55 A Simple Vision System—Revisited
55.1 Introduction
The goal of this last chapter is to embrace the optimism of the 2020s, when we think that large-scale pretrained models can do it all, and use a pretrained end-to-end vision system in order to solve the simple visual world that we introduced in Chapter 2.
In 2020, a number of big pretrained models (DALL-E [1], GPT, chatGPT [2], AutoPilot) that were solving a wide set of tasks (natural language processing, image generation, object classification, depth perception, programming, etc.) emerged. These models are trained with datasets that cover a wide set of diverse of domains that improve their generalizations and require massive amounts of computation. They can be used as is, with little to no fine tuning, or as components of more complex systems. Researchers have shown many creative ways of connecting these building blocks to produce astonishing results. However, a close analysis shows that there is still an important gap to bridge in order to build reliable and robust systems. Is the field of computer vision in the 2020s naively optimistic like in the 1960s? It does not seem to be the case, but only time will tell.
In this chapter we will revisit the simple-world problem we analyzed in Chapter 2 with a hand-crafted approach by looking for an appropriate high-performing pretrained model and applying it out-of-the-box to solve our task.
55.2 A Simple Neural Network
When we introduced the simple world in chapter Chapter 2, our goal was to recover the three-dimensional (3D) structure of the scene from a single image (Figure 55.1).

We derived an algorithm to recover the 3D scene structure from the first principles: we started studying the image formation process, we then reasoned where the information might be preserved, how to build a representation that makes the information explicit, and finally how to integrate all the evidence left in the image in order to recover the 3D information that was lost during the image formation process.
In this chapter, we will instead download a pretrained model that has been trained to solve the 3D perception problem from single images. The current state of the art is MiDaS [3], [4]. The system is a neural network trained end-to-end using a diverse set of real images that had ground truth depth information and also using stereo images.
Maybe the neural net is not so simple, but at the end, from a user’s perspective, it is just a function call. Before running the system out of the box, it is worth understanding how it was trained, what the output means, and how it can be adapted to our task.
55.2.1 How Was It Trained?
This model has been trained using a mix of four datasets with real images. The images below (Figure 55.2) show one sample from each dataset alongside their ground-truth depth.

As the model is trained with a diverse collections of data sources, there is an ambiguity on the overall scale, camera parameters, and stereo baselines. Therefore, the loss is defined in a way that it can be invariant to all those ambiguities. The invariant loss makes the training more robust, but it also makes the output less convenient to use.
To deal with the ambiguities mentioned before, the model is trained to predict disparity (inverse depth up to scale and shift). This means that we can not directly use the output. We need to convert it first into world coordinates.
55.2.2 Adapting the Output
MiDaS returns disparity values, up to an unknown constant (\(d_0\)), but what we need are world coordinates (\(X,Y,Z\)) for each pixel. To perform this transformation, we will use what we learned in chapter Chapter 39. We will need to know the intrinsic and extrinsic camera parameters and also decide the value of \(d_0\).
To translate the returned disparity for a given pixel \(d\left[n,m \right]\) into depth values \(z\left[n,m \right]\), we need to invert the disparity after adding the constant:
\[\begin{aligned}z \left[n,m \right] = \frac{1}{ d \left[n,m \right] + d_0} \end{aligned}\] Now we need to recover the world coordinates for every pixel. Assuming a pinhole camera and using the depth \(z \left[n,m \right]\) and the camera matrix \(\mathbf{K}\), we obtain the 3D coordinates for a pixel with image coordinates \((n,m)\) in the camera reference frame as,
\[\begin{aligned} \begin{bmatrix} X \\ Y \\ Z \end{bmatrix} = z\left[n,m \right] \times \mathbf{K}^{-1} \times \begin{bmatrix} n \\ m \\ 1 \end{bmatrix} \end{aligned} \tag{55.1}\]
The camera parameters will have to account for the focal length, image size, camera center, and the camera rotation with respect to the world coordinates: \[\mathbf{K} = \mathbf{M} \mathbf{R} \]
The intrinsic camera parameters (using perspective projection) are: \[ \begin{aligned} \mathbf{M} = \begin{bmatrix} a & 0 & n_0\\ 0 & a & m_0 \\ 0 & 0 & 1 \end{bmatrix}. \end{aligned} \]
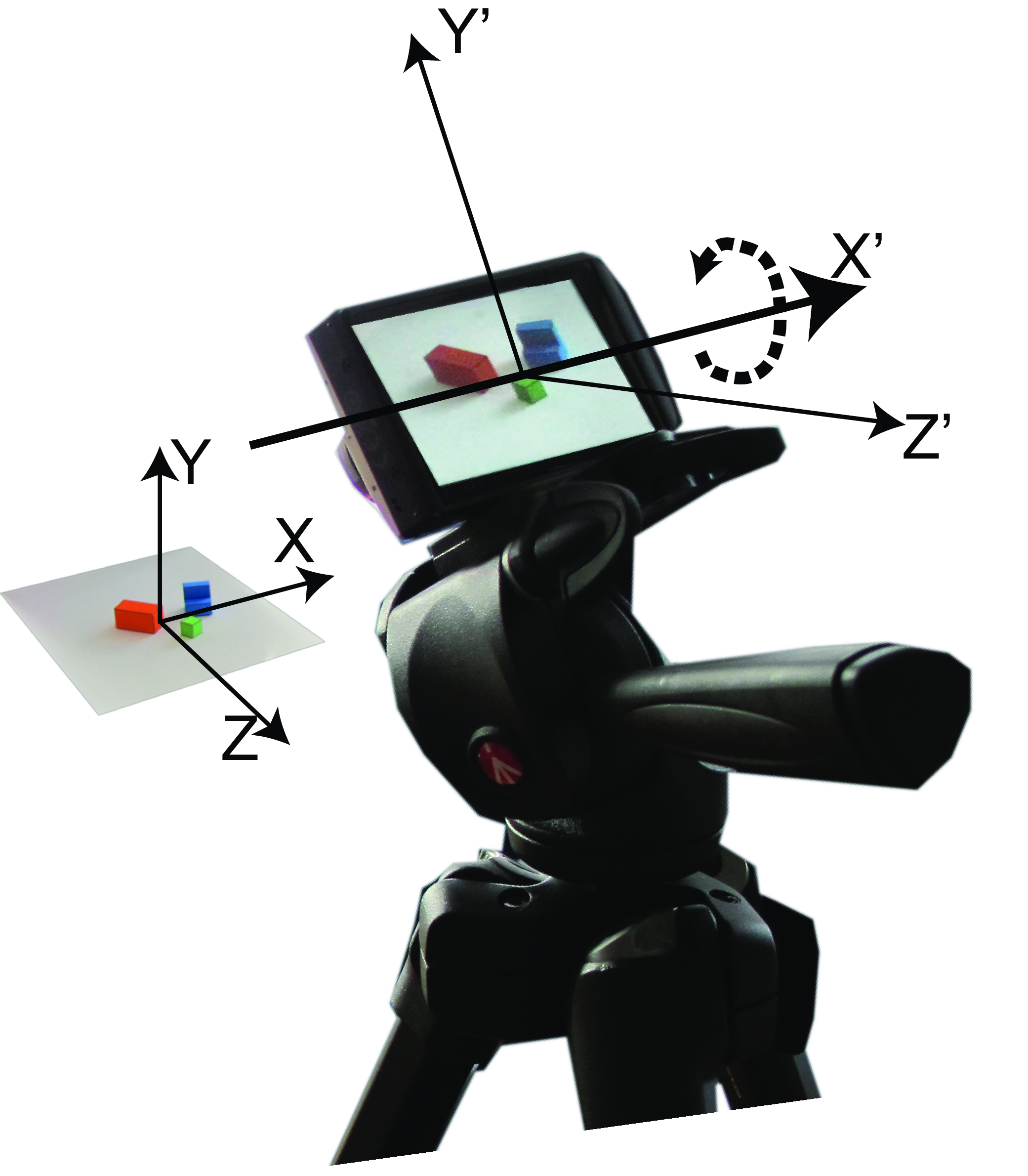
The extrinsic camera parameters will model the 3D rotation, which is mainly around the \(X\)-axis (we will ignore the translation of the origin): \[ \begin{aligned} \mathbf{R} = \begin{bmatrix} 1 & 0 & 0\\ 0 & \cos(\theta) & -\sin(\theta) \\ 0 & \sin(\theta) & \cos(\theta) \end{bmatrix}. \end{aligned} \]
In order to apply Equation 55.1, we need to define certain parameters: \(d_0\), \(n_0\), \(m_0\), \(a\), and \(\theta\). Although we could determine these parameters using a calibration image, in this case, we’ll opt for a simpler heuristic approach:
\(d_0\): We will set this value to 0.
\(n_0,m_0\): Defines the camera center point, where \(n_0=N/2\) and \(m_0=M/2\), when \(N \times M\) is the input image size.
\(a\): Accounts for the image size and the camera focal length. One standard setting is to make \(a = N\), where \(N\) is the image width.
\(\theta\): Represents the angle between the optical camera axis and the ground plane. It would be possible to estimate this angle accurately by determining the direction of the surface normal in pixels corresponding to the ground and measuring the angle with respect to the vertical axis. However, for our purposes, we will simply set it to \(\theta = \pi / 4\), as this is approximately the angle at which the pictures were taken.
Now we are ready to use Equation 55.1 and the output of the system.
55.3 From 2D Images to 3D
Let’s start running the model on the same input image that we used as a running example in Chapter 2. We just need to apply the neural network to the input image, obtain the output disparity, and finally transform the disparity into world coordinates. We do not have to detect edges or any of the other features that we computed in Chapter 2. Instead, the neural network has learned to compute whatever features it deems necessary to solve the task. We will not retrain the network using images from our simple visual world.
Just as we did in Chapter 2, to show that the algorithm for 3D interpretation gives reasonable results, we can re-render the inferred 3D structure from different viewpoints.

It is quite remarkable that it works somewhat well even though this system has been trained with natural images, which are quite dissimilar to the simple world we are using here. However, despite the surprising outputs, it is clear we cannot avoid a number of errors. For instance, the ground is not recovered as a flat surface; instead it seems to be concave. The cubes’ edges are not straight and the faces are twisted instead of flat.
We can compare this result with the 3D images recovered using the algorithm we defined in Chapter 2:

However, while the learned-based model may have lost accuracy in this example that fits our simple world assumptions, it has gained in robustness and generalization. The following figure compares the results obtained running MiDaS (the learning-based approach) or the simple world model (a hand-crafted approach).
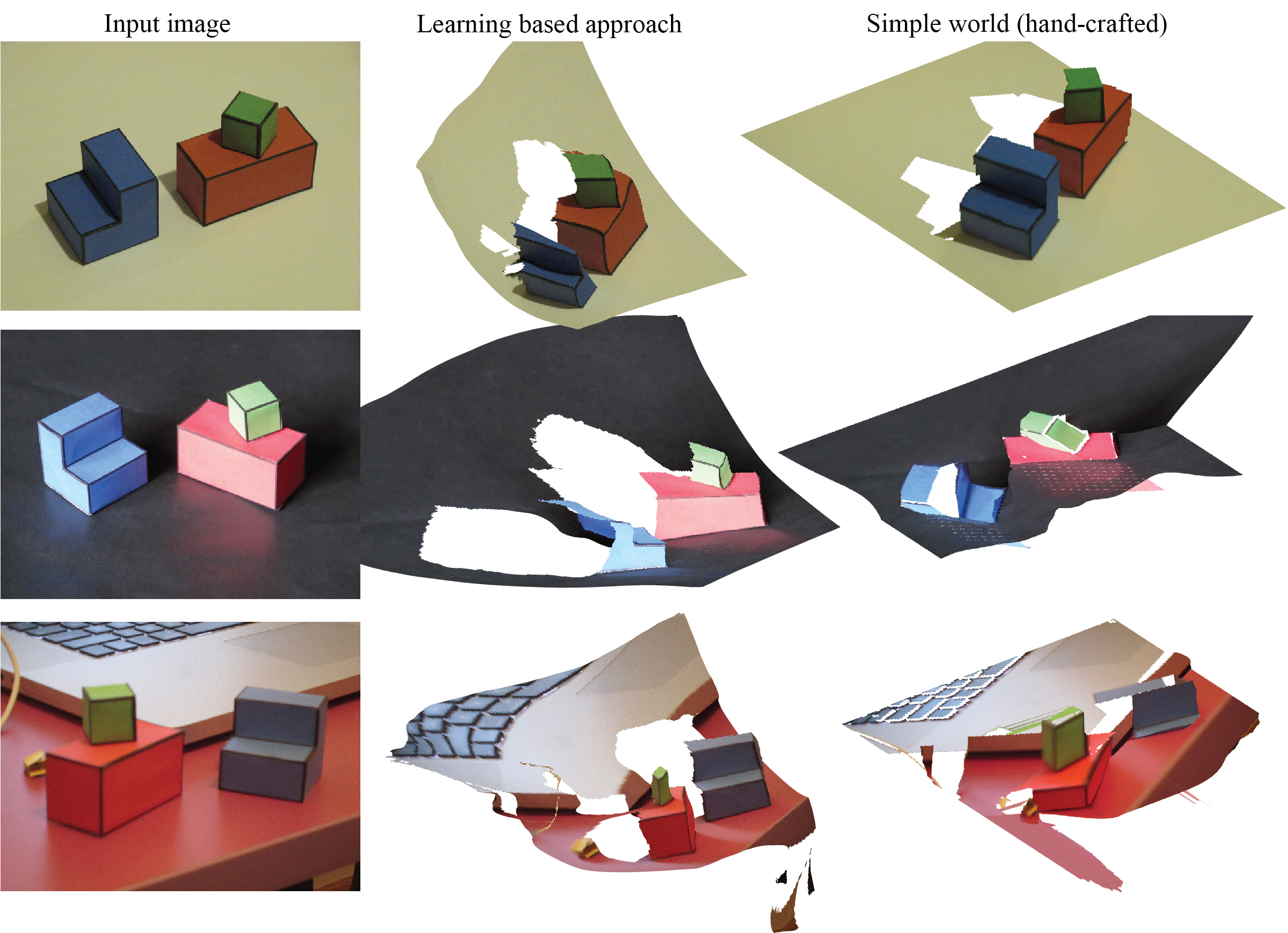
When the images fit the assumptions of the world model, the hand-crafted approach can produce beautiful results. However, it is very fragile, and poor illumination can break the output of the edge detectors, which results in a cascade of errors that propagate to the output. Conversely, the learning-based approach seems to produce results of good (although never perfect) quality regardless of the conditions. The hand-crafted approach completely fails even if we make a small change in the scene such as changing the ground plane from white to black.
55.4 Large Language Model-based Scene Understanding
Another option is to use GPT4-v [5] to interpret the scene. GPT4-v can take as inputs images, and it allows asking questions about images. Figure 55.6 shows the result of asking GPT4-v to describe a simple world image.
This method is remarkably accurate, and now you know how it works. At one level Gpt4-v is a transformer trained on massive data, using an autoregressive modeling objective (Chapter 26). On another level, you can understand what rules that transformer may have learned: it detects edges in its first few layers, uses filters that act like wavelets tiling Fourier space, and it reasons about perspective geometry to find vanishing points and estimate shape (as we have discussed along many chapters in this book).
But it’s not all solved. Because if we reconstruct the image from this text, it looks not quite right: Figure 55.7. What is missing? How would you improve it. As the field moves forward quickly, it is likely that this particular example will be fixed, but there will be other failures. And some of those failures will give clues to what is the next fundamental question that will need to be addressed.

55.5 Unsolved Solved Computer Vision Problems
Computer vision is making amazing progress, but beware of the unsolved solved computer vision problems. For some vision task, it might appear as if there is one method that perfectly resolves the task. It might appear as if some foundational problems in computer vision are solved. It might often seem as if it is not possible to make progress regarding certain questions. But more often than not, it is just an illusion, and the solved problem was not really solved at all. And even when a problem was genuinely solved (and probably is not), it’s important to remember that for every solved problem, there are many unsolved problems lurking in the background.
When everything seems to be solved, remember that advances are the result of exploring new directions, with an open mind, and that creativity is a powerful tool.
55.6 Concluding Remarks
What have we learned in this chapter? We learned that using a large pretrained model kind of works; it is not as clean as the results we had in Chapter 2, but it works in situations where our simple heuristic method was breaking. And we can expect performances of future pretrained models to keep improving.
With the hand-crafted model presented in Chapter 2, we had a comprehensive understanding of the mechanisms, assumptions, and limitations of our system. Another interesting advantage of the hand-crafted model is that it required no learning and no training data. Once the model was written down it was ready to work. It worked really well when the conditions were met, but it was fragile and unreliable as soon as we deviated from those conditions. Our hand-crafted model did not generalize outside the space defined by our assumptions. When the system failed, it was easy to point out exactly what went wrong with it, but knowing what was wrong was not helping in making it work better.
Conversely, the pretrained system for 3D reconstruction seems to have generalized to our setting, at least to some degree, and it is able to deal with configurations that were not part of our modeling assumptions. The pretrained model is robust to changes on illumination and does not rely on fragile operations such as edge detection or figure-ground segmentation. But somehow, equivalent operations might be taking place inside the network. Information about 3D is still mostly contained in the edges, and information has to be propagated from the edges and junctions to the flat surfaces. How does the pretrained model work exactly? Has it learned some of the heuristics we introduced by hand, or is it using other ones?

GPT4-v seems to be capable of recognizing the geometric figures and their spatial configuration but the integration with the rendering engine seems fragile and was not able to create a new image with the same elements (although it is very close!). But why did it fail?
The precise answers to these questions do not matter right now. The field is evolving quickly and many of those problems will be addressed over time. What matters is that you should challenge existing approaches, and find what the relevant questions are for whatever new systems you encounter.
With learning-based systems we find ourselves doing experiments similar to the ones performed by psychophysics in trying to understand the mechanisms implemented by the human visual system.
