9 Introduction to Learning
9.1 Introduction
The goal of learning is to extract lessons from past experience in order to solve future problems. Typically, this involves searching for an algorithm that solves past instances of the problem. This algorithm can then be applied to future instances of the problem.
Past and future do not necessarily refer to the calendar date; instead they refer to what the has previously seen and what the learner will see next.
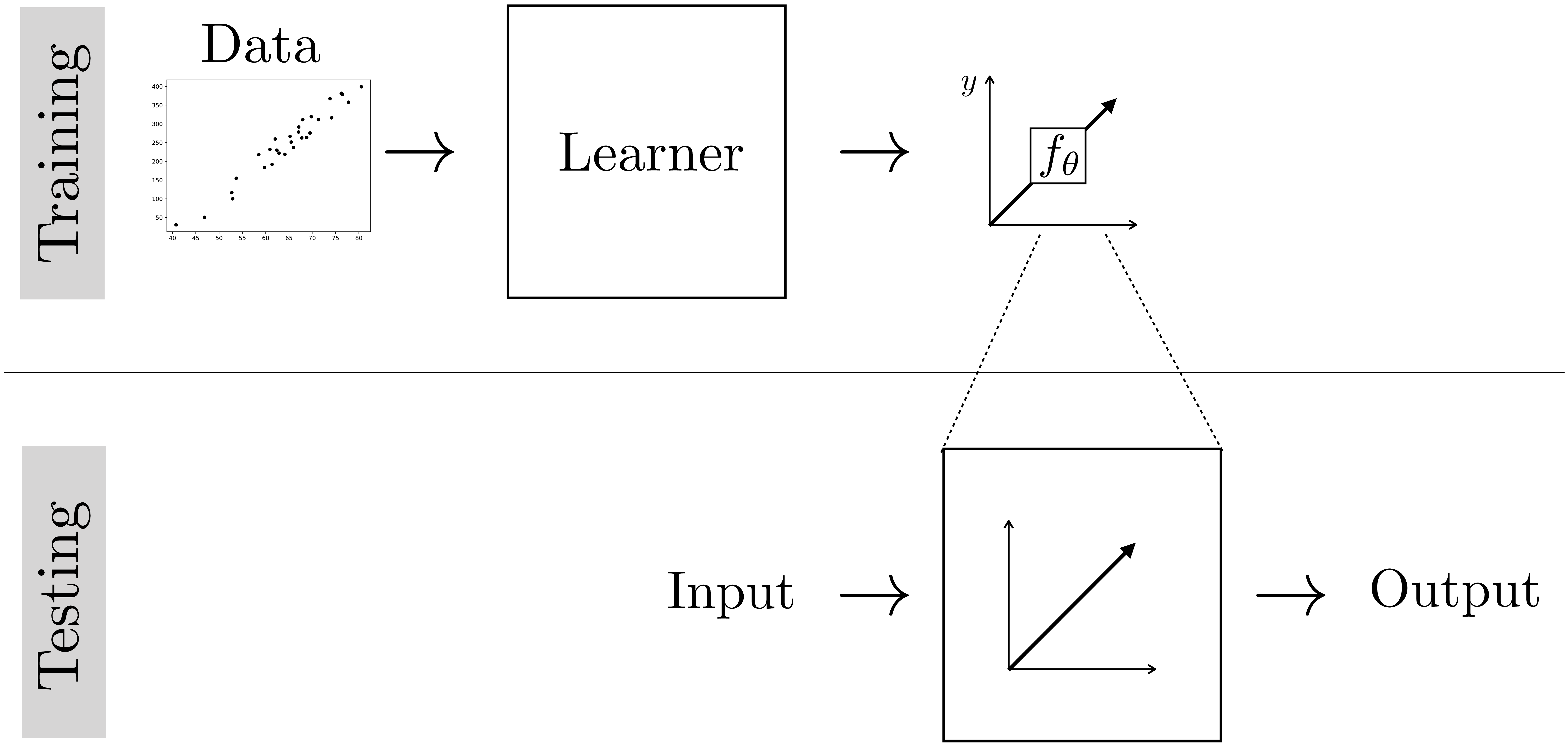
Because learning is itself an algorithm, it can be understood as a meta-algorithm: an algorithm that outputs algorithms (Figure 9.1).
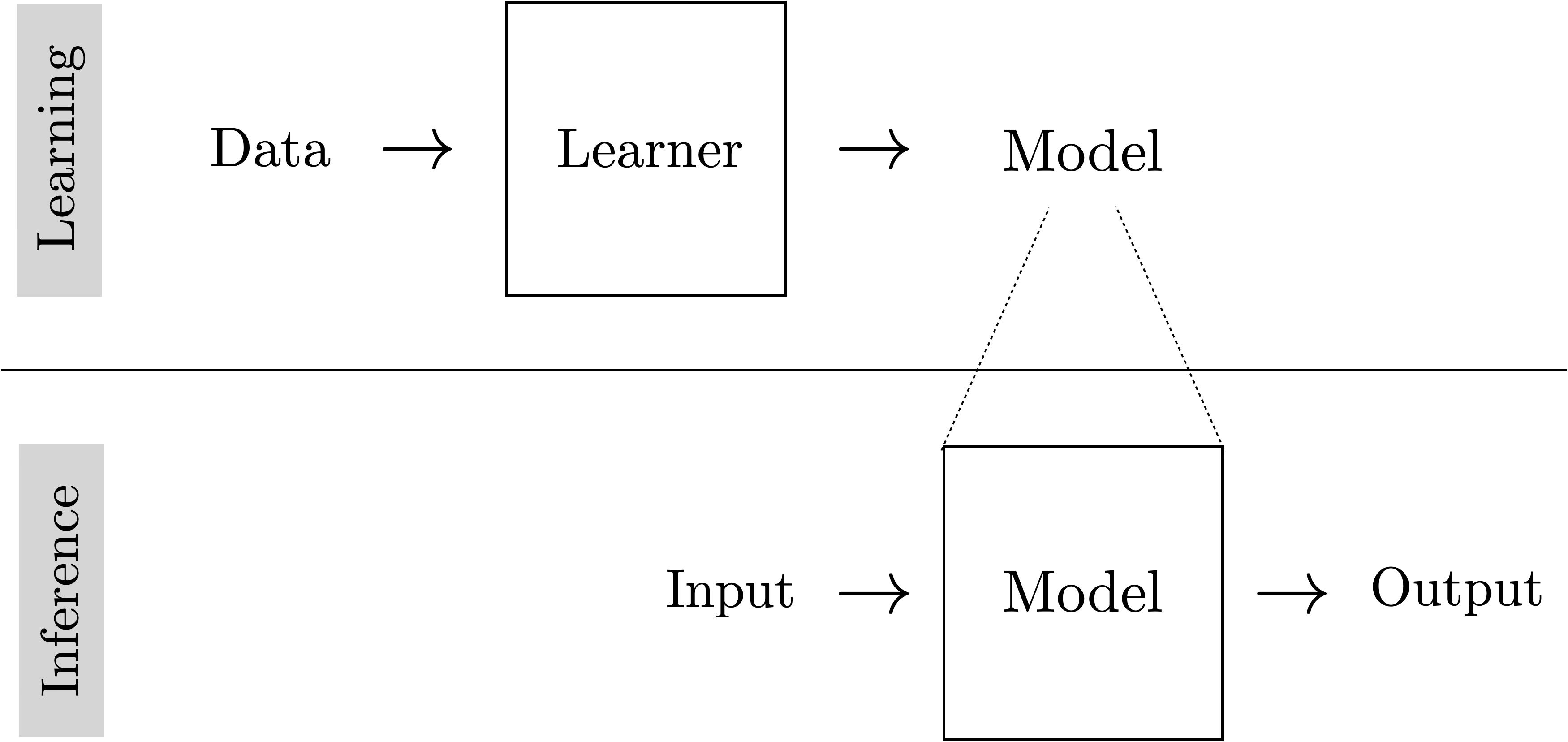
Learning usually consists of two phases: the training phase, where we search for an algorithm that performs well on past instances of the problem (training data), and the testing phase, where we deploy our learned algorithm to solve new instances of the problem.
9.2 Learning from Examples
Learning from examples is also called supervised learning.
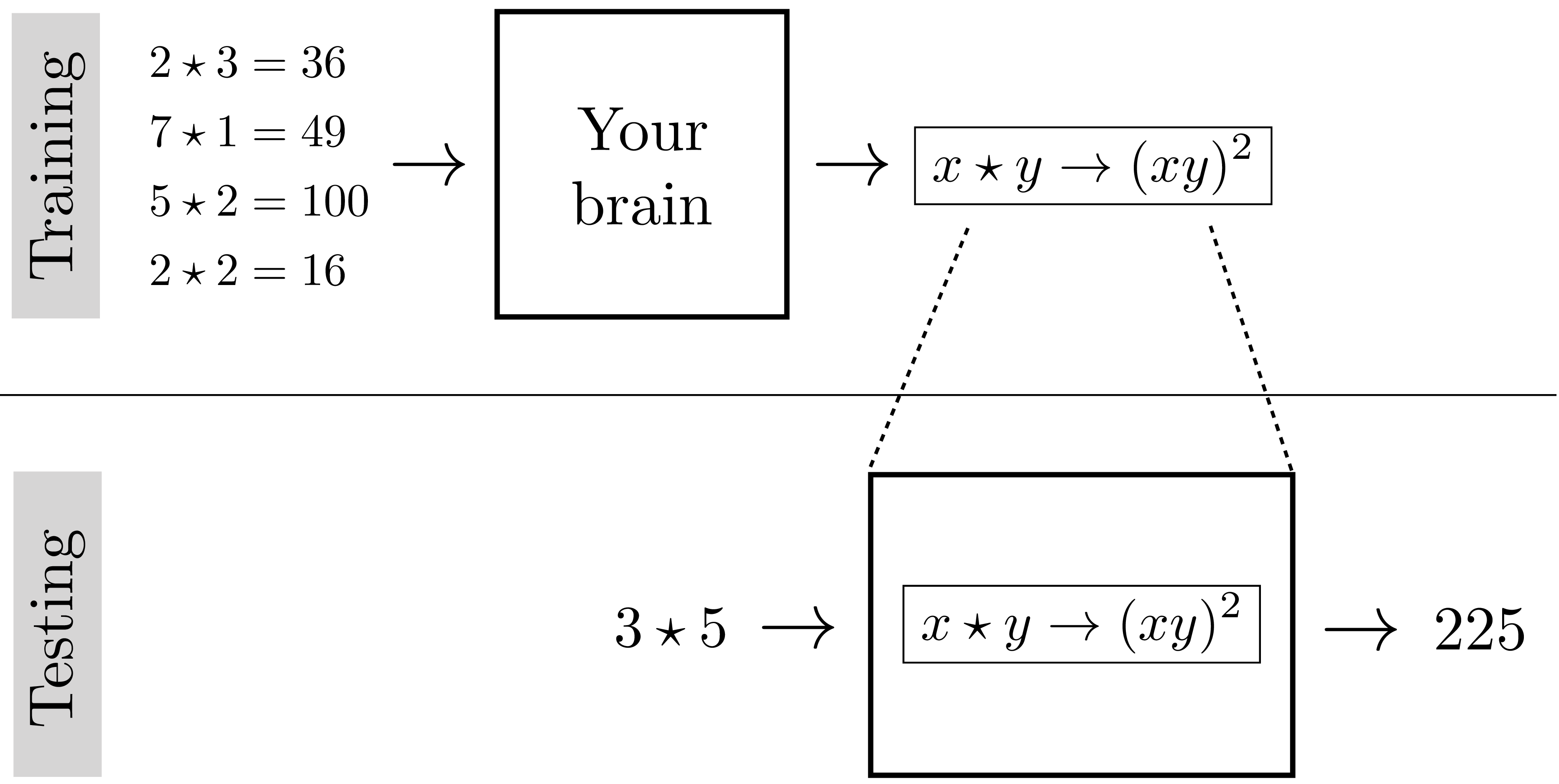
Imagine you find an ancient mathematics text, with marvelous looking proofs, but there is a symbol you do not recognize, “\(\star\)". You see it being used here and there in equations, and you note down examples of its behavior: \[\begin{aligned} 2 \star 3 &= 36\nonumber \\ 7 \star 1 &= 49\nonumber \\ 5 \star 2 &= 100\nonumber \\ 2 \star 2 &= 16\nonumber \end{aligned} \]
What do you think \(\star\) represents? What function is it computing? Do you have it? Let’s test your answer: what is the value of \(3 \star 5\)? (The answer is in the figure below.)
It may not seem like it, but you just performed learning! You learned what \(\star\) does by looking at examples. In fact, Figure 9.2 shows what you did:
Nice job!
It turns out, we can learn almost anything from examples.
Some things are not learnable from examples, such as noncomputable functions. An example of a noncomputable function is a function that takes as input a program and outputs a 1 if the program will eventually finish running, and a 0 if it will run forever. It is noncomputable because there is no algorithm that can solve this task in finite time. However, it might be possible to learn a good approximation to it.
Remember that we are learning an algorithm, i.e., a computable mapping from inputs to outputs. A formal definition of example, in this context, is an {input, output} pair. The examples you were given for \(\star\) consisted of four such pairs:
\[\begin{aligned} &\{\texttt{input:} [2,3], \texttt{output:} 36\}\nonumber \\ &\{\texttt{input:} [7,1], \texttt{output:} 49\}\nonumber \\ &\{\texttt{input:} [5,2], \texttt{output:} 100\}\nonumber \\ &\{\texttt{input:} [2,2], \texttt{output:}16\}\nonumber \end{aligned}\]
This kind of learning, where you observe example input-output behavior and infer a functional mapping that explains this behavior, is called supervised learning.
Another name for this kind of learning is fitting a model to data.
We were able to model the behavior of \(\star\), on the examples we were given, with a simple algebraic equation. Let’s try something rather more complicated. From the three examples in Figure 9.3, can you figure out what the operator \(F\) does?
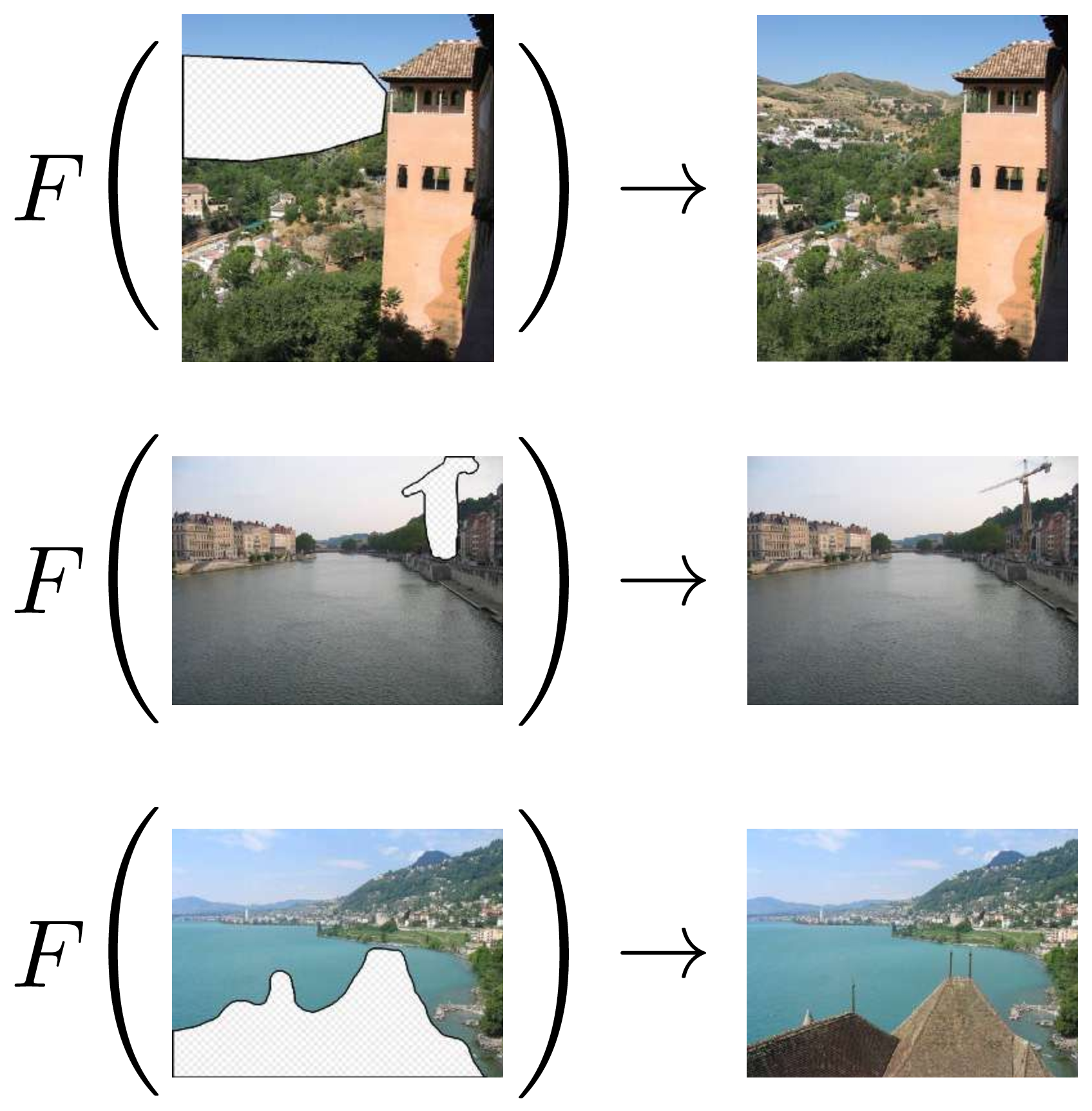
You probably came up with something like “it fills in the missing pixels.” That’s exactly right, but it’s sweeping a lot of details under the rug. Remember, we want to learn an algorithm, a procedure that is completely unambiguous. How exactly does \(F\) fill in the missing pixels?
It’s hard to say in words. We may need a very complex algorithm to specify the answer, an algorithm so complex that we could never hope to write it out by hand. This is the point of machine learning. The machine writes the algorithm for us, but it can only do so if we give it many examples, not just these three.
9.3 Learning without Examples
Even without examples, we can still learn. Instead of matching input-output examples, we can try to come up with an algorithm that optimizes for desirable properties of the input-output mapping. This class of learners includes unsupervised learning and reinforcement learning.
In unsupervised learning, we are given examples of input data \(\{x^{(i)}\}^N_{i=1}\) but we are not told the target outputs \(\{y^{(i)}\}^N_{i=1}\). Instead the learner has to come up with a model or representation of the input data that has useful properties, as measured by some objective function. The objective could be, for example, to compress the data into a lower dimensional format that still preserves all information about the inputs. We will encounter this kind of learning in part Chapter 33 of this book, on representation learning and generative modeling.
In reinforcement learning, we suppose that we are given a reward function that explicitly measures the quality of the learned function’s output. To be precise, a reward function is a mapping from outputs to scores: \(r: \mathcal{Y} \rightarrow \mathbb{R}\). The learner tries to come up with a function that maximizes rewards. This book will not cover reinforcement learning in detail, but this kind of learning is becoming an important part of computer vision, especially in the context of vision for robots. We direct the interested reader to [2] to learn more.
At first glance unsupervised learning and reinforcement learning look similar: both maximize a function that scores desirable properties of the input-output mapping. The big difference is that unsupervised learning has access to training data whereas reinforcement learning usually does not; instead the reinforcement learner has to collect its own training data.
9.4 Key Ingredients
A learning algorithm consists of three key ingredients:
: What does it mean for the learner to succeed, or, at least, to perform well?
: What is the set of possible mappings from inputs to outputs that we will we search over?
: How, exactly, do we search the hypothesis space for a specific mapping that maximizes the objective?
These three ingredients, when applied to large amounts of data, and run on sufficient hardware (referred to as compute) can do amazing things. We will focus on the learning algorithms in this chapter, but often the data and compute turn out to be more important.

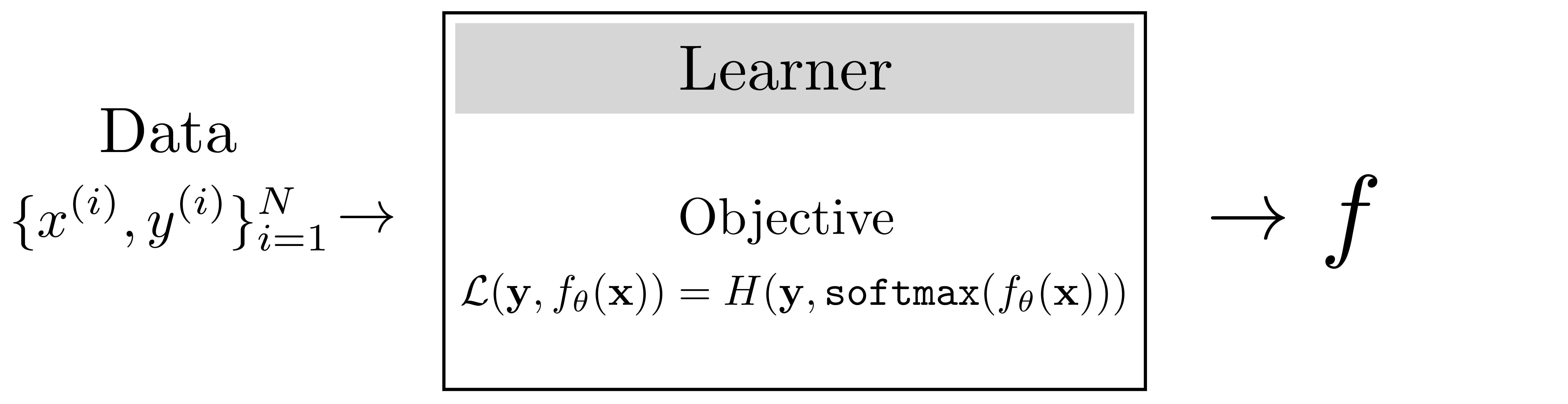
A learner outputs an algorithm, \(f: \mathcal{X} \rightarrow \mathcal{Y}\), which maps inputs, \(\mathbf{x} \in \mathcal{X}\), to outputs, \(\mathbf{y} \in \mathcal{Y}\). Commonly, \(f\) is referred to as the learned function. The objective that the learner optimizes is typically a function that scores model outputs, \(\mathcal{L}: \mathcal{Y} \rightarrow \mathbb{R}\), or compares model outputs to target answers, \(\mathcal{L}: \mathcal{Y} \times \mathcal{Y} \rightarrow \mathbb{R}\). We will interchangeably call this \(\mathcal{L}\) either the objective function, the loss function, or the loss. A loss almost always refers to an objective we seek to minimize, whereas an objective function can be used to describe objectives we seek to minimize as well as those we seek to maximize.
9.4.1 Importance of Parameterization
The hypothesis space can be described by a set \(\mathcal{F}\) of all the possible functions under consideration by the learner. For example, one hypothesis space might be “all mappings from \(\mathbb{R}^2 \rightarrow \mathbb{R}\)” and another could be “all functions \(\mathbb{R} \times \mathbb{R} \rightarrow \mathbb{R}_{\geq 0}\) that satisfy the conditions of being a distance metric.” Commonly, however, we will not just specify the hypothesis space, but also how we parameterize the space. For example, we may say that our parameterized hypothesis space is \(y = \theta_1 x + \theta_0\), where \(\theta_0\) and \(\theta_1\) are the parameters. This example corresponds to the space of affine functions from \(\mathbb{R} \rightarrow \mathbb{R}\), but this is not the only way to parameterize that space. Another choice could be \(y = \theta_2\theta_1 x + \theta_0\), with parameters \(\theta_0\), \(\theta_1\), and \(\theta_2\). These two choices parameterize exactly the same space, that is, any affine functions can be represented by either parameterization and both parameterizations can only represent affine functions. However, these two parameterizations are not equivalent, because optimizers and objectives may treat different parameterizations differently. Because of this, to fully define a learning algorithm, it is important to specify how the hypothesis space is parameterized.
Overparameterized models, where you use more parameters than the minimum necessary to fit the data, are especially important in modern computer vision; most neural networks Chapter 12 are overparameterized.
9.5 Empirical Risk Minimization: A Formalization of Learning from Examples
The three ingredients from the last section can be formalized using the framework of (ERM). This framework applies specifically to the supervised setting where we are learning a function that predicts \(\mathbf{y}\) from \(\mathbf{x}\) given many training examples \(\{\mathbf{x}^{(i)},\mathbf{y}^{(i)}\}^N_{i=1}\). The idea is to minimize the average error (i.e., risk) we incur over all the training data (i.e., empirical distribution). The ERM problem is stated as follows:
\[ \begin{aligned} \mathop{\mathrm{arg\,min}}_{f \in \mathcal{F}} \frac{1}{N} \sum_{i=1}^N \mathcal{L}(f(\mathbf{x}^{(i)}),\mathbf{y}^{(i)}) \quad\triangleleft\quad \text{ERM} \end{aligned} \]
Here, \(\mathcal{F}\) is the hypothesis space, \(\mathcal{L}\) is the loss function, and \(\{\mathbf{x}^{(i)}, \mathbf{y}^{(i)}\}_{i=1}^N\) is the training data (example {input, output} pairs), and \(f\) is the learned function.
9.6 Learning as Probabilistic Inference
Depending on the loss function, there is often an interpretation of ERM as doing maximum likelihood probabilistic inference. In this interpretation, we are trying to infer the hypothesis \(f\) that assigns the highest probability to the data. For a model that predicts \(\mathbf{y}\) given \(\mathbf{x}\), the max likelihood \(f\) is:
\[\begin{aligned} \mathop{\mathrm{arg\,max}}_f p\big(\{\mathbf{y}^{(i)}\}_{i=1}^N \bigm | \{\mathbf{x}^{(i)}\}_{i=1}^N, f\big) \quad\quad \triangleleft \quad\text{Max likelihood learning} \end{aligned} \]
The term \(p\big(\{\mathbf{y}^{(i)}\}_{i=1}^N \bigm | \{\mathbf{x}^{(i)}\}_{i=1}^N, f\big)\) is called the likelihood of the \(\mathbf{y}\) values given the model \(f\) and the observed \(\mathbf{x}\) values, and maximizing this quantity is called maximum likelihood learning.
To fully specify this model, we have to define the form of this conditional distribution. One common choice is that the prediction errors, \((\mathbf{y} - f(\mathbf{x}))\), are Gaussian distributed, which leads to the least-squares objective Section 9.7.1.
In later chapters we will see that priors \(p(f)\) can also be used for inferring the most probable hypothesis. When a prior is used in conjunction with a likelihood function, we arrive at maximum a posteriori learning (MAP learning), which infers the most probable hypothesis given the training data:
\[\begin{aligned} &\mathop{\mathrm{arg\,max}}_f p\big(f \bigm | \{\mathbf{x}^{(i)}, \mathbf{y}^{(i)}\}_{i=1}^N\big) \quad\quad \triangleleft \quad \text{MAP learning}\\ & = \mathop{\mathrm{arg\,max}}_f p\big(\{\mathbf{y}^{(i)}\}_{i=1}^N \bigm | \{\mathbf{x}^{(i)}\}_{i=1}^N, f\big)p\big(f\big) \quad\quad \triangleleft \quad \text{by Bayes' rule} \end{aligned}\]
9.7 Case Studies
The next three sections cover several case studies of particular learning problems. Examples 1 and 3 showcase the two most common workhorses of machine learning: regression and classification. Example 2, Python program induction, demonstrates that the paradigms in this chapter are not limited to simple systems but can actually apply to very general and sophisticated models.
9.7.1 Example 1: Linear Least-Squares Regression
One of the simplest learning problems is known as linear least-squares regression. In this setting, we aim to model the relationship between two variables, \(x\) and \(y\), with a line.
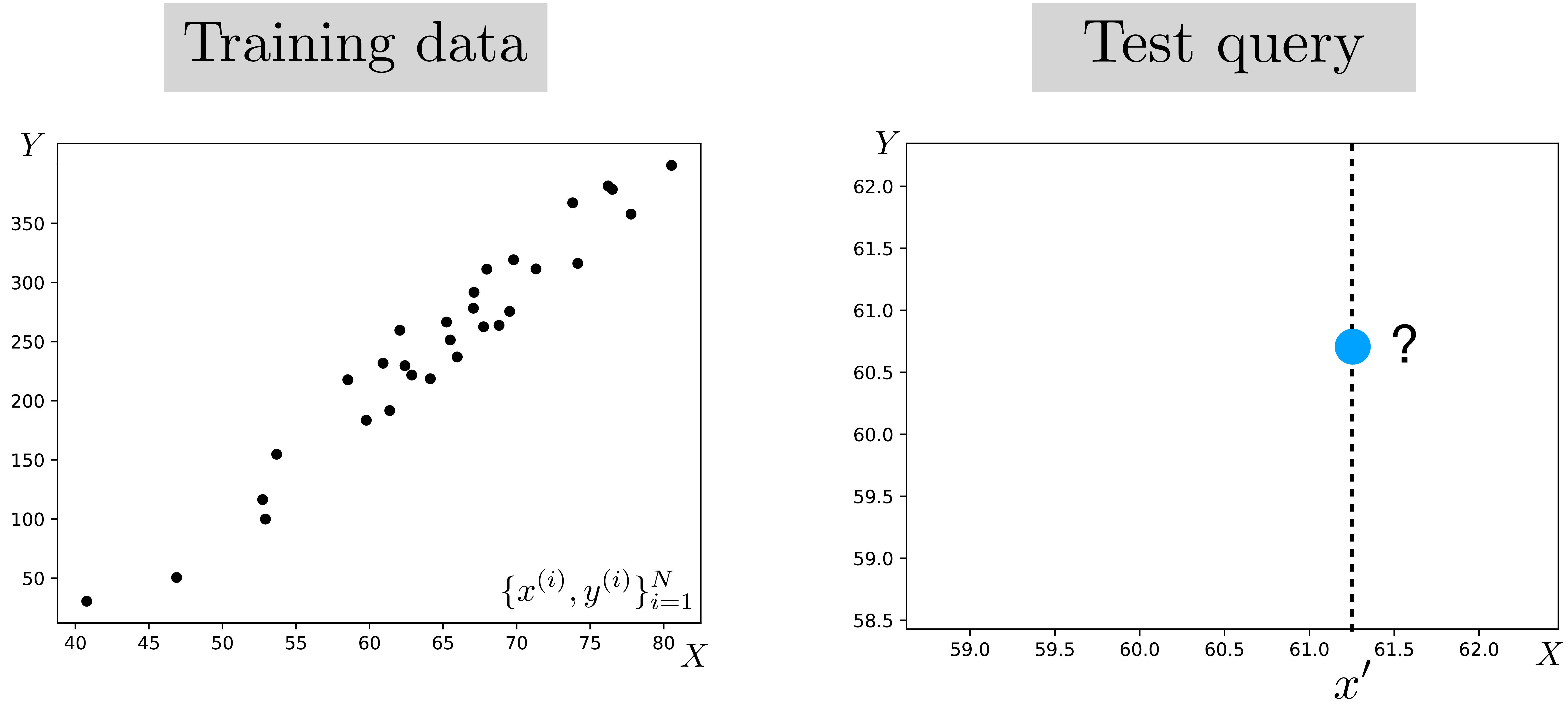
As a concrete example, let’s imagine \(x\) represents the temperature outside, and \(y\) represents the number people at the beach. As before, we train (i.e., fit) our model on many observed examples of {temperature outside, number of people at the beach} pairs, denoted as \(\{x^{(i)},y^{(i)}\}_{i=1}^N\). At test time, this model can be applied to predict the \(y\) value of a new query \(x'\), as shown in Figure 9.4.
Our hypothesis space is linear functions, that is, the relationship between \(x\) and our predictions \(\hat{y}\) of \(y\) has the form \(\hat{y} = f_{\theta}(x) = \theta_1 x + \theta_0\). This hypothesis space is parameterized by a two scalars, \(\theta_0, \theta_1 \in \mathbb{R}\), the intercept and slope of the line. In this book, we will use \(\theta\) in general to refer to any parameters that are being learned. In this case we have \(\theta = [\theta_0, \theta_1]\). Learning consists of finding the value of these parameters that maximizes the objective.
Our objective is that predictions should be near ground truth targets in a least-squares sense, that is, \((\hat{y}^{(i)} - y^{(i)})^2\) should be small for all training examples \(\{x^{(i)}, y^{(i)}\}_{i=1}^N\). We call this objective the \(L_2\) loss:
\[\begin{aligned} J(\theta) &= \sum_i \mathcal{L}(\hat{y}^{(i)}, y^{(i)})\\ &\quad \mathcal{L}(\hat{y}, y) = (\hat{y} - y)^2 \quad\quad \triangleleft \quad L_2 \text{ loss} \end{aligned}\]
We will use \(J(\theta)\) to denote the total objective, over all training datapoints, as a function of the parameters; we will use \(\mathcal{L}\) to denote the loss per datapoint. That is, \(J(\theta) = \sum_{i=1}^N \mathcal{L}(f_{\theta}(x^{(i)}), y^{(i)})\).
The full learning problem is as follows: \[\begin{aligned} \theta^* = \mathop{\mathrm{arg\,min}}_{\theta} \sum_{i=1}^N (\theta_1 x^{(i)} + \theta_0 - y^{(i)})^2. \end{aligned} \]
We can choose any number of optimizers to solve this problem. A first idea might be “try a bunch of random values for \(\theta\) and return the one that maximizes the objective.” In fact, this simple approach works, it just can be rather slow since we are searching for good solutions blind. A better idea can be to exploit structure in the search problem. For the linear least-squares problem, the tools of calculus give us clean mathematical structure that makes solving the optimization problem easy, as we show next.
From calculus, we know that at any maxima or minima of a function, \(J(\theta)\), with respect to a variable \(\theta\), the derivative \(\frac{\partial{J(\theta)}}{\partial{\theta}} = 0\). We are trying to find the minimum of the objective \(J(\theta)\):
\[\begin{aligned} J(\theta) = \sum_{i=1}^N (\theta_1 x^{(i)} + \theta_0 - y^{(i)})^2. \end{aligned}\]
This function can be rewritten as \[\begin{aligned} J(\theta) = (\mathbf{y} - \mathbf{X}\theta)^\mathsf{T}(\mathbf{y} - \mathbf{X}\theta) \end{aligned} \] with \[\begin{aligned} \mathbf{X} = \begin{bmatrix} 1 & x^{(1)} \\ 1 & x^{(2)} \\ \vdots & \vdots \\ 1 & x^{(N)} \end{bmatrix} \quad \mathbf{y} = \begin{bmatrix} y^{(1)} \\ y^{(2)} \\ \vdots \\ y^{(N)} \end{bmatrix} \quad \theta = \begin{bmatrix} \theta_0 \\ \theta_1 \end{bmatrix}. \end{aligned}\]
The \(J\) is a quadratic form, which has a single global minimum where the derivative is zero, and no other points where the derivative is zero. Therefore, we can solve for the \(\theta^*\) that minimizes \(J\) by finding the point where the derivative is zero. The derivative is: \[\begin{aligned} \frac{\partial J(\theta)}{\partial \theta} = 2(\mathbf{X}^\mathsf{T}\mathbf{X} \theta - \mathbf{X}^\mathsf{T}\mathbf{y}). \end{aligned} \]
We set this derivative to zero and solve for \(\theta^*\): \[ \begin{aligned} 2(\mathbf{X}^\mathsf{T}\mathbf{X} \theta^* - \mathbf{X}^\mathsf{T}\mathbf{y}) &= 0\\ \mathbf{X}^\mathsf{T}\mathbf{X} \theta^* &= \mathbf{X}^\mathsf{T}\mathbf{y}\\ \theta^* &= (\mathbf{X}^\mathsf{T}\mathbf{X})^{-1}\mathbf{X}^\mathsf{T}\mathbf{y}. \end{aligned} \]
The \(\theta^*\) defines the best fitting line to our data, and this line can be used to predict the \(y\) value of future observations of \(x\) (Figure 9.5).
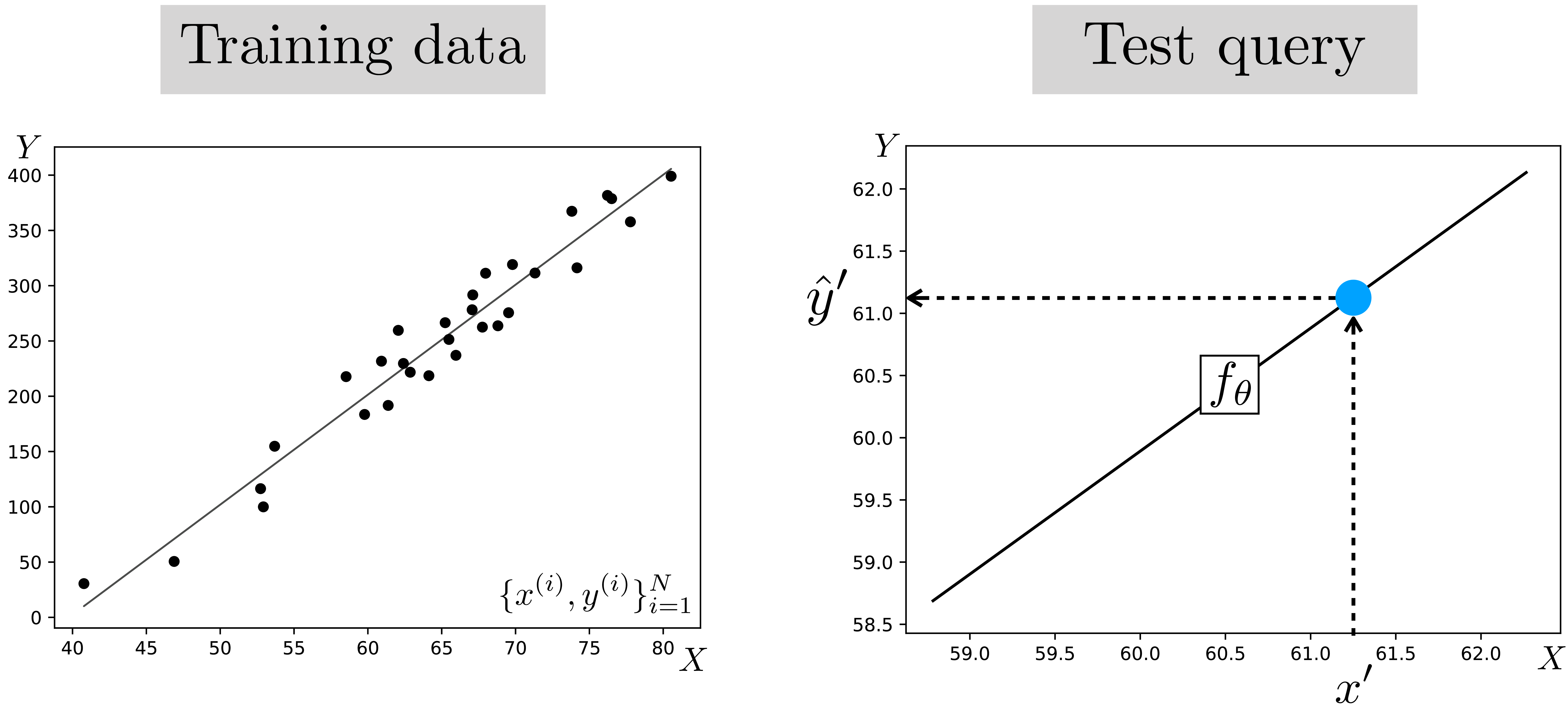
We can now summarize the entire linear least-squares learning problem as follows:

In these diagrams, we will sometimes describe the objective just in terms of \(\mathcal{L}\), in which case it should be understood that this implies \(J(\theta) = \sum_{i=1}^N \mathcal{L}(f_{\theta}(x^{(i)}), y^{(i)})\).
9.7.2 Example 2: Program Induction
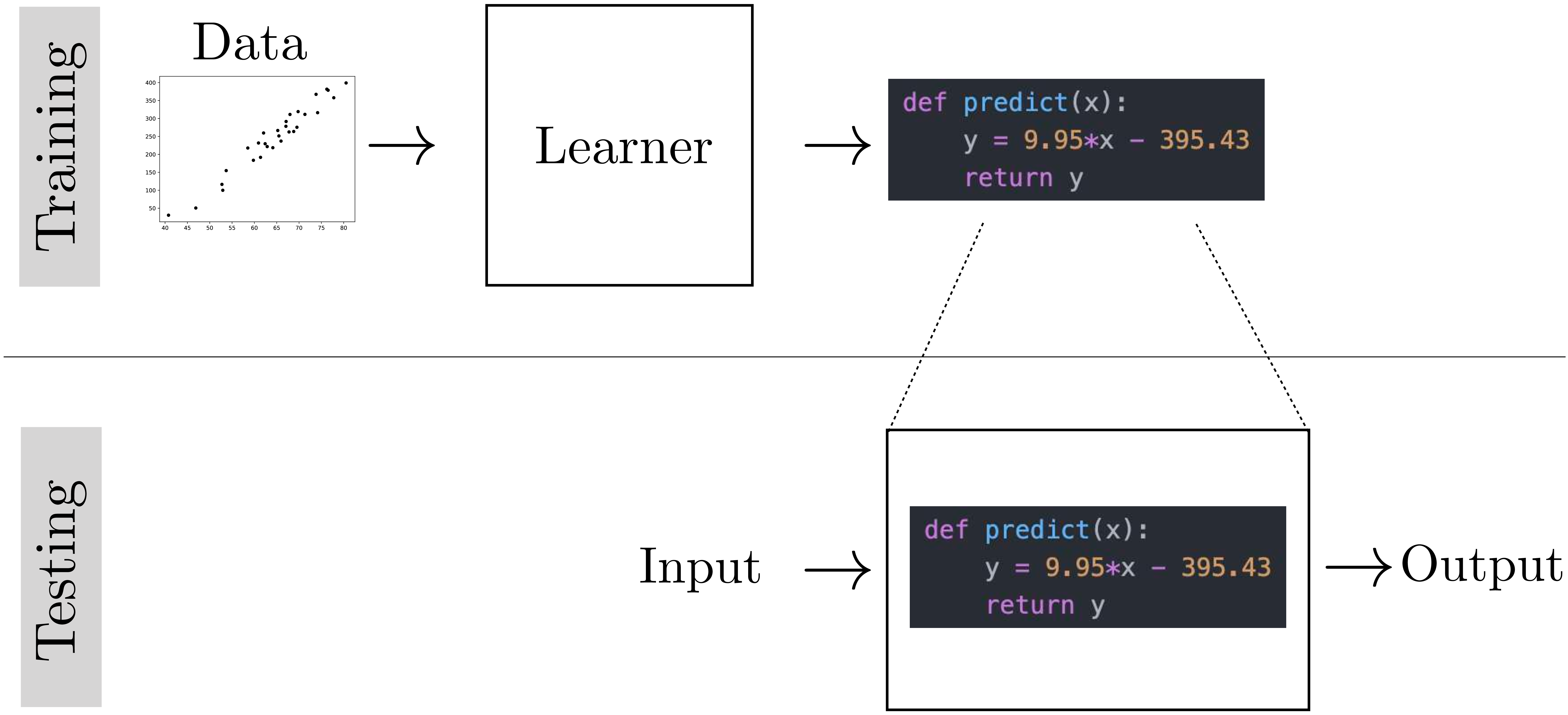
At the other end of the spectrum we have what is known as program induction, which is one of the broadest classes of learning algorithm. In this setting, our hypothesis space may be all Python programs. Let’s contrast linear least-squares with Python program induction. Figure 9.7 shows what linear least-squares looks like.
The learned function is an algebraic expression that maps \(x\) to \(y\). Learning consisting of searching over two scalar parameters, \(\theta_0\) and \(\theta_1\).
Figure 9.8 shows Python program induction solving the same problem. In this case, the learned function is a Python program that maps \(x\) to \(y\). Learning consisted of searching over the space of all possible Python programs (within some max length). Clearly that’s a much harder search problem than just finding two scalars. In chapter Chapter 11, we will see some pitfalls of using too powerful a hypothesis space when a simpler one will do.
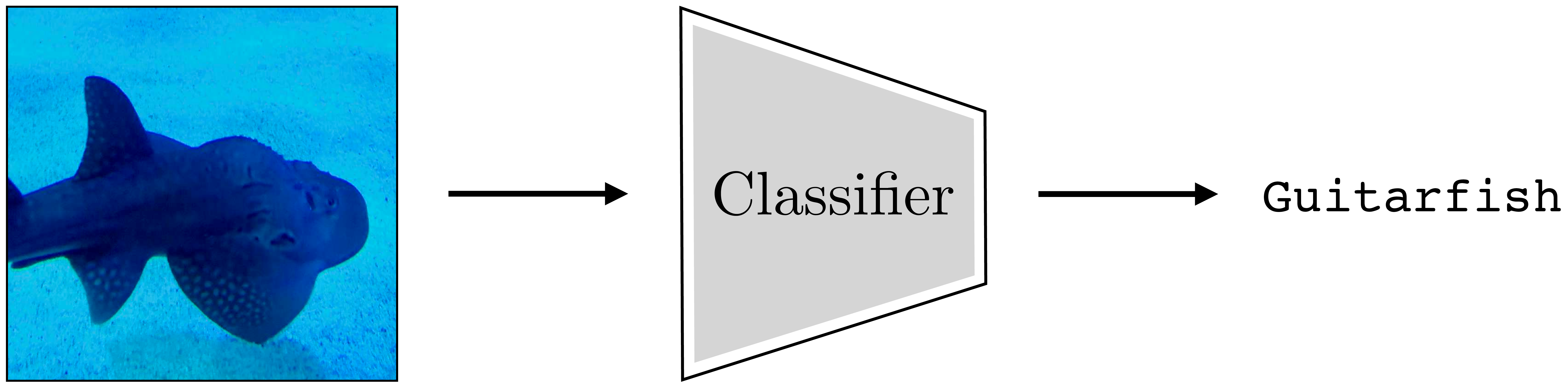
9.7.3 Example 3: Classification and Softmax Regression
A common problem in computer vision is to recognize objects. This is a problem. Our input is an image \(\mathbf{x}\), and our target output is a class label \(\mathbf{y}\) (Figure 9.9).
How should we formulate this task as a learning problem? The first question is how do we even represent the input and output? Representing images is pretty straightforward; as we have seen elsewhere in this book, they can be represented as arrays of numbers representing red-green-blue colors: \(\mathbf{x} \in \mathbb{R}^{H \times W \times 3}\), where \(H\) is image height and \(W\) is image width.
How can we represent class labels? It turns out a convenient representation is to let \(\mathbf{y}\) be a \(K\)-dimensional vector, for \(K\) possible classes, with \(y_k = 1\) if \(\mathbf{y}\) represents class \(k\), and \(y_k = 0\) otherwise. This representation is called a one-hot code, since just one element of the vector is on (“hot”). Each class has a unique one-hot code. We will see why this representation makes sense shortly. The one-hot codes are the targets for the function we are learning. Our goal is to learn a function \(f_{\theta}\) that output vectors \(\hat{\mathbf{y}}\) that match the one-hot codes, thereby correctly classifying the input images.
An example of one-hot codes for representing \(K\)=5 different classes:
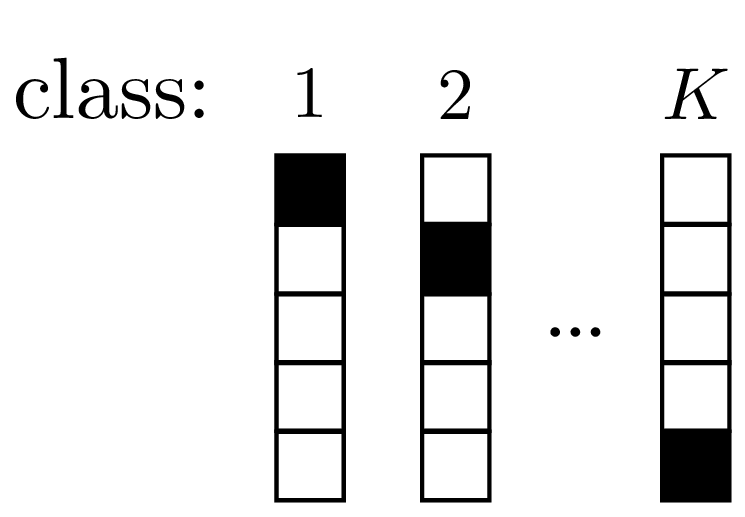
Next, we need to pick a loss function. Our first idea might be that we should minimize misclassifications. That would correspond to the so called 0-1 loss:
\[ \begin{aligned} \mathcal{L}(\hat{\mathbf{y}},\mathbf{y}) = \mathbb{1}(\hat{\mathbf{y}}\neq\mathbf{y}), \end{aligned} \] where \(\mathbb{1}\) is the indicator function that evaluates to 1 if and only if its argument is true, and 0 otherwise. Unfortunately, minimizing this loss is a discrete optimization problem, and it is NP-hard. Instead, people commonly use the , which is continuous and differentiable (making it easier to optimize): \[\begin{aligned} \mathcal{L}(\hat{\mathbf{y}},\mathbf{y}) = H(\mathbf{y}, \hat{\mathbf{y}}) = - \sum_{k=1}^K y_k \log \hat{y}_k \quad\quad \triangleleft \quad \text{cross-entropy loss} \end{aligned}\]
The way to think about this is \(\hat{y}_k\) should represent the probability we think the image is an image of class \(k\). Under that interpretation, minimizing cross-entropy maximizes the log likelihood of the ground truth observation \(\mathbf{y}\) under our model’s prediction \(\hat{\mathbf{y}}\).
For that interpretation to be valid, we require that \(\hat{\mathbf{y}}\) represent a (pmf). A pmf \(\mathbf{p}\), over \(K\) classes, is defined as a \(K\)-dimensional vector with elements in the range \([0,1]\) that sums to 1. In other words, \(\mathbf{p}\) is a point on the \((K-1)\)-simplex, which we denote as \(\mathbf{p} \in \vartriangle^{K-1}\).
The \((K-1)\)-simplex, \(\vartriangle^{K-1}\), is the set of all \(K\)-dimensional vectors whose elements sum to 1. \(K\)-dimensional one-hot codes live on the vertices of \(\vartriangle^{K-1}\).
To ensure that the output of our learned function \(f_{\theta}\) has this property, i.e., \(f_{\theta} \in \vartriangle^{K-1}\), we can compose two steps: (1) first apply a function \(z_{\theta}: \mathcal{X} \rightarrow \mathbb{R}^K\), (2) then squash the output into the range \([0,1]\) and normalize it to sum to 1. A popular way to squash is via the function:
A popular way to squash is via the softmax function:
Using softmax is a modeling choice; we could have used any function that squashes into a valid pmf, that is, a nonnegative vector that sums to 1.
\[\begin{aligned} &\mathbf{z} = z_{\theta}(\mathbf{x})\\ &\hat{\mathbf{y}} = \texttt{softmax}(\mathbf{z})\\ &\quad \quad \hat{y}_j = \frac{e^{-z_j}}{\sum_{i=1}^K e^{-z_k}}. \end{aligned}\]
The values in \(\mathbf{z}\) are called the logits and can be interpreted as the unnormalized log probabilities of each class.
Now we have,
\[\begin{aligned} \hat{\mathbf{y}} = f_{\theta}(\mathbf{x}) = \texttt{softmax}(z_{\theta}(\mathbf{x})) \end{aligned}\]
Figure 9.10 shows what the variables look like for processing one photo of a fish during training.
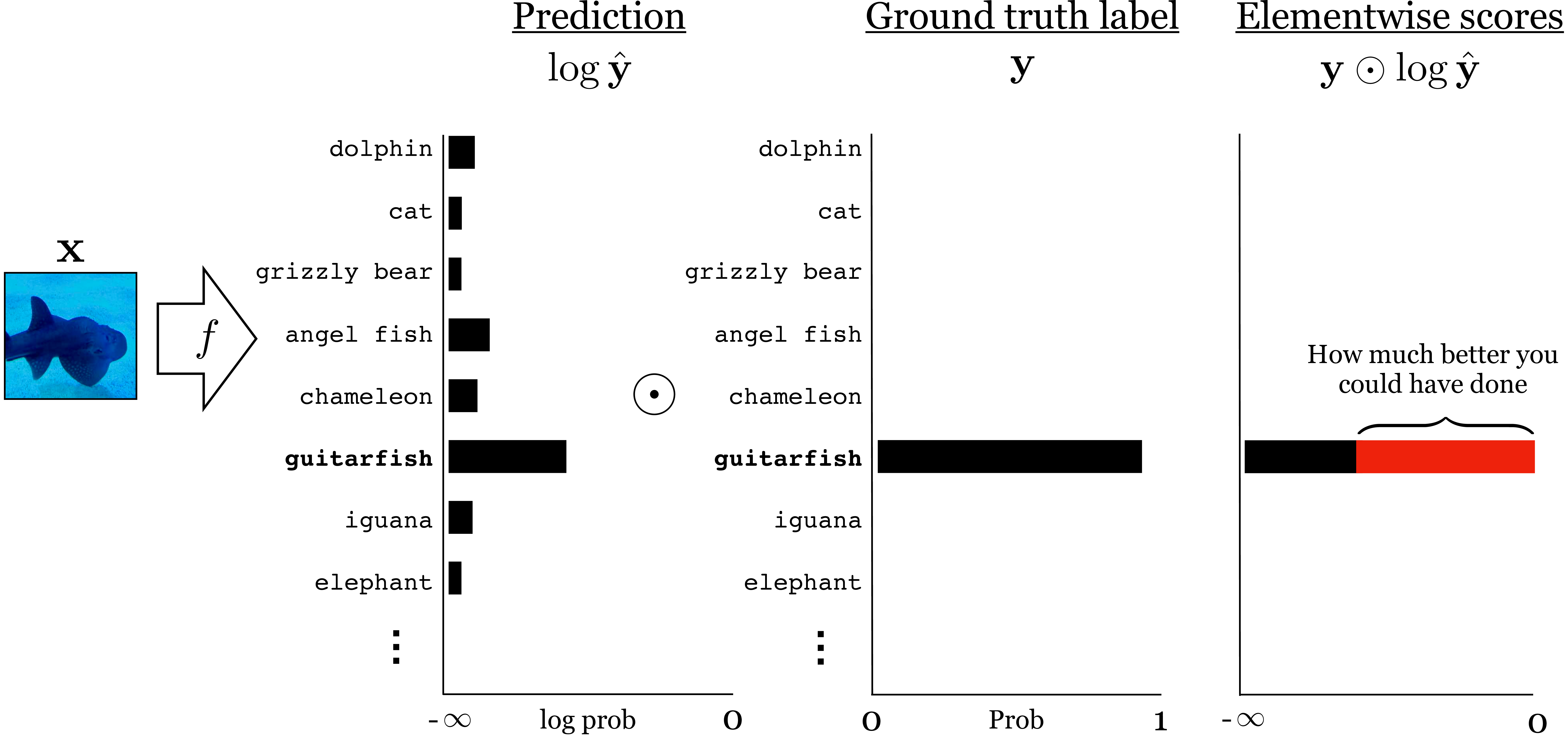
The prediction placed about 40 percent probability on the true class, “guitarfish,” so we are 60 percent off from an ideal prediction (indicated by the red bar; an ideal prediction would place 100 percent probability on the true class). Our loss is \(-\log 0.4\).
This learning problem, which is also called , can be summarized as follows:
Softmax regression is just one way to model a classification problem. We could have made other choices for how to map input data to class labels.
Notice that we have left the hypothesis space only partially specified, and we left the optimizer unspecified. This is because softmax regression refers to the whole family of learning methods that have this general form. This is one of the reasons we conceptualized the learning problem in terms of the three key ingredients described previously: you can often develop them each in isolation, then mix and match.
9.8 Learning to Learn
Learning to learn, also called metalearning, is a special case of learning where the hypothesis space is learning algorithms.
Recall that learners train on past instances of a problem to produce an algorithm that can solve future instances of the problem. The goal of metalearning is to handle the case where the future problem we will encounter is itself a learning problem, such as “find the least-squares line fit to these data points.” One way to train for this would be by example.
Suppose that we are given the following {input, output} examples:
\[\begin{aligned} &\{\texttt{input:} \big(x:[1,2], y:[1,2]\big), &&\texttt{output:} y = x\}\nonumber \\ &\{\texttt{input:} \big(x:[1,2], y:[2,4]\big), &&\texttt{output:} y = 2x\}\nonumber \\ &\{\texttt{input:} \big(x:[1,2], y:[0.5,1]\big), &&\texttt{output:} y = \frac{x}{2}\}\nonumber \end{aligned}\]
These are examples of performing least-squares regression; therefore the learner can fit these examples by learning to perform least-squares regression.
Note that least-squares regression is not the unique solution that fits these examples, and the metalearner might arrive at a different solution that fits equally well.
Since least-squares regression is itself a learning algorithm, we can say that the learner learned to learn.
We started this chapter by saying the learning is a meta-algorithm: it’s an algorithm that outputs an algorithm. Metalearning is a meta-meta-algorithm and we can visualize it by just adding another outer loop on top of a learner, as shown in Figure 9.12.
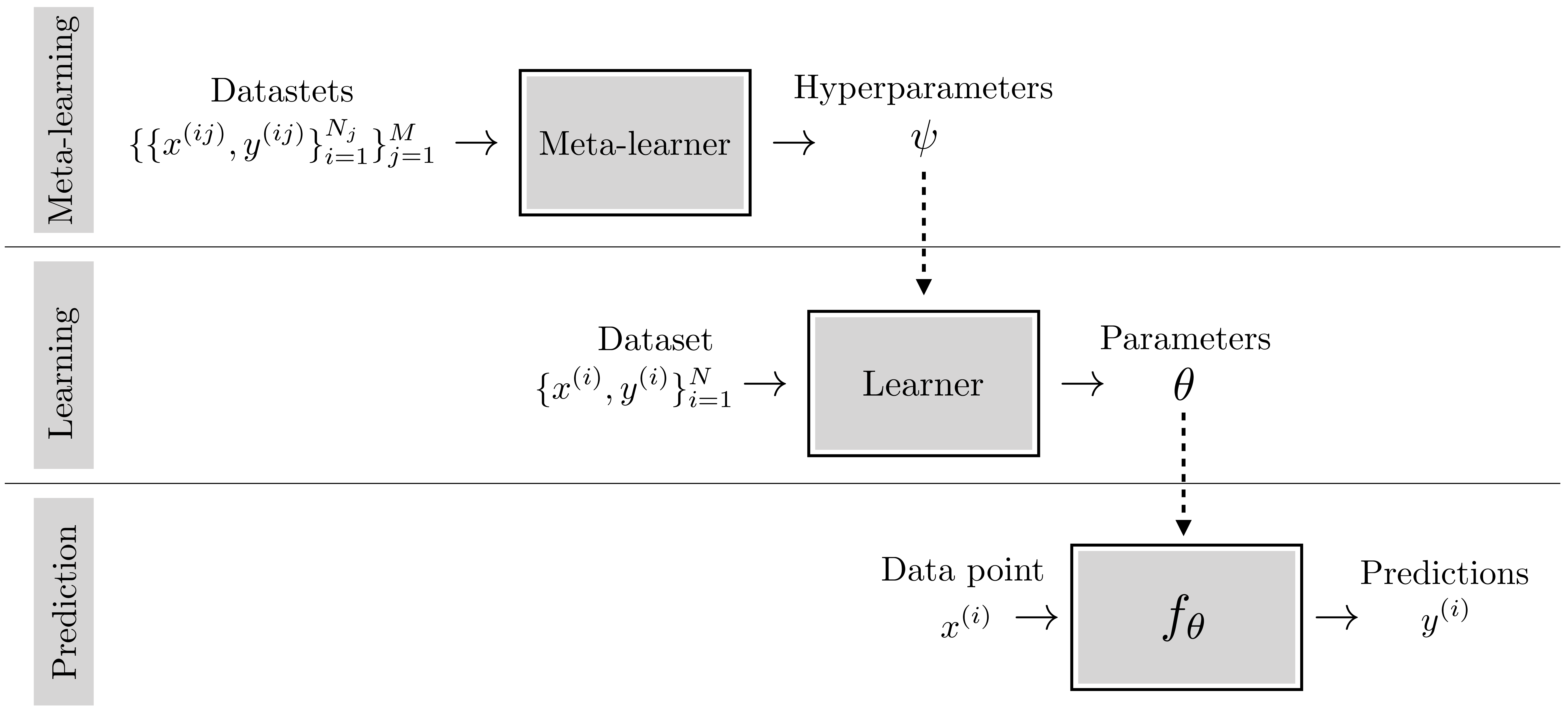
Notice that you can apply this idea recursively, constructing meta-meta-...-metalearners. Humans perform at least three levels of this process, if not more: we have evolved to be taught in school how to learn quickly on our own.
Evolution is a learning algorithm according to our present definition.
9.9 Concluding Remarks
Learning is an extremely general and powerful approach to problem solving. It turns data into algorithms. In this era of big data, learning is very often the preferred approach. It is a a major component of almost all modern computer vision systems.