y}_i\}) = \mathcal{L}_{\text{cls}}(\hat{\mathbf{y}}_i, \mathbf{y}_i) + \mathbb{1} (\mathbf{y}_i \neq 0) \left( \lambda_1 \mathcal{L}_{\text{loc}} (\hat{\mathbf{b}}_i, \mathbf{b}_i) + \lambda_2 \mathcal{L}_{\text{seg}} (\hat{\mathbf{s}}_i, \mathbf{s}_i) \right) \]
The first classification loss corresponds to the classification of the crop as containing the object or not; if the object is present, the second term measures the accuracy of the bounding box, and the third term measures whether the segmentation, \(\hat{\mathbf{s}}_i\), inside each bounding box matches the ground truth instance segmentation, \(\mathbf{s}_i\). The parameters \(\lambda_1\) and \(\lambda_2\) control how much weight each loss has on the final loss.
What is interesting about this formulation is that it can be extended to provide a rich representation of the detected objects. For instance, in addition to the segmentation mask, we could also regress the \(u-v\) coordinates for each pixel using an instance-centered coordinate frame, or shape maps [22]. We can also output a segmentation of the parts.
50.6.1 Shortcomings
This representation is more complete than any of the previous ones as it combines the best of all of them. It can classify, localize, and count objects and it can also deal with overlapping objects as it will produce a different segmentation mask for each instance. In some aspects, this representation might be trying to do too much; sometimes precise instance segmentation might be too challenging, even for humans.
However, this object representation still suffers from limitations due to its reliance on language in order to define the class.
50.7 Concluding Remarks
Figure 50.25 shows a pictorial summary of the different methods we have seen in this chapter to represent objects in images. The four different approaches we have described use a common set of building blocks: image classifiers, region proposals, pixelwise classifiers, and bounding box regression.
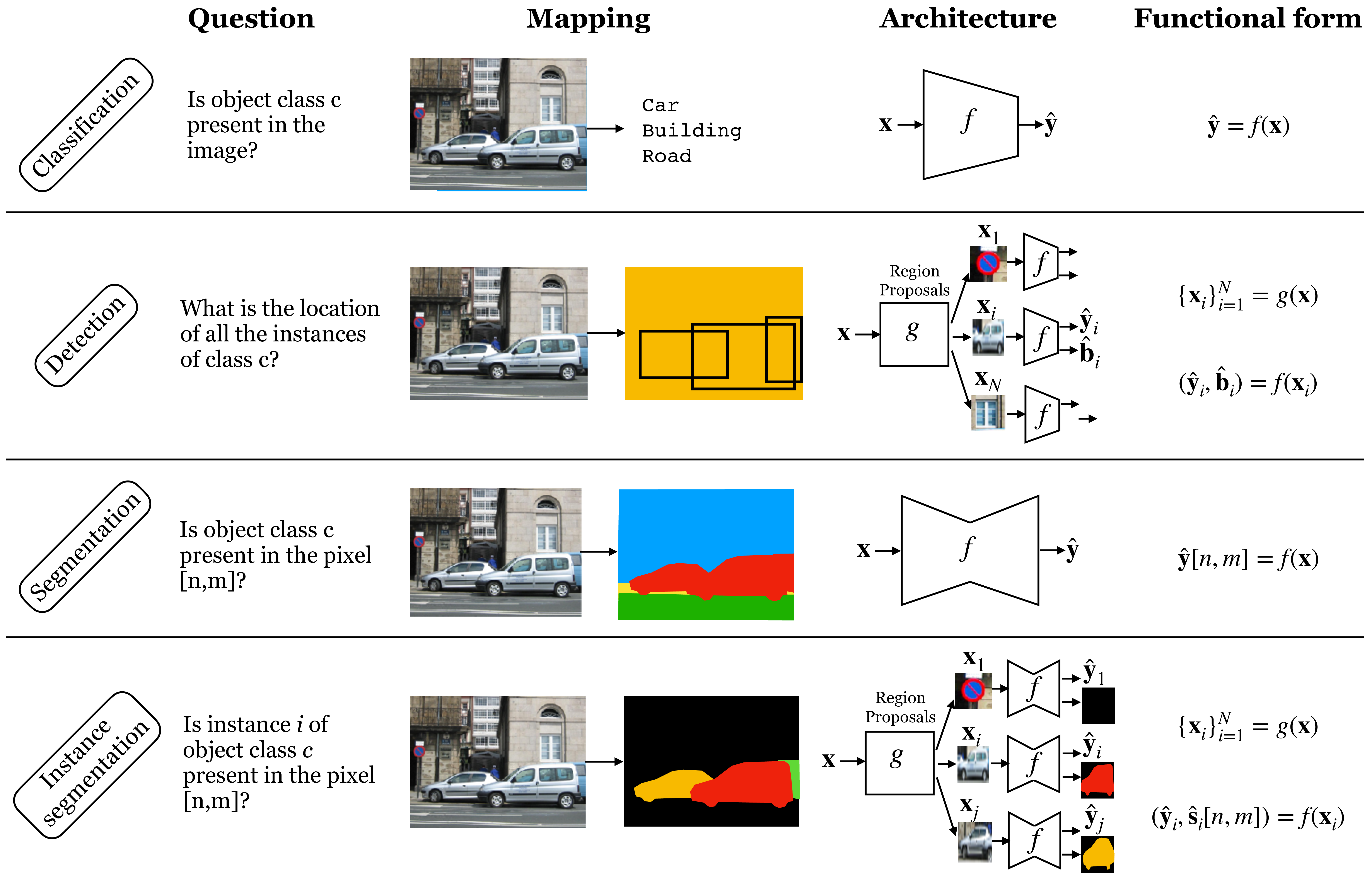
However, the representations we have described in this chapter feel very incomplete. If you are building a robot or an autonomous vehicle, such object representations are very hard to act on. A robot planning to grasp an object will need an accurate three-dimensional (3D) modeling of the object as well as an understanding of some of its physical properties in order to plan for the best grasping points. An autonomous vehicle will also need an accurate 3D description of the locations of objects in the world, together with a characterization of their dynamics. Therefore, object segmentation and classification only provide one part of the information needed.
The techniques we have described in this chapter rely on language to define what an object is (e.g., image tagging, captioning, etc.). What else can we do besides associating an object with a word? Here there are other questions that an object recognition system could try to answer:
Is this piece of matter an object? could I find other instances that might belong to the same class or is it just a random arrangement of things with little chances of being found somewhere else?
What is its 3D shape?
Is it resting on the ground? How is it supported?
What are its mechanical properties? Is it soft? Does it has parts? Is it rigid or deformable?
How will it react to external actions? Can I grasp the object? How?
What might this object be useful for? If I have to solve a task, can I use this object?
Is it alive? Can I eat it?
What is the physical process that created it? Is it artificial or natural?
How did the object arrived to its current location?
Is it stable? What will it do next?
Those are the questions that scientist would ask themselves when observing a new natural phenomena, and a computer vision system should behave as a scientist when confronted with a new visual stimuli. A system should formulate hypothesis about its visual input, devise experiments and perform interventions to answer them. One can rely on language to answer some or all of those questions, but language does not need to be the only internal representation used.