32 Generative Models
32.1 Introduction
Generative models perform (or describe) the synthesis of data. Recall the image classifier from Chapter 9, shown again below (Figure 32.1):
A generative model does the opposite (Figure 32.2):
Whereas an image classifier is a function \(f: \mathcal{X} \rightarrow \mathcal{Y}\), a generative model is a function in the opposite direction \(g: \mathcal{Y} \rightarrow \mathcal{X}\). Things are a bit different in this direction. The function \(f\) is many-to-one: there are many images that all should be given the same label “bird.” The function \(g\), conversely, is one-to-many: there are many possible outputs for any given input. Generative models handle this ambiguity by making \(g\) a stochastic function.
Although we describe \(\mathbf{y}\) as a label here, generative models can in fact take other kinds of instructions as inputs, such as text descriptions of what we want to generate or hand-drawn sketches that we wish the model to fill in.
One way to make a function stochastic is to make it a deterministic function of a stochastic input, and this is how most of the generative models in this chapter will work. We define \(g\) as a function, called a generator, that takes a randomized vector \(\mathbf{z}\) as input along with the label/description \(\mathbf{y}\), and produces an image \(\mathbf{x}\) as output, that is, \(g: \mathcal{Z} \times \mathcal{Y} \rightarrow \mathcal{X}\). Then this function can output a different image \(\mathbf{x}\) for each different setting of \(\mathbf{z}\). The generative process is as follows. First sample \(\mathbf{z}\) from a prior \(p(Z)\), then deterministically generate an image based on \(\mathbf{z}\) and \(\mathbf{y}\):
\[ \begin{aligned} \mathbf{z} \sim p(Z)\\ \mathbf{x} = g(\mathbf{z},\mathbf{y}) \end{aligned} \]
Graphical model for generating \(X \\| Y, Z\).
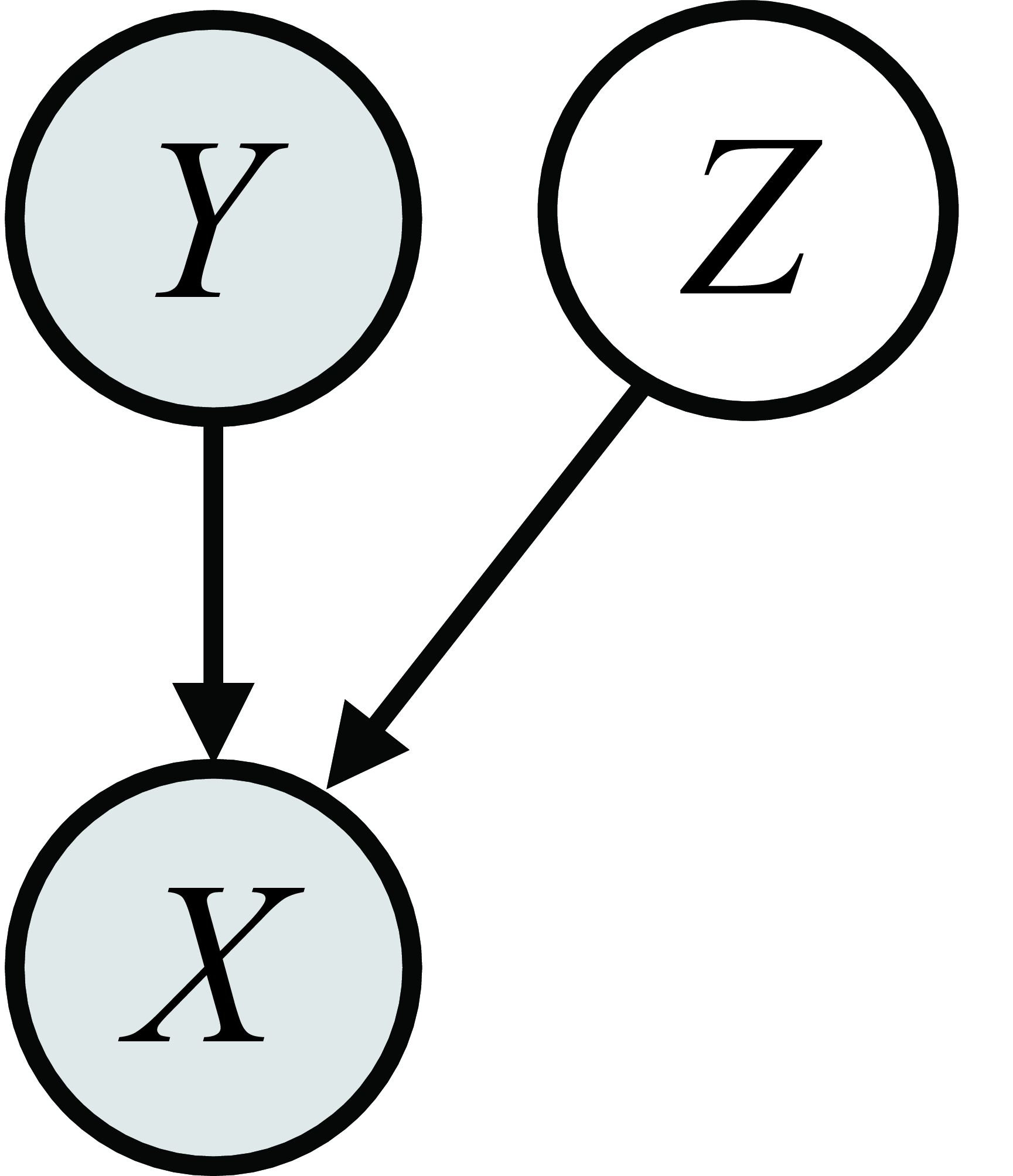
This procedure is shown in Figure 32.3:
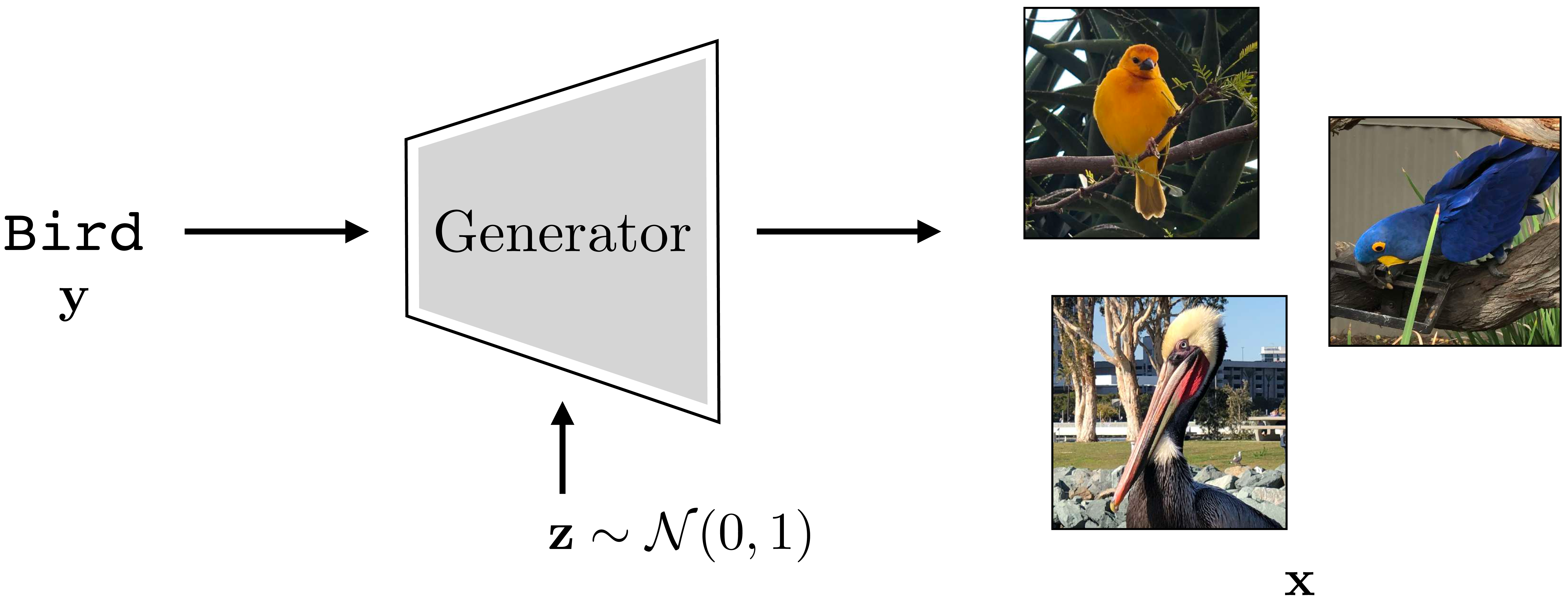
Usually we draw \(\mathbf{z}\) from a simple distribution such as Gaussian noise, that is, \(p(Z) = \mathcal{N}(\mathbf{0},\mathbf{1})\). The way to think of \(\mathbf{z}\) is that it is a vector of latent variables, which specify all the attributes of the images other than those determined by the label. These variables are called latent because they are not directly observed in the training data (it just consists of images \(\mathbf{x}\) and their labels \(\mathbf{y}\)). In our example, \(\mathbf{y}\) tells \(g\) to make a bird but the \(\mathbf{z}\)-vector is what specifies exactly which bird. Different dimensions of \(\mathbf{z}\) specify different attributes, such as the size, color, pose, background, and so on; everything necessary to fully determine the output image.
32.2 Unconditional Generative Models
Sometimes we wish to simply make up data from scratch; in fact, this is the canonical setting in which generative models are often studied. To do so, we can simply drop the dependency on the input \(\mathbf{y}\). This yields a procedure for making data from scratch:
\[\begin{aligned} \mathbf{z} \sim p(Z)\\ \mathbf{x} = g(\mathbf{z}) \end{aligned}\]
Graphical model for an unconditional generative model. 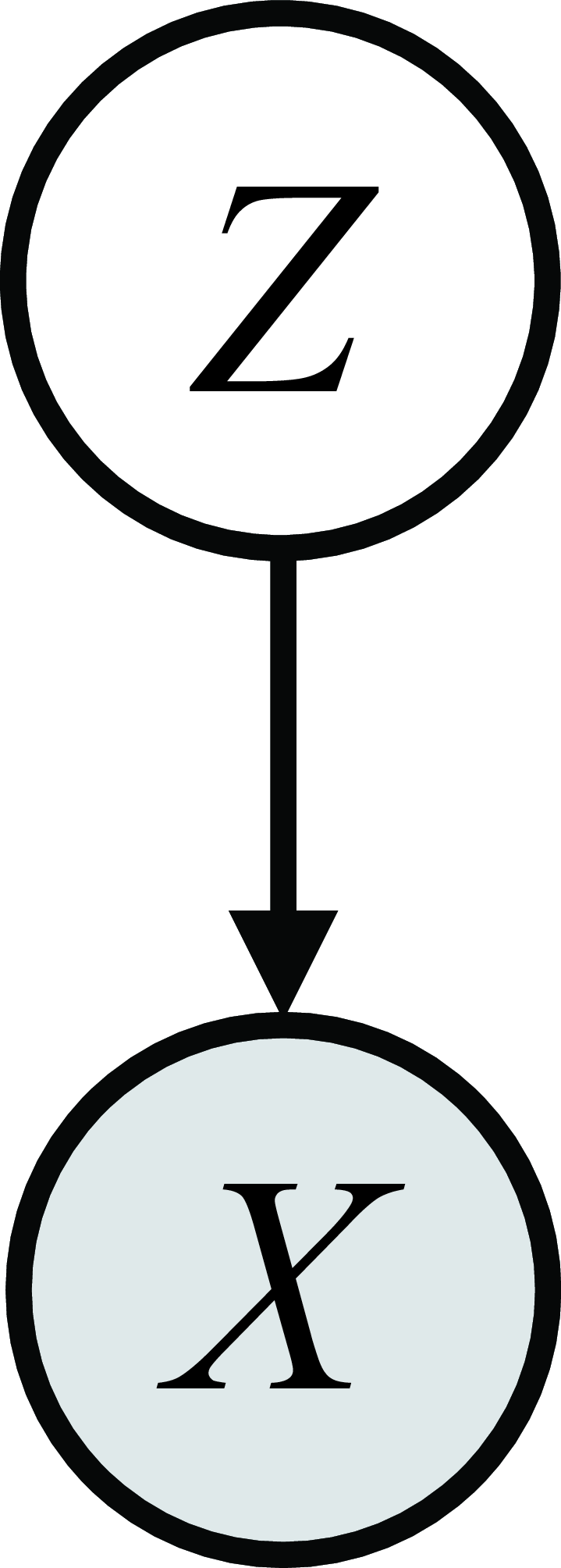
We call this an unconditional generative model because it is model of the unconditional distribution \(p(X)\). Generally we will refer to unconditional generative models simply as generative models and use the term conditional generative model for a model of any conditional distribution \(p(X \bigm | Y)\). Conditional generative models will be the focus of Chapter 34; in the present chapter we will restrict our attention, from this point on, to unconditional models.
Why bother with (unconditional) generative models, which make up random synthetic data? At first this may seem a silly goal. Why should we care to make up images from scratch? One reason is content creation; we will see other reasons later, but content creation is a good starting point. Suppose we are making a video game and we want to automatically generate a bunch of exciting levels for the player the explore. We would like a procedure for making up new levels from scratch. Such have been successfully used to generate random landscapes and cities for virtual realities [1]. Suppose we want to add a river to a landscape. We need to decide what path the river should take. A simple program for generating the path could be “walk an increment forward, flip a coin to decide whether to turn left or right, repeat.”
Here is that program in pseudocode:

Here are a few rivers this program draws (Figure 32.4):

This program relies on a sequence of coin flips to generate the path of the river. In other words, the program took a randomized vector (noise) as input, and converted this vector into an image of the path of the river. It’s exactly the same idea as we described previously for generating images of birds, just this time the generator is a program that makes rivers (Figure 32.5):

This generator was written by hand. Next we will see generative models that learn the program that synthesizes data.
32.3 Learning Generative Models
How can we learn to synthesize images that look realistic? The machine learning way to do this is to start with a training set of examples of real images, \(\{\mathbf{x}^{(i)}\}_{i=1}^N\). Recall that in supervised learning, an example was defined as an {input, output} pair; here things are actually no different, only the input happens to be the null set. We feed these examples to a learner, which spits out a generator function. Later, we may query the generator with new, randomized \(\mathbf{z}\)-vectors to produce novel outputs, a process called sampling from the model. This two-stage procedure is shown in Figure 32.6:

32.3.1 What’s the Objective of Generative Modeling?
The objective of the learner is to create a generator that produces synthetic data, \(\{\hat{\mathbf{x}}^{(i)}\}_{i=1}^N\), that looks like the real data, \(\{\mathbf{x}^{(i)}\}_{i=1}^N\). There are a lot of ways of define “looks like” and they each result in a different kind of generative model. Two examples are:
Synthetic data looks like real data if matches the real data in terms of certain marginal statistics, for example, it has the same mean color as real photos, or the same color variance, or the same edge statistics.
Synthetic data looks like real data if it has high probability under a density model fit to the real data.
The first approach is the one we saw in Chapter 27 on statistical image models, where synthetic textures were made that had the same filter response statistics as a real training example. This approach works well when we only want to match certain properties of the training data. The second approach, which is the main focus of this chapter, is better when we want to produce synthetic data that matches all statistics of the training examples.
In practice, we may not be able to match all statistics, due to limits of the model’s capacity.
To be precise, the goal of the deep generative models we consider in this chapter is to produce synthetic data that is identically distributed as the training data, that is, we want \(\hat{\mathbf{x}} \sim p_{\texttt{data}}\) where \(p_{\texttt{data}}\) is the true process that produced the training data.
What if our model just memorizes all the training examples and generates random draws from this memory? Indeed, memorized training samples perfectly satisfy the goal of making synthetic data that looks real. A second, sometimes overlooked, property of a good generative model is that it be a simple, or smooth, function, so that it generalizes to producing synthetic samples that look like the training data but are not identical to it. A generator that only regurgitates the training data is overfit in the same way a classifier that memorizes the training data is overfit. In both cases, the true goal is to fit the training data and to do so with a function that generalizes.
32.3.2 The Direct Approach and the Indirect Approach
There are two general approaches to forming data generators:
Direct approach: learn the function \(G: \mathcal{Z} \rightarrow \mathcal{X}\).
Indirect approach: learn a function \(E: \mathcal{X} \rightarrow \mathbb{R}\) and generate samples by finding values for \(\mathbf{x}\) that score highly under this function.
In the generative modeling literature, the direct approach is sometimes called an implicit model. This is because the probability density is never explicitly represented. However, note that this “implicit” model explicitly describes the way data is generated. To avoid confusion, we will not use this terminology.
So far in this chapter we have focused on the direct approach, and it is schematized in Figure 32.6. Interestingly, the direct approach only became popular recently, with models like generative adversarial networks (GANs) and diffusion models, which we will see later in this chapter. The indirect approach is more classical, and describes many of the methods we saw in Chapter 27. Indirect approaches come in two general flavors, density models and energy models, which we will describe next. Both follow the schematic given in Figure 32.7:
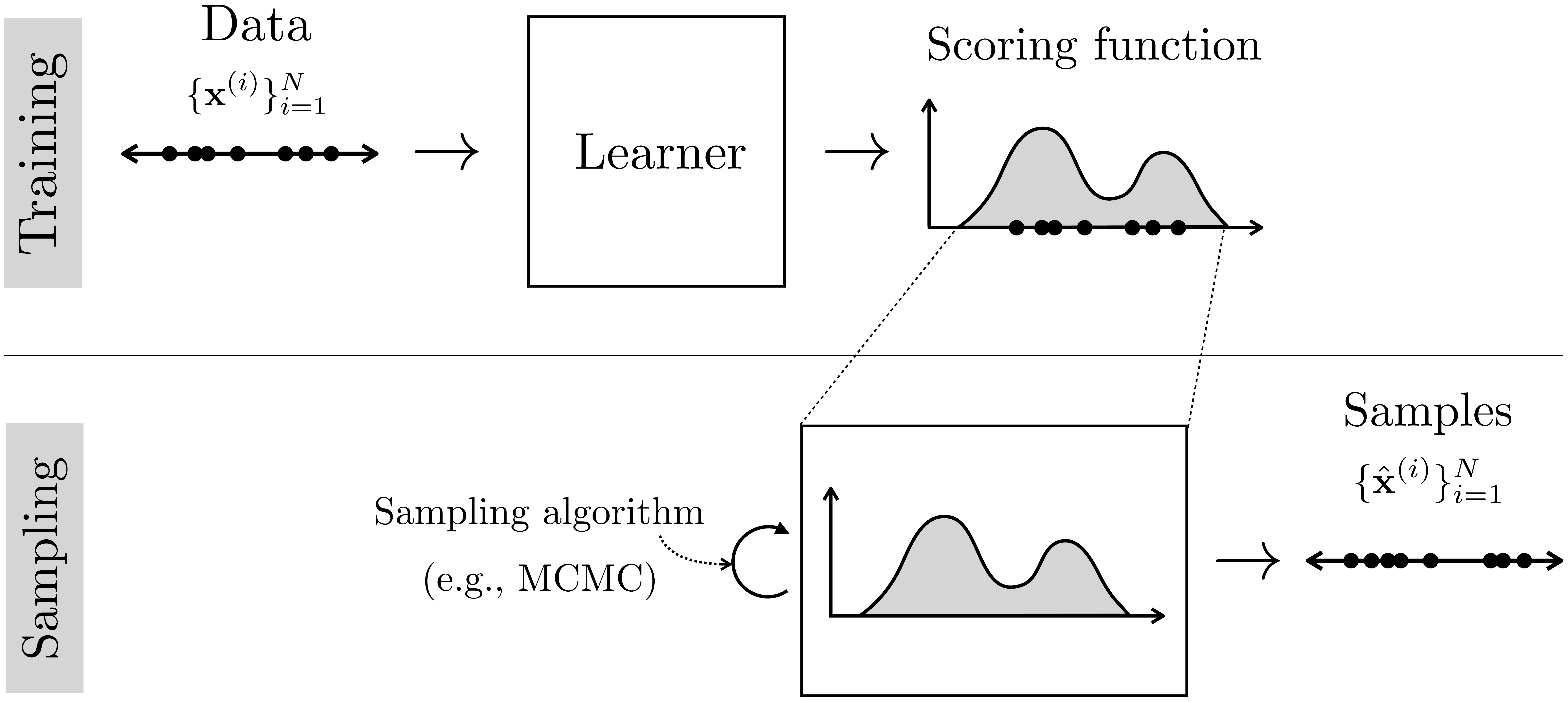
32.4 Density Models
Some generative models not only produce generators but also yield a probability density function \(p_{\theta}\), fit to the training data. This density function may play a role in training the generator (e.g., we want the generator to produce samples from \(p_{\theta}\)), or the density function may be the goal itself (e.g., we want to be able to estimate the probability of datapoints in order to detect anomalies).
In fact, some generative models only produce a density \(p_{\theta}\) and do not learn any explicit generator function. Instead, samples can be drawn from \(p_{\theta}\) using a sampling algorithm, such as Markov Chain Monte Carlo (MCMC), that takes a density as input and produce samples from it as output. This is a form of the indirect approach to synthesizing data that we mentioned above (Figure 32.7).
32.4.1 Learning Density Models
The objective of the learner for a density model is to output a density function \(p_{\theta}\) that is as close as possible to \(p_{\texttt{data}}\). How should we measure closeness? We can define a divergence between the two distributions, \(D\), and then solve the following optimization problem: \[\mathop{\mathrm{arg\,min}}_{p_\theta} D(p_{\theta}, p_{\texttt{data}})\] The problem is that we do not actually have the function \(p_{\texttt{data}}\), we only have samples from this function, \(\mathbf{x} \sim p_{\texttt{data}}\). Therefore, we need a divergence \(D\) that measures the distance between \(p_{\theta}\) and \(p_{\texttt{data}}\) while only accessing samples from \(p_{\texttt{data}}\).
The divergence need not be a proper distance metric, and often is not; it can be nonsymmetric, where \(D(p,q) \neq D(q,p)\), and need not satisfy the triangle-inequality. In fact, a divergence is defined by just two properties: nonnegativity and \(D(p,q) = 0 \iff p=q\).
A common choice is to use the Kullback-Leibler (KL) divergence, which is defined as follows: \[\begin{aligned} p_{\theta}^* &= \mathop{\mathrm{arg\,min}}_{p_\theta} \mathrm{KL}\left(p_{\text {data }} \| p_\theta\right)\\ &= \mathop{\mathrm{arg\,min}}_{p_\theta} \mathbb{E}_{\mathbf{x} \sim p_{\texttt{data}}}\Big[-\log \frac{p_{\theta}(\mathbf{x})}{p_{\texttt{data}}(\mathbf{x})}\Big]\\ &= \mathop{\mathrm{arg\,max}}_{p_\theta} \mathbb{E}_{\mathbf{x} \sim p_{\texttt{data}}}\big[\log p_{\theta}(\mathbf{x})\big] - \mathbb{E}_{\mathbf{x} \sim p_{\texttt{data}}}\big[\log p_{\texttt{data}}(\mathbf{x})\big]\\ &= \mathop{\mathrm{arg\,max}}_{p_\theta} \mathbb{E}_{\mathbf{x} \sim p_{\texttt{data}}}\big[\log p_{\theta}(\mathbf{x})\big] \quad \triangleleft \quad\text{dropped second term since no dependence on $p_{\theta}$} \\ &\approx \mathop{\mathrm{arg\,max}}_{p_\theta} \frac{1}{N} \sum_{i=1}^N \log p_{\theta}(\mathbf{x}^{(i)}) \end{aligned} \tag{32.1}\] where the final line is an empirical estimate of the expectation by sampling over the training dataset \(\{\mathbf{x}^{(i)}\}_{i=1}^N\). Equation 32.1 is the expected log likelihood of the training data under the model’s density function.
\(\mathrm{KL}\left(p_{\text {data }} \| p_\theta\right)\) is sometime called the forward KL divergence, and it measures the probability of the data under the model distribution. The reverse KL divergence, \(\mathrm{KL}\left(p_\theta \| p_{\text {data }}\right)\), does the converse, measuring the probability of the model’s samples under the data distribution; because we do not have access to the true data distribution, the reverse KL divergence usually cannot be computed.
Maximizing this objective is therefore a form of max likelihood learning. Pictorially we can visualize the max likelihood objective as trying to push up the density over each observed datapoint:
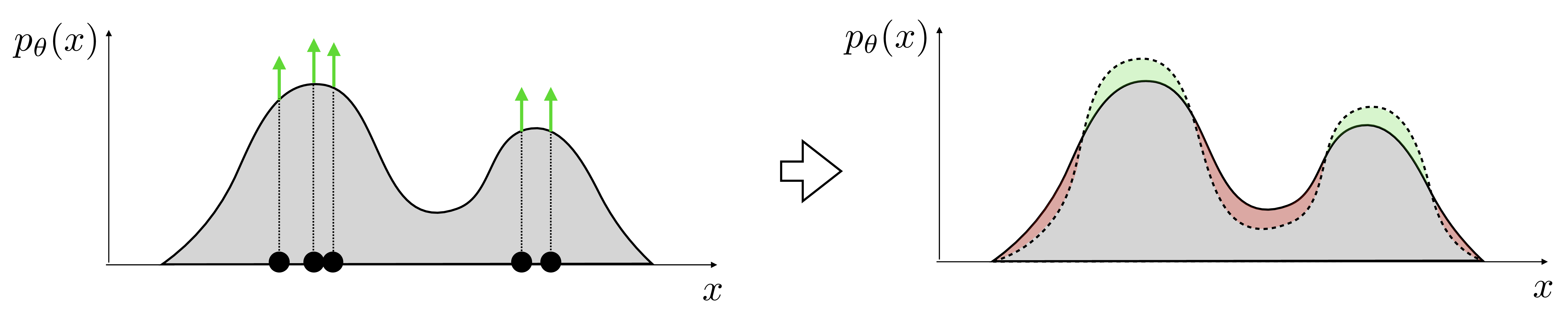
Remember that a probability density function (pdf) is a function \(p_{\theta}: \mathcal{X} \rightarrow [0,\infty)\) with \(\int_{\mathbf{x}} p_{\theta}(\mathbf{x})d\mathbf{x} = 1\) (i.e. it’s normalized). To learn a pdf, we will typically learn the parameters of a family of pdfs. For example, in Section 32.6, we will cover learning the parameters of the Gaussian family of pdfs. All members of such a the family are normalized nonnegative functions; this way we do not need to add an explicit constraint that the learned function have these properties, we are simply searching over a space of functions all of which have these properties. This means that whenever we push up density over datapoints, we are forced to sacrifice density over other regions, so implicitly we are removing density from places where there is no data, as indicated by the red regions in Figure 32.8.
In the next section we will see an alternative approach where the parametric family we search over need not be normalized.
32.5 Energy-Based Models
Density models constrain the learned function to be normalized, that is, \(\int_{\mathbf{x}} p_{\theta}(\mathbf{x})d\mathbf{x} = 1\). This constraint is often hard to realize. One approach is to learn an unnormalized function \(E_{\theta}\), then convert it to the normalized density \(p_{\theta} = \frac{e^{-E_{\theta}}}{Z(\theta)}\), where \(Z(\theta) = \int_{\mathbf{x}} e^{-E_{\theta}(\mathbf{x})}d\mathbf{x}\) is the normalizing constant. The \(Z(\theta)\) can be very expensive to compute and often can only be approximated.
The parametric form \(\frac{e^{-E_{\theta}}}{Z(\theta)}\) is sometimes referred to as a Boltzmann or Gibbs distribution.
Notice that \(Z\) is a function of model parameters \(\theta\) but not of datapoint \(\mathbf{x}\), since we integrate over all possible data values.
Note that low energy \(\Rightarrow\) high probability. So we minimize energy to maximize probability.
Energy-based models (EBMs) address this by simply skipping the step where we normalize the density, and letting the output of the learner just be \(E_\theta\). Even though it is not a true probability density, \(E_{\theta}\) can still be used for many of the applications we would want a density for. This is because we can compare relative probabilities with \(E_\theta\):
\[\begin{aligned} \frac{p_\theta(\mathbf{x}_1)}{p_\theta(\mathbf{x}_2)} = \frac{e^{-E_\theta(\mathbf{x}_1)}/Z(\theta)}{e^{-E_\theta(\mathbf{x}_2)}/Z(\theta)} = \frac{e^{-E_\theta(\mathbf{x}_1)}}{e^{-E_\theta(\mathbf{x}_2)}} \end{aligned}\] Knowing relative probabilities is all that is required for sampling (via MCMC), for outlier detection (the relatively lowest probability datapoint in a set of datapoints is the outlier), and even for optimizing over a space of of data to find the datapoint that is max probability (because \(\mathop{\mathrm{arg\,max}}_{\mathbf{x} \in \mathcal{X}} p_{\theta}(\mathbf{x}) = \mathop{\mathrm{arg\,max}}_{\mathbf{x} \in \mathcal{X}} -E_{\theta}(\mathbf{x})\)).
To solve such a maximization problem, we might want to find the gradient of the log probability density with respect to \(\mathbf{x}\); it turns out this gradient is identical to the gradient of \(-E_{\theta}\) with respect to \(\mathbf{x}\)! \[\begin{aligned} \nabla_{\mathbf{x}} \log p_{\theta}(\mathbf{x}) &= \nabla_{\mathbf{x}} \log \frac{e^{-E_{\theta}(\mathbf{x})}}{Z(\theta)}\\ &= -\nabla_{\mathbf{x}} E_{\theta}(\mathbf{x}) - \nabla_{\mathbf{x}} \log Z(\theta)\\ &= -\nabla_{\mathbf{x}} E_{\theta}(\mathbf{x}) \end{aligned}\] In sum, energy functions can do most of what probability densities can do, except that they do not give normalized probabilities. Therefore, they are insufficient for applications where communicating probabilities is important for either interpretability or for interfacing with downstream systems that require knowing true probabilities.
A case where a density model might be preferable over an energy model is a medical imaging system that needs to communicate to doctors the likelihood that a patient has cancer.
32.5.1 Learning Energy-Based Models
Learning the parameters of an energy-based model is a bit different than learning the parameters of a density model. In a density model, we simply increase the probability mass over observed datapoints, and because the density is a normalized function, this implicitly pushes down the density assigned to regions where there is no observed data. Since energy functions are not normalized, we need to add an explicit negative term to push up energy where there are no datapoints, in addition to the positive term of pushing down energy where the data is observed. One way to do so is called contrastive divergence [2]. On each iteration of optimization, this method modifies the energy function to decrease the energy assigned to samples from the data (positive term) and to increase the energy assigned to samples from the model (i.e., samples from the energy function itself; negative term), as shown in Figure 32.9:

Once the energy function perfectly adheres to the data, samples from the model are identical to samples from the data and the positive and negative terms cancel out. This should make intuitive sense because we don’t want the energy function to change once we have perfectly fit the data. It turns out that mathematically this procedure is an approximation to the gradient of the log likelihood function. Defining \(p_{\theta} = \frac{e^{-E_{\theta}}}{Z(\theta)}\), start by decomposing the gradient of the log likelihood into two terms, which, as we will see, will end up playing the role of positive and negative terms: \[\begin{aligned} \nabla_{\theta} \mathbb{E}_{\mathbf{x} \sim p_{\texttt{data}}}[\log p_{\theta}(\mathbf{x})] &= \nabla_{\theta} \mathbb{E}_{\mathbf{x} \sim p_{\texttt{data}}}[\log \frac{e^{-E_{\theta}(\mathbf{x})}}{Z(\theta)}]\\ &= -\mathbb{E}_{\mathbf{x} \sim p_{\texttt{data}}}[\nabla_{\theta} E_{\theta}(\mathbf{x})] - \nabla_{\theta} \log Z(\theta) \end{aligned} \tag{32.2}\]
The first term is the positive term gradient, which tries to modify parameters to decrease the energy placed on data samples. The second term is the negative term gradient; here it appears as an intractable integral, so our strategy is to rewrite it as an expectation, which can be approximated via sampling: \[\begin{aligned} \nabla_{\theta} \log Z(\theta) &= \frac{1}{Z(\theta)}\nabla_{\theta}Z(\theta) \\ \end{aligned} \tag{32.3}\]
\[\begin{aligned} \nabla_{\theta} \log Z(\theta) &= \frac{1}{Z(\theta)} \nabla_{\theta} \int_x e^{-E_{\theta}(\mathbf{x})}d\mathbf{x} &&\quad\quad \triangleleft \quad \text{definition of $Z$}\\ &= \frac{1}{Z(\theta)} \int_x \nabla_{\theta} e^{-E_{\theta}(\mathbf{x})}d\mathbf{x} &&\quad\quad \triangleleft \quad \text{exchange sum and grad}\\ &= \frac{-1}{Z(\theta)} \int_x e^{-E_{\theta}(\mathbf{x})} \nabla_{\theta} E_{\theta}(\mathbf{x})d\mathbf{x}\\ &= -\int_x \frac{e^{-E_{\theta}(\mathbf{x})}}{Z(\theta)} \nabla_{\theta} E_{\theta}(\mathbf{x})d\mathbf{x}\\ &= -\int_x p_{\theta}(\mathbf{x}) \nabla_{\theta} E_{\theta}(\mathbf{x})d\mathbf{x} &&\quad\quad \triangleleft \quad \text{definition of $p_{\theta}$}\\ &= -\mathbb{E}_{\mathbf{x} \sim p_{\theta}}[\nabla_{\theta} E_{\theta}(\mathbf{x})] &&\quad\quad \triangleleft \quad \text{definition of expectation} \end{aligned} \tag{32.4}\]
In Equation 32.3 we use a very useful identity from the chain rule of calculus, which appears often in machine learning: \(\nabla_{x} \log f(x) = \frac{1}{f(x)} \nabla_{x} f(x)\).
Plugging Equation 32.4 back into Equation 32.2, we arrive at:
\[\begin{aligned} \nabla_{\theta} \mathbb{E}_{\mathbf{x} \sim p_{\texttt{data}}}[\log p_{\theta}(\mathbf{x})] &= -\mathbb{E}_{\mathbf{x} \sim p_{\texttt{data}}}[\nabla_{\theta}E_{\theta(\mathbf{x})}] + \mathbb{E}_{\mathbf{x} \sim p_{\theta}}[\nabla_{\theta} E_{\theta}(\mathbf{x})] \end{aligned}\]
Both expectations can be approximated via sampling: defining \(\mathbf{x}^{(i)} \sim p_{\texttt{data}}\) and \(\hat{\mathbf{x}}^{(i)} \sim p_{\theta}\), and taking \(N\) such samples, we have
\[\begin{aligned} -\mathbb{E}_{\mathbf{x} \sim p_{\texttt{data}}}[\nabla_{\theta}E_{\theta(\mathbf{x})}] + \mathbb{E}_{\mathbf{x} \sim p_{\theta}}[\nabla_{\theta} E_{\theta}(\mathbf{x})] &\approx -\frac{1}{N} \sum_{i=1}^N \nabla_{\theta}E_{\theta}(\mathbf{x}^{(i)}) + \frac{1}{N} \sum_{i=1}^N \nabla_{\theta}E_{\theta}(\hat{\mathbf{x}}^{(i)})\\ &= \frac{1}{N} \nabla_{\theta} \sum_{i=1}^N (-E_{\theta}(\mathbf{x}^{(i)}) + E_{\theta}(\hat{\mathbf{x}}^{(i)})) \end{aligned}\]
The last line should make clear the intuition: we establish a contrast between data samples and current model samples, then update the model to decrease this contrast, bringing the model closer to the data. Once \(\mathbf{x}^{(i)}\) and \(\hat{\mathbf{x}}^{(i)}\) are identically distributed, this gradient will be zero (in expectation); we have perfectly fit the data and no further updates should be taken.
Under our formalization of a learning problem as an objective, hypothesis space, and optimizer, contrastive divergence is an optimizer; it’s an optimizer specifically built for max likelihood objectives over energy functions. Contrastive divergence tells us how to approximate the gradient of the likelihood function, which can then be plugged into any gradient descent method.
32.5.2 Comparing Different Kinds of Generative Models
Some generative models give density or energy functions, others give generator functions, and still others give both. We can summarize all these kinds of models with the following learning diagram:
 rectangle (4.2,2.4); % outer box
\fill[black!20] (0.1,1.3) rectangle (4.1,2.3); % gray box
\node[] at (2.0,1.8) {{\bf Generative modeling}};
\node[] at (-1.5,2.4) {Data};
\node[] at (-1.5,1.8) {$\{x^{(i)}\}_{i=1}^N$};
\node[] at (-0.5,1.8) {{\Large $ \rightarrow$}};
\node[] at (6.4,2.9) {Density function};
\node[] at (6.4,2.3) {$p_{\theta}: \mathcal{X} \rightarrow [0,\infty)$};
\node[] at (9.4,2.9) {Energy function};
\node[] at (9.4,2.3) {$E_{\theta}: \mathcal{X} \rightarrow \mathbb{R}$};
\node[] at (6.4,1.5) {Generator};
\node[] at (6.4,0.9) {$g_{\theta}: \mathcal{Z} \rightarrow \mathcal{X}$};
\node[] at (4.7,1.7) {{\Large $ \rightarrow$}};
\end{tikzpicture}")
Each of these families of model has its own advantages and disadvantages. Generators have latent variables \(\mathbf{z}\) that control the properties of the generated image. Changing these variables can change the generated image in meaningful ways; we will explore this idea in greater detail in the next chapter. In contrast, density and energy models do not have latent variables that directly control generated samples. Conversely, an advantage of density/energy functions is that they provide scores related to the likelihood of data. These scores (densities or energies) can be used to detect anomalies and unusual events, or can be optimized to synthesize higher quality data.
Some of the generative models we will describe in this chapter and the next are categorized along these dimensions in Table 32.1.
Note that this is a rough categorization, meant to reflect the most straightforward usage of these models. With additional effort some of the ❌s can be converted to ✅s; for example, one can do additional inference to sample from a density model, or one can extract a lower-bound estimate of density from a variational autoencoder (VAE) or diffusion model.
| Method | Latents? | Density/Energy? | Generator? |
|---|---|---|---|
| Energy-based models | ❌ | ✅ (energy only) | ❌ |
| Gaussian | ❌ | ✅ | ❌ |
| Autoregressive models | ❌ | ✅ | ✅ (slow) |
| Diffusion models | ✅ (high-dimensional) | ❌ | ✅ (slow) |
| GANs | ✅ | ❌ | ✅ |
| VAEs | ✅ | ❌ | ✅ |
Generative models can also be distinguished according to their objectives, hypothesis spaces, and optimization algorithms. Some classes of model, such as autoregressive models, refer to just a particular kind of hypothesis space, whereas other classes of model, such as VAEs, are much more specific in referring to the conjunction of an objective, a general family of hypothesis spaces, and a particular optimization algorithm.
In the next sections, and in the next chapter, we will dive into the details of exactly how each of these models works.
32.6 Gaussian Density Models
One of the simplest and most useful density models is the Gaussian distribution, which in one dimension (1D) is: \[\begin{aligned} p_{\theta}(x) = \frac{1}{Z}e^{-(x-\theta_1)^2/(2\theta_2)} \end{aligned}\] This density has two parameters \(\theta_1\) and \(\theta_2\), which are the mean and variance of the distribution. The normalization constant \(Z\) ensures that the function is normalized. This is the typical strategy in defining density models: create a parameterized family of functions such that any function in the family is normalized. Given such a family, we search over the parameters to optimize a generative modeling objective.
For density models, the most common objective is max likelihood: \[\begin{aligned} \mathbb{E}_{x \sim p_{\texttt{data}}}[\log p_{\theta}(x)] \approx \frac{1}{N} \sum_{i=1}^N \log p_{\theta}(x^{(i)}) \end{aligned}\] For a 1D Gaussian, this has a simple form: \[\begin{aligned} \frac{1}{N} \sum_{i=1}^N \log \frac{1}{Z}e^{-(x^{(i)}-\theta_1)^2/(2\theta_2)} = -\log(Z) + \frac{1}{N}\sum_{i=1}^N (x^{(i)}-\theta_1)^2/(2\theta_2) \end{aligned}\] Optimizing with respect to \(\theta_1\) and \(\theta_2\) could be done via gradient descent or random search, but in this case there is also an analytical solution we can find by setting the gradient to be zero. For \(\theta_1^*\) we have: \[\begin{aligned} \frac{\partial \big(-\log Z + \frac{1}{N}\sum_{i=1}^N (x^{(i)}-\theta_1^*)^2/(2\theta_2^*)\big)}{\partial \theta_1^*} = 0\\ \frac{1}{N}\sum_{i=1}^N 2(x^{(i)}-\theta_1^*)/(2\theta_2^*) = 0\\ \sum_{i=1}^N x^{(i)} - \sum_{i=1}^N \theta_1^* = 0\\ \theta_1^* = \frac{1}{N}\sum_{i=1}^N x^{(i)} \end{aligned}\] For \(\theta_2^*\) we need to note that \(Z\) depends on \(\theta_2^*\) and in particular notice that \(\frac{\partial (-\log Z)}{\partial \theta_2^*} = \frac{1}{2\theta_2^*}\): \[\begin{aligned} \frac{\partial \big(-\log Z + \frac{1}{N}\sum_{i=1}^N (x^{(i)}-\theta_1^*)^2/(2\theta_2^*)\big)}{\partial \theta_2^*} = 0\\ \frac{1}{2\theta_2^*} - \frac{1}{N}\sum_{i=1}^N 2(x^{(i)}-\theta_1^*)^2/(2\theta_2^*)^2 = 0\\ 2\theta_2^* - \frac{1}{N}\sum_{i=1}^N 2(x^{(i)}-\theta_1^*)^2 = 0\\ \theta_2^* = \frac{1}{N}\sum_{i=1}^N (x^{(i)}-\theta_1^*)^2 \end{aligned}\] You might recognize the solutions for \(\theta_1^*\) and \(\theta_2^*\) as the empirical mean and variance of the data, respectively. This makes sense: we have just shown that to maximize the probability of the data under a Gaussian, we should set the mean and variance of the Gaussian to be the empirical mean and variance of the data.
This fully describes the learning problem, and solution, for a 1D Gaussian density model. We can put it all together in the learning diagram below:

Gaussian density models are just about the simplest density models one can come up with. You may be wondering, do we actually use them for anything in computer vision, or are they just a toy example? The answer is that yes we do use them—in fact, we use them all the time. For example, in least-squares regression, we are simply fitting a Gaussian density to the conditional probability \(p(Y \bigm | X)\). If we want a more complicated density, we may use a mixture of multiple Gaussian distributions, called a Gaussian mixture model (GMM), which we will encounter in the next chapter. It’s useful to get comfortable with Gaussian fits because (1) they are a subcomponent of many more sophisticated models, and (2) they showcase all the key components of density modeling, with a clear objective, a parameterized hypothesis space, and an optimizer that finds the parameters that maximize the objective.
32.7 Autoregressive Density Models
A single Gaussian is a very limited model, and the real utility of Gaussians only shows up when they are part of a larger modeling framework. Next we will consider a recipe for building highly expressive models out of simple ones. There are many such recipes and the one we focus on here is called an autoregressive model.
The idea of an autoregressive model is to synthesize an image pixel by pixel. Each new pixel is decided on based on the sequence already generated. You can think of this as a simple sequence prediction problem: given a sequence of observed pixels, predict the color of the next one. We use the same learned function \(f_{\theta}\) to make each subsequent prediction.
Figure 32.10 shows this setup. We predict each next pixel from the partial image already completed. The red bordered region is the context the prediction is based on. This context could be the entire image synthesized so far or it could be a smaller region, like shown here. The green bordered pixel is the one we are predicting given this context. In this example, we always predict the bottom-center pixel in the context window. After making our prediction, we decide what color pixel to add to the image based on that prediction; we may add the color predicted as most likely, or we might sample from the predicted distribution so that we get some randomness in our completion. Then, to predict the next missing pixel we slide the context over by one and repeat.
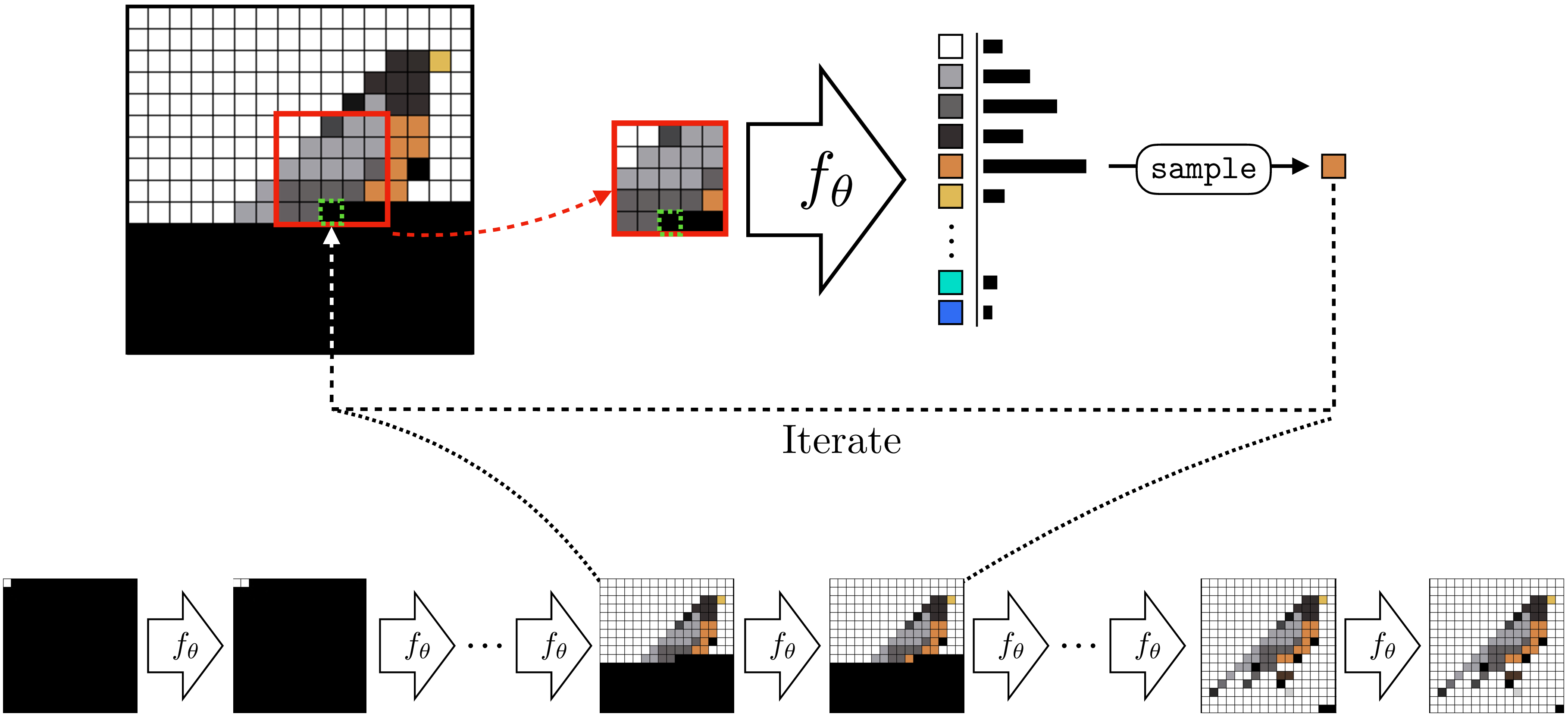
You might have noticed that this setup looks very similar to the Efros-Leung texture synthesis algorithm in Section 28.4, and indeed that was also an autoregressive model. The Efros-Leung algorithm was a nonparametric method that worked by stealing pixels from the matching regions of an exemplar texture. Now we will see how to do autoregressive modeling with a learned, parameteric predicton function \(f_{\theta}\), such as a deep net.
These models can be easily understood by first considering the problem of synthesizing one pixel, then two, and so on. The first observation to make is that it’s pretty easy to synthesize a single grayscale pixel. Such a pixel can take on 256 possible values (for a standard 8-bit grayscale image). So it suffices to use a categorical distribution to represent the probability that the pixel takes on each of these possible values. The categorical distribution is fully expressive: any possible probability mass function (pmf) over the 256 values can be represented with the categorical distribution. Fitting this categorical distribution to training data just amounts to counting how often we observe each of the 256 values in the training set pixels, and normalizing by the total number of training set pixels. So, we know how to model one grayscale pixel. We can sample from this distribution to synthesize a random one-pixel image.
How do we model the distribution over a second grayscale pixel given the first? In fact, we already know how to model this; mathematically, we are just trying to model \(p(\mathbf{x_2} \bigm | \mathbf{x_1})\) where \(\mathbf{x_1}\) is the first pixel and \(\mathbf{x_2}\) is the second. Treating \(\mathbf{x}_2\) as a categorical variable (just like \(\mathbf{x_1}\)), we can simply use a softmax regression, which we saw in Section 9.7.3. In that section we were modeling a \(K\)-way categorical distribution over \(K\) object classes, conditioned on an input image. Now we can use exactly the same tools to model a \(256\)-way distribution over a the second pixel in a sequence conditioned on the first.
In this section we index the first pixel as \(\mathbf{x}_1\) rather than \(\mathbf{x}_0\).
What about the third pixel, conditioned on the first two? Well, this is again a problem of the same form: a 256-way softmax regression conditioned on some observations. Now you can see the induction: modeling each next pixel in the sequence is a softmax regression problem that models \(p(\mathbf{x}_n \bigm | \mathbf{x}_1, \ldots, \mathbf{x}_{n-1})\). We show how the cross-entropy loss can be computed in Figure 32.11. Notice that it looks almost identical to Figure 9.10 from Chapter 9.
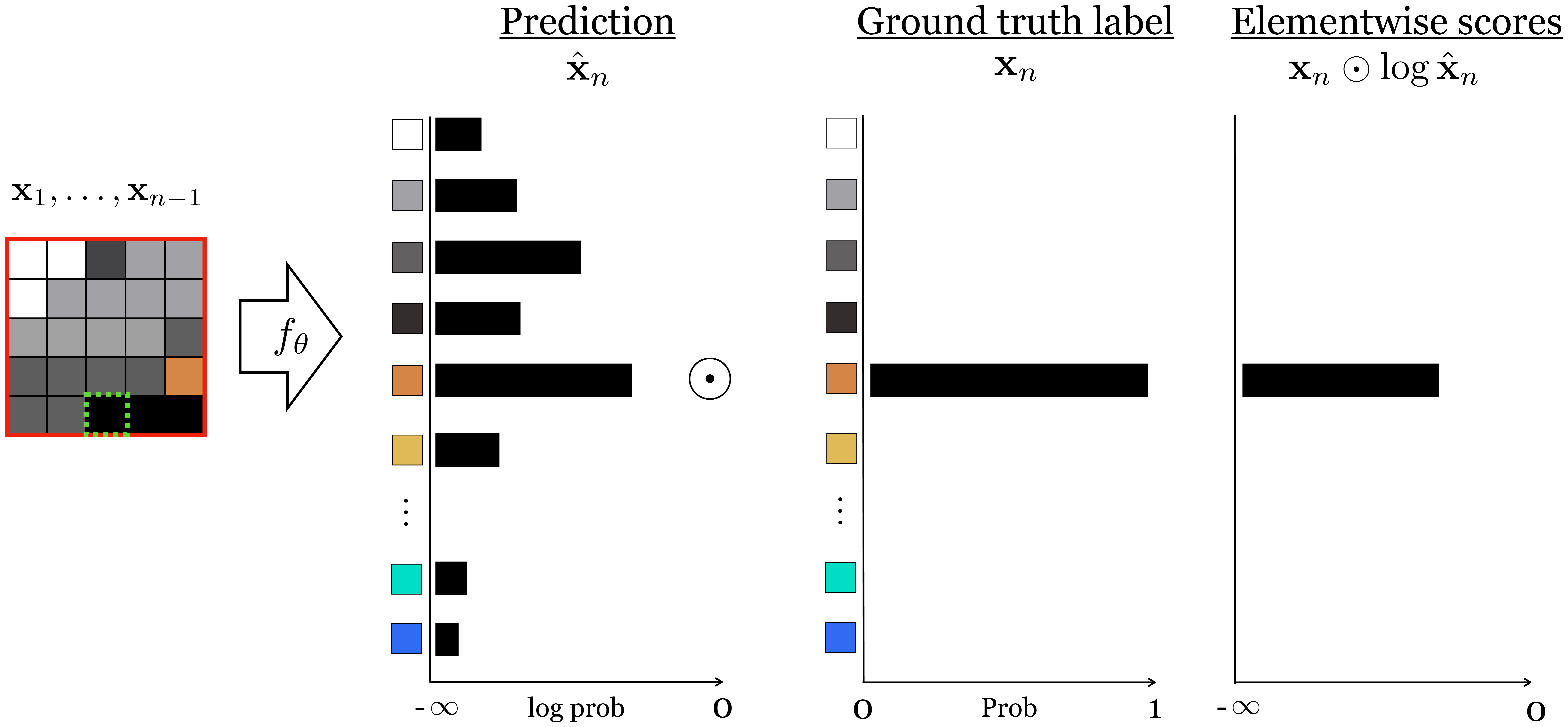
If we have color images we need to predict three values per-pixel, one for each of the red, green, and blue channels. One way to do this is to predict and sample the values for these three channels in sequence: first predict the red value as a 256-way classification problem, then sample the red value you will use, then predict the green value as a 256-way classification problem, and so on. You might be wondering, how do we turn an image into a sequence of pixels? Good question! There are innumerable ways, but the simplest is often good enough: just vectorize the two-dimensional (2D) grid of pixels by first listing the first row of pixels, then the second row, and so forth. In general, any fixed ordering of the pixels into a sequence is actually valid, but this simple method is perhaps the most common.
So we can model the probability of each subsequent pixel given the preceding pixels. To generate an image we can sample a value for the first pixel, then sample the second given the first, then the third given the first and second, and so forth. But is this a valid model of \(p(\mathbf{X}) = p(\mathbf{x}_0, \ldots, \mathbf{x}_n)\), the probability distribution of the full set of pixels? Does this way of sequential sampling draw a valid sample from \(p(\mathbf{X})\)? It turns out it does, according to the chain rule of probability. This rule allows us to factorize any joint distribution into a product of conditionals as follows:
\[\begin{aligned} p(\mathbf{X}) &= p(\mathbf{x_n} \bigm | \mathbf{x_1}, \ldots, \mathbf{x}_{n-1})p(\mathbf{x}_{n-1} \bigm | \mathbf{x}_1, \ldots, \mathbf{x}_{n-2}) \quad \ldots \quad p(\mathbf{x}_2 \bigm | \mathbf{x}_1)p(\mathbf{x}_1)\\ p(\mathbf{X}) &= \prod_{i=1}^n p(\mathbf{x}_i \bigm | \mathbf{x}_1, \ldots, \mathbf{x}_{i-1}) \end{aligned} \tag{32.5}\]
As a notational convenience, we define here that \(p(\mathbf{x}_i \\ | \mathbf{x}_1, \ldots, \mathbf{x}_{i-1}) = p(\mathbf{x}_1)\) when \(i=1\).
This factorization demonstrates that sampling from such a model can indeed be done in sequence because all the conditional distributions are independent of each other.
32.7.1 Training an Autoregressive Model
To train an autogressive a model, you just need to extract supervised pairs of desired input-output behavior, as usual. For an autoregressive model of pixels, that means extracting sequences of pixels \(\mathbf{x}_1, \ldots, \mathbf{x}_{n-1}\) and corresponding observed next pixel \(\mathbf{x}_n\). These can be extracted by traversing training images in raster order. The full training and testing setup looks like this (Figure 32.12):
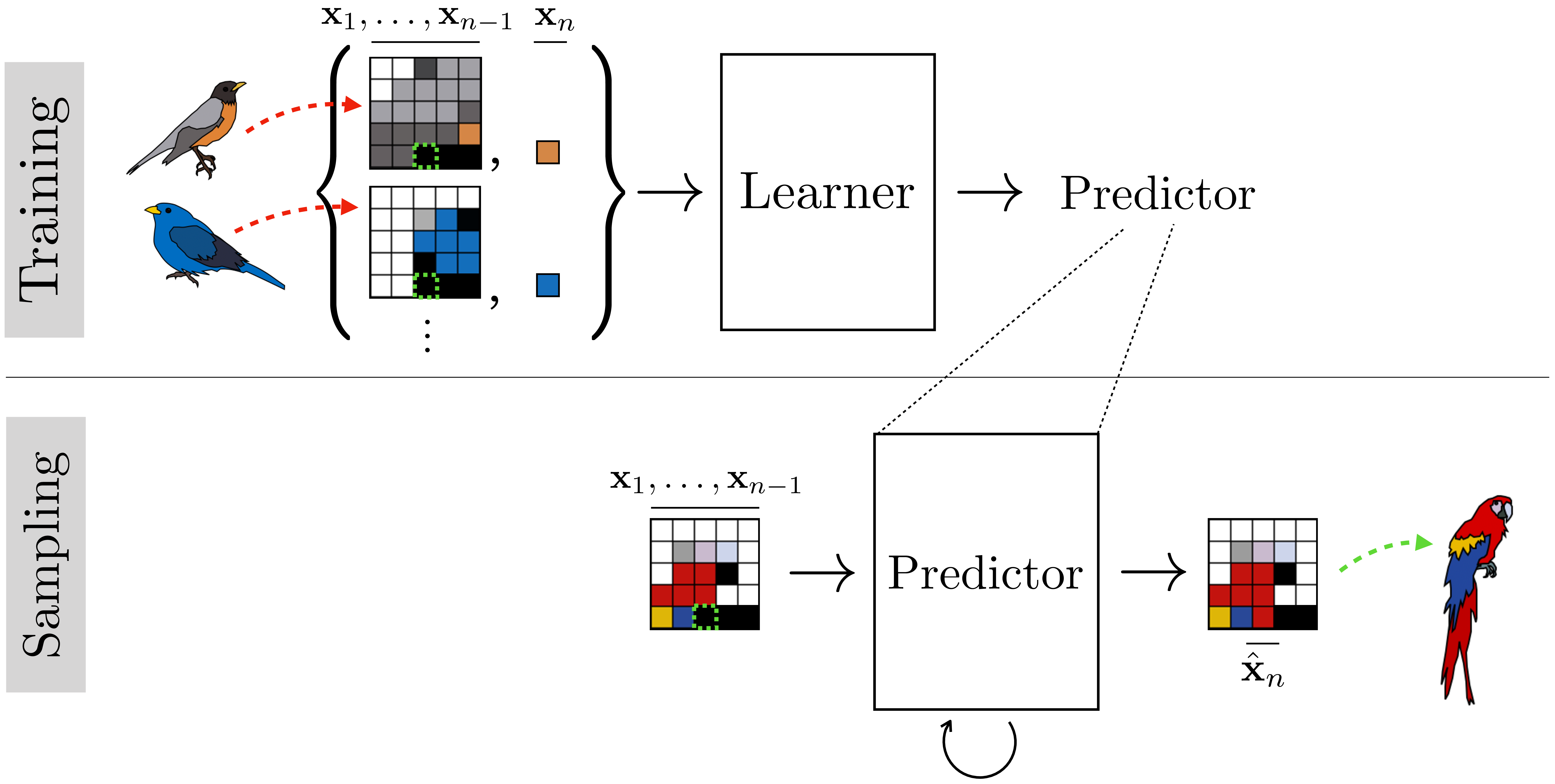
It’s worth noting here two different ways of setting up the training batches, one of which is much more efficient than the other. The first way is create a training batch that looks like this (we will call this a type 1 batch): \[\begin{aligned} &\texttt{input}: \mathbf{x}_k^{(i)}, \dots, \mathbf{x}_{k+n-1}^{(i)} \quad\quad \texttt{target output}: \mathbf{x}_{k+n}^{(i)}\\ &\texttt{input}: \mathbf{x}_l^{(j)}, \dots, \mathbf{x}_{l+n-1}^{(j)} \quad\quad \texttt{target output}: \mathbf{x}_{l+n}^{(j)}\\ &\ldots\nonumber \end{aligned}\] that is, we sample supervised examples ([sequence, completion] pairs) that each come from a different random starting location (indexed by \(k\) and \(l\)) in a different random image (indexed by \(i\) an \(j\)).
The other way to set up the batches is like this (we will call this a type 2 batch): \[\begin{aligned} &\texttt{input}: \mathbf{x}_1^{(i)}, \dots, \mathbf{x}_{n-1}^{(i)} \quad\quad \texttt{target output}: \mathbf{x}_n^{(i)}\\ &\texttt{input}: \mathbf{x}_2^{(i)}, \dots, \mathbf{x}_{n}^{(i)} \quad\quad \texttt{target output}: \mathbf{x}_{n+1}^{(i)}\\ &\ldots\nonumber \end{aligned}\] that is, the example sequences overlap. This second way can be much more efficient. The reason is because in order to predict \(\mathbf{x}_n\) from \(\mathbf{x}_1, \dots, \mathbf{x}_{n-1}\), we typically have to compute representations of \(\mathbf{x}_1, \dots, \mathbf{x}_{n-1}\), and these same representations can be reused for predicting the next item over, that is, \(\mathbf{x}_{n+1}\) from \(\mathbf{x}_2, \dots, \mathbf{x}_n\). As a concrete example, this is the case in transformers with causal attention Section 26.10, which have the property that the representation of item \(\mathbf{x}_{n}\) only depends on the items that preceded it in the sequence. What this allows us to do is share computation between all our overlapping predictions, and this is why it makes sense to use type 2 training batches. Notice these are the same kind of batches we described in the causal attention section (see Equation 26.11).
32.7.2 Sampling from Autoregressive Models
Autogressive models give us an explicit density function, Equation 32.5. To sample from this density we use , which is the process described previously, of sampling the first pixel from \(p(\mathbf{x}_1)\), then, conditioned on this pixel, sampling the second from \(p(\mathbf{x}_2 \bigm | \mathbf{x}_1)\) an so forth. Since each of these densities is a categorical distribution, sampling is easy: one option is to partition a unit line segment into regions of length equal to the categorical probabilities and see where a uniform random draw along this line falls. Autogressive models do not have latent variables \(\mathbf{z}\), which makes them incompatible with applications that involve extracting or manipulating latent variables.
32.8 Diffusion Models
The strategy of autoregressive models is to break a hard problem into lots of simple pieces. Diffusion models are another class of model that uses this same strategy [3]. They can be easy to understand if we start by looking at what autoregressive models do in the reverse direction: starting with a complete image, they remove one pixel, then the next, and the next (Figure 32.13):

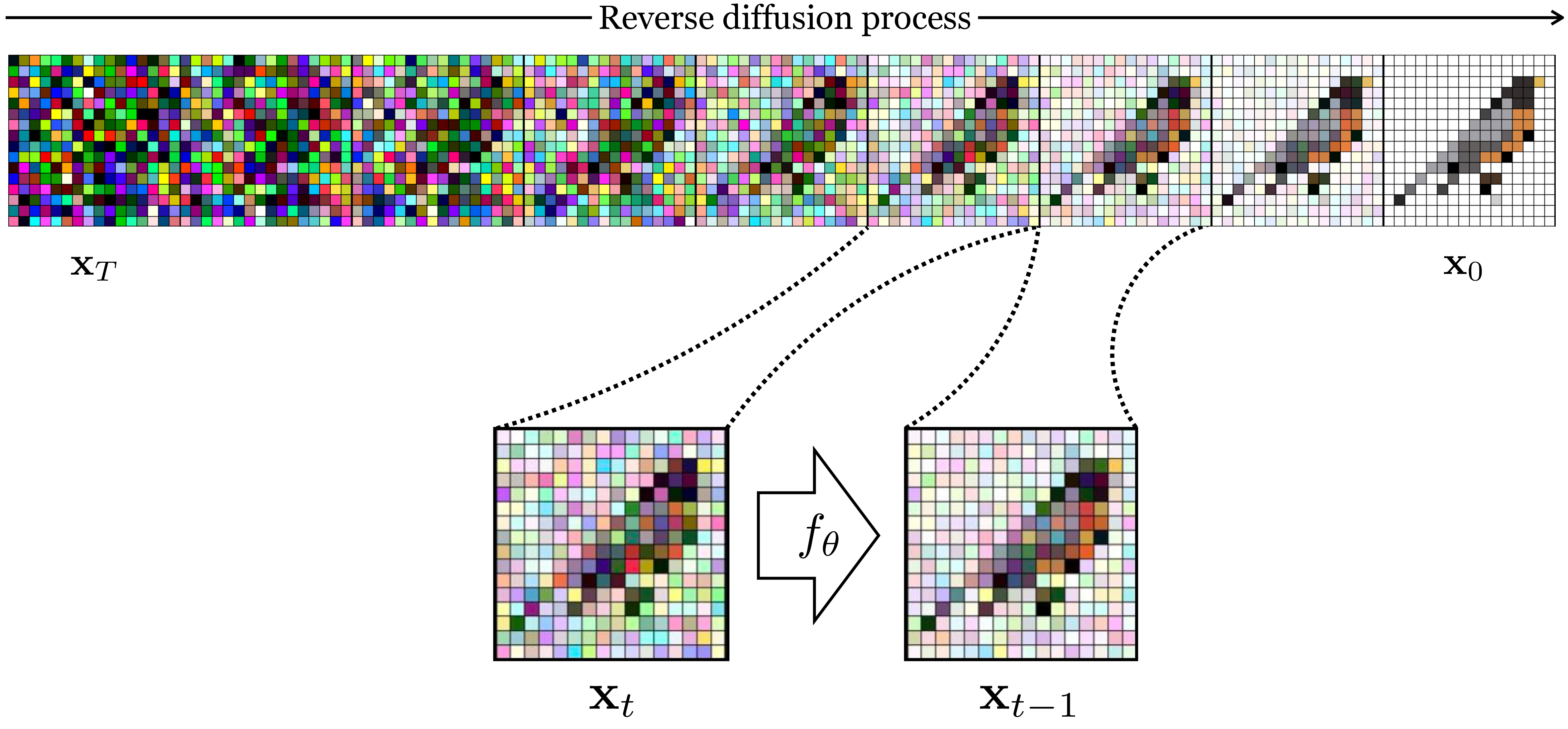
This is a signal corruption process. The idea of diffusion models is that this is not the only corruption process we could have used, and maybe not the best. Diffusion models instead use the following corruption process: starting with an uncorrupted image, \(\mathbf{x}_0\), they add noise \(\mathbf{\epsilon}_0\) to this image, resulting in a noisy version of the image, \(\mathbf{x}_1\). Then they repeat this process, adding noise \(\mathbf{\epsilon}_1\) to produce an even noisier signal \(\mathbf{x}_2\), and so on. Most commonly, the noise is isotropic Gaussian noise. Figure 32.14 shows what that looks like:

After \(T\) steps of this process, the image \(\mathbf{x}_T\) looks like pure noise, if \(T\) is large enough. In fact, if we use the following noise process, then \(\mathbf{x}_T \sim \mathcal{N}(\mathbf{0},\mathbf{I})\) as \(T \rightarrow \infty\) (which follows from equation 4 in [4]). \[\begin{aligned} \mathbf{x}_t &= \sqrt{(1-\beta_t)}\mathbf{x}_{t-1} + \sqrt{\beta_t}\mathbf{\epsilon}_t\\ \epsilon_t &\sim \mathcal{N}(\mathbf{0},\mathbf{I}) \end{aligned}\] The \(\beta_t\) values should be \(\leq 1\) and can be fixed for all \(t\) (like in the previous equations) or can be set according to some schedule that changes the amount of noise added over time.
Now, just like autoregressive models, diffusion models train a neural net, \(f_{\theta}\), to reverse this process. It can be trained via supervised learning on examples sequences of different images getting noisier and noisier. For example, as shown below in Figure 32.15, the sequence of images of the bird getting noisier and noisier can be flipped in time and thereby provide a sequence of training examples of the mapping \(\mathbf{x}_t \rightarrow \mathbf{x}_{t-1}\), and these examples can be fit by a predictor \(f_{\theta}\).
We call \(f_{\theta}\) a denoiser; it learns to remove a little bit of noise from an image. If we apply this denoiser over and over, starting with pure noise, the process should coalesce on a noise-less image that looks like one of our training examples. The steps to train a diffusion model are therefore as follows:
Generate training data by corrupting a bunch of images (forward process; noising).
Train a neural net to invert each step of corruption (reverse process; denoising).
As an additional trick, it can help to let the denoising function observe time step \(t\) as input, so that we have, \[\begin{aligned} \hat{\mathbf{x}}_{t-1} = f_{\theta}(\mathbf{x}_t, t) \end{aligned}\] This can help the denoiser to make better predictions, because knowing \(t\) helps us know if we are looking at a normal scene that has been corrupted by our noise (if \(t\) is large this is likely) or a scene where the actual physical structure is full of chaotic, rough textures that happen to look like noise (if \(t\) is small this is more likely, because for small \(t\) we haven’t added much noise to the scene yet). Algorithm 32.2 presents these steps in more formal detail.

In Algorithm 32.2 we train the denoiser using a loss \(\mathcal{L}\), which could be the \(L_2\) distance. In many diffusion models, \(f_{\theta}\) is instead trained to output the parameters (mean and variance) as a Gaussian density model fit to the data. This formulation yields useful probabilistic interpretations (in fact, such a diffusion model can be framed as a variational autoencoder, which we will see in Chapter 33). However, diffusion models can still work well without these nice interpretations, instead using a wide variety of prediction models for \(f_{\theta}\) [5].
One useful trick for training diffusion models is to reparameterize the learning problem as predicting the noise rather than the signal [4]: \[\begin{aligned} f_{\theta}(\mathbf{x}_t, t) &= \epsilon_t &\quad\quad \triangleleft \quad\text{first predict noise}\\ \hat{\mathbf{x}}_{t-1} &= \mathbf{x}_t + \epsilon_t &\quad\quad \triangleleft \quad\text{then remove this noise} \end{aligned}\]
One way to look at diffusion models is that we want to learn a mapping from pure noise (e.g., \(\mathbf{z} \sim \mathcal{N}(\mathbf{0},\mathbf{I})\)) to data. It is very hard to figure out how to create structured data out of noise, but it is easy to do the reverse, turning data into noise. So diffusion models turn images into noise in order to create the training sequences for a process that turns noise into data.
32.9 Generative Adversarial Networks
Autoregressive models and diffusion models sample simple distributions step by step to build up a complex distribution. Could we instead create a system that directly, in one step, outputs samples from the complex distribution. It turns out we can, and one model that does this is the generative adversarial network (GAN), which was introduced by [6].
Recall that the goal of generative modeling is to make synthetic data that looks like real data. We stated previously that there are many different ways to measure “looks like” and each leads to a different kind of generative model. GANs take a very direct and intuitive approach: synthetic data looks like real data if a classifier cannot distinguish between synthetic images and real images.
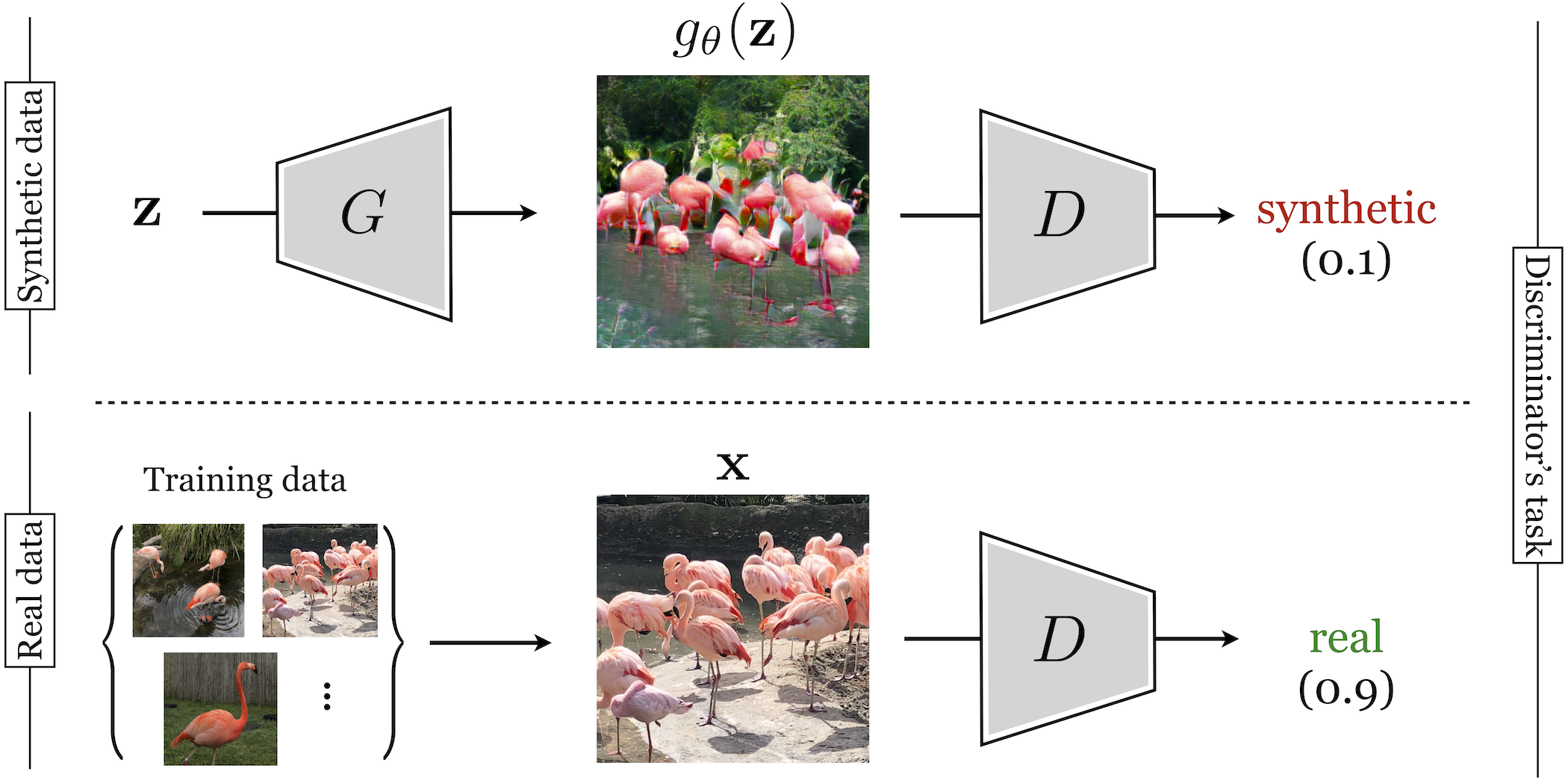
GANs consist of two neural networks, the generator, \(g_{\theta}: \mathcal{Z} \rightarrow \mathcal{X}\), which synthesizes data from noise, and a discriminator, \(d_{\phi}: \mathcal{X} \rightarrow \Delta^1\), which tries to classify between synthesized data and real data.
The \(g_{\theta}\) and \(d_{\phi}\) play an adversarial game in which \(g_{\theta}\) tries to become better and better at generating synthetic images while \(d_{\phi}\) tries to become better and better at detecting any errors \(g_{\theta}\) is making. The learning problem can be written as a minimax game: \[\begin{aligned} \mathop{\mathrm{arg\,min}}_\theta\max_\phi \mathbb{E}_{\mathbf{x} \sim p_{\texttt{data}}}[\log d_{\phi}(\mathbf{x})] + \mathbb{E}_{\mathbf{z} \sim p_{\mathbf{z}}}[\log (1-d_{\phi}(g_{\theta}(\mathbf{z})))] \end{aligned} \tag{32.6}\]
Schematically, the generator synthesizes images that are then fed as input to the discriminator. The discriminator tries to assign a low score to generated images (classifying them as synthetic) and a high score to real images from some training set (classifying them as real), as shown in Figure 32.16.
Although we call this an adversarial game, the discriminator is in fact helping the generator to perform better and better, by pointing out its current errors (we call it an adversary because it tries to point out errors). You can think of the generator as a student taking a painting class and the discriminator as the teacher. The student is trying to produce new paintings that match the quality and style of the teacher. At first the student paints flat landscapes that lack shading and the illusion of depth; the teacher gives feedback: “This mountain is not well shaded; it looks 2D.” So the student improves and corrects the error, adding haze and shadows to the mountain. The teacher is pleased but now points out a different error: “The trees all look identical; there is not enough variety.” The teacher and student continue on in this fashion until the student has succeeded at satisfying the teacher. Eventually, in theory, the student—the generator—produces paintings that are just as good as the teacher’s paintings.
This objective may be easier to understand if we think of the objectives for \(g_{\theta}\) and \(d_{\phi}\) separately. Given a particular generator \(g_{\theta}\), \(d_{\phi}\) tries to maximize its ability to discriminate between real and synthetic images (synthetic images are anything output by \(g_{\theta}\)). The objective of \(d_{\phi}\) is logistic regression between a set of real data \(\{\mathbf{x}^{(i)}\}_{i=1}^N\) and synthetic data \(\{\hat{\mathbf{x}}^{(i)}\}_{i=1}^N\), where \(\hat{\mathbf{x}}^{(i)} = g_{\theta}(\mathbf{z}^{(i)})\).
Let the optimal discriminator be labeled \(d_{\phi}^*\). Then we have, \[\begin{aligned} d_{\phi}^* = \mathop{\mathrm{arg\,max}}_{\phi} \mathbb{E}_{\mathbf{x} \sim p_{\texttt{data}}}[\log d_{\phi}(\mathbf{x})] + \mathbb{E}_{\mathbf{z} \sim p_{\mathbf{z}}}[\log (1-d_{\phi}(g_{\theta}(\mathbf{z})))] \end{aligned} \tag{32.7}\]
Now we turn to \(g_{\theta}\)’s perspective. Given \(d_{\phi}^*\), \(g_{\theta}\) tries to solve the following problem: \[\begin{aligned} \mathop{\mathrm{arg\,min}}_{\theta} \mathbb{E}_{\mathbf{z} \sim p_{\mathbf{z}}}[\log (1-d_{\phi}^*(g_{\theta}(\mathbf{z})))] \end{aligned} \tag{32.8}\]
Now, because the optimal discriminator \(d_{\phi}^*\) depends on the current behavior of \(g_{\theta}\), as soon as we change \(g_{\theta}\), updating it to better fool \(d_{\phi}^*\), then \(d_{\phi}^*\) no longer is the optimal discriminator and we need to again solve problem in Equation 32.7. To optimize a GAN, we simply alternate between taking one gradient step on the objective in Equation 32.8 and then \(K\) gradient steps on the objective in Equation 32.7, where the larger the \(K\), the closer we are to approximating the true \(d_{\theta}^*\). In practice, setting \(K=1\) is often sufficient.
32.9.1 GANs are Statistical Image Models
GANs are related to the image and texture models we saw in Chapter 27. For example, in the Heeger-Bergen model (Section 28.3 [8]), we synthesize images with the same statistics as a source texture. This can be phrased as an optimization problem in which we optimize image pixels until certain statistics of the images match those same statistics measured on a source (training) image. In the Heeger-Bergen model the objective is to match subband histograms. In the language of GANs, the loss that checks for such a match is a kind of discriminator; it outputs a score related to the difference between a generated image’s statistics and the real image’s statistics. However, unlike a GAN, this discriminator is hand-defined in terms of certain statistics of interest rather than learned. Additionally, GANs amortize the optimization via learning. That is, GANs learn a mapping \(g_{\theta}\) from latent noise to samples rather than arriving at samples via an optimization process that starts from scratch each time we want to make a new sample.
32.10 Concluding Remarks
Generative models are models that synthesize data. They can be useful for content creation—artistic images, video game assets, and so on—but also are useful for much more. In the next chapters we will see that generative models also learn good image representations, and conditional generative models can be viewed as a general framework for answering questions and making predictions. As Richard Feynman famously wrote, “What I cannot create, I do not understand.” By modeling creation, generative models also help us understand the visual world around us.
https://en.wikiquote.org/wiki/Richard_Feynman