Foundations of Computer Vision
You can buy the print version of this book here.
Published by The MIT Press
Cambridge, Massachusetts
London, England
Preface
Dedicated to all the pixels.
About this Book
This book covers foundational topics within computer vision, with an image processing and machine learning perspective. We want to build the reader’s intuition and so we include many visualizations. The audience is undergraduate and graduate students who are entering the field, but we hope experienced practitioners will find the book valuable as well.
Our initial goal was to write a large book that provided a good coverage of the field. Unfortunately, the field of computer vision is just too large for that. So, we decided to write a small book instead, limiting each chapter to no more than five pages. Such a goal forced us to really focus on the important concepts necessary to understand each topic. Writing a short book was perfect because we did not have time to write a long book and you did not have time to read it. Unfortunately, we have failed at that goal, too.
Writing this Book
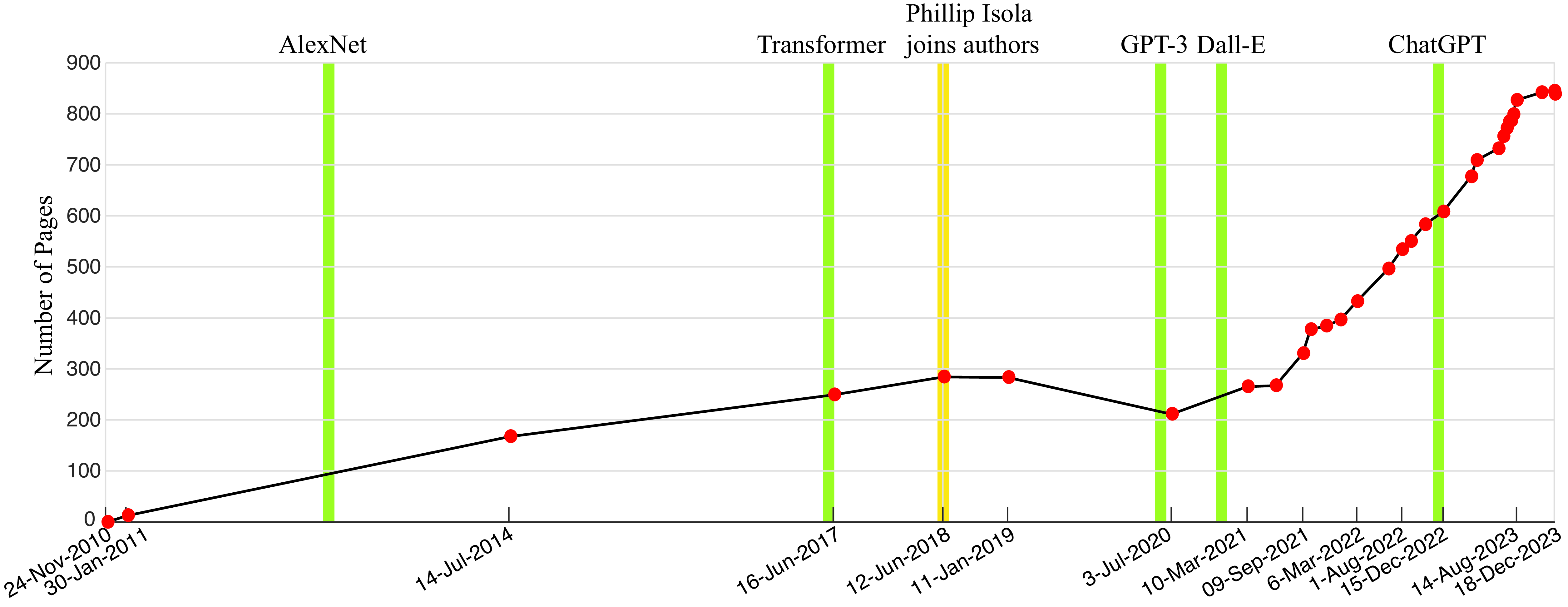
To appreciate the path we took to write this book, let’s look at some data first. shows the number of pages written as a function of time since we mentioned the idea to MIT press for the first time on November 24, 2010.
Starting to write this book was like entering this cave.  We had no idea what we were getting into.
We had no idea what we were getting into.
Writing this book has not been a linear process. As the plot shows, the evolution of the manuscript length is non-monotonic, with a period when the book shrank before growing again. Lots of things have happened since we started thinking about this book in November 2010; yes, it has taken us more than 10 years to write this book. If we knew on the first day all the work that is involved in writing a book like this one there is no way we would have started. However, from today’s vantage point, with most of the work behind us, we feel happy we started this journey. We learned a lot by writing and working out the many examples we show in this book, and we hope you will too by reading and reproducing the examples yourself.
When we started writing the book, the field was moving ahead steadily, but unaware of the revolution that was about to unfold in less than 2 years. Fortunately, the deep learning revolution in 2012 made the foundations of the field more solid, providing tools to build working implementations of many of the original ideas that were introduced in the field since it began. During the first years after 2012, some of the early ideas were forgotten due to the popularity of the new approaches, but over time many of them returned. We find it interesting to look at the process of writing this book with the perspective of the changes that were happening in the field. Figure 1 shows some important events in the field of artificial intelligence (AI) that took place while writing this book.
Structure of the Book
Computer vision has undergone a revolution over the last decade. It may seem like the methods we use now bear little relationship to the methods of 10 years ago. But that’s not the case. The names have changed, yes, and some ideas are genuinely new, but the methods of today in fact have deep roots in the history of computer vision and AI. Throughout this book we will emphasize the unifying themes behind the concepts we present. Some chapters revisit concepts presented earlier from different perspectives.
One of the central metaphors of vision is that of multiple views. There is a true physical scene out there and we view it from different angles, with different sensors, and at different times. Through the collection of views we come to understand the underlying reality. This book also presents a collection of views, and our goal will be to identify the underlying foundations.
The book is organized in multiple parts, of a few chapters each, devoted to a coherent topic within computer vision. It is preferable to read them in that order as most of the chapters assume familiarity with the topics covered before them. The parts are as follows:
Part I discusses some motivational topics to introduce the problem of vision and to place it in its societal context. We will introduce a simple vision system that will let us present concepts that will be useful throughout the book, and to refresh some of the basic mathematical tools.
Part II covers the image formation process.
Part III covers the foundations of learning using vision examples to introduce concepts of broad applicability.
Part IV provides an introduction to signal and image processing, which is foundational to computer vision.
Part V describes a collection of useful linear filters (Gaussian kernels, binomial filters, image derivatives, Laplacian filter, and temporal filters) and some of their applications.
Part VI describes multiscale image representations.
Part VII describes neural networks for vision, including convolutional neural networks, recurrent neural networks, and transformers. Those chapters will focus on the main principles without going into describing specific architectures.
Part VIII introduces statistical models of images and graphical models.
Part IX focuses on two powerful modeling approaches in the age of neural nets: generative modeling and representation learning. Generative image models are statistical image models that create synthetic images that follow the rules of natural image formation and proper geometry. Representation learning seeks to find useful abstract representations of images, such as vector embeddings.
Part X is composed of brief chapters that discuss some of the challenges that arise from building learning-based vision systems.
Part XI introduces geometry tools and their use in computer vision to reconstruct the 3D world structure from 2D images.
Part XII focuses on processing sequences and how to measure motion.
Part XIII deals with scene understanding and object detection.
Part XIV is a collection of chapters with advice for junior researchers on effective methods of giving presentations, writing papers, and the mentality of an effective researcher.
Part XV returns to the simple visual system and applies some of the techniques presented in the book to solve the toy problem introduced in Part I.
What Do We Not Cover?
This should be a long section, but we will keep it short. We do not provide a review on the current state of the art of computer vision; we focus instead on the foundational concepts. We do not cover in depth the many applications of computer vision such as shape analysis, object tracking, person pose analysis, or face recognition. Many of those topics are better studied by reading the latest publications from computer vision conferences and specialized monographs.
Acknowledgments
We thank our teachers, students, and colleagues all over the world who have taught us so much and have brought us so much joy in conversations about research. This book also builds on many computer vision courses taught around the world that helped us decide which topics should be included. We thank everyone that made their slides and syllabus available. A lot of the material in this book has been created while preparing the MIT course, “Advances in Computer Vision.”
We thank our colleagues who gave us comments on the book: Ted Adelson, David Brainard, Fredo Durand, David Fouhey, Agata Lapedriza, Pietro Perona, Olga Russakovsky, Rick Szeliski, Greg Wornell, Jose María Llauradó, and Alyosha Efros. A special thanks goes to David Fouhey and Rick Szeliski for all the help and advice they provided. We also thank Rob Fergus and Yusuf Aytar for early contributions to this manuscript. Many colleagues and students have helped proof reading the book and with some of the experiments. Special thanks to Manel Baradad, Sarah Schwettmann, Krishna Murthy Jatavallabhula, Wei-Chiu Ma, Kabir Swain, Adrian Rodriguez Muñoz, Tongzhou Wang, Jacob Huh, Yen-Chen Lin, Pratyusha Sharma, Joanna Materzynska, and Shuang Li. Thanks to Manel Baradad for his help on the experiments in Chapter 55 A Simple Vision System—Revisited, to Krishna Murthy Jatavallabhula for helping with the code for Chapter 44 Multiview Geometry and Structure from Motion, and Aina Torralba for help designing the book cover and several figures.
Antonio Torralba thanks Juan, Idoia, Ade, Sergio, Aina, Alberto, and Agata for all their support over many years.
Phillip Isola thanks Pam, John, Justine, Anna, DeDe, and Daryl for being a wonderful source of support along this journey.
William Freeman thanks Franny, Roz, Taylor, Maddie, Michael, and Joseph for their love and support.
How to Cite This Book
If you would like to cite this book, please use the following BibTeX entry:
@book{foundationsCVbook,
title={Foundations of Computer Vision},
author={Torralba, A. and Isola, P. and Freeman, W.T.},
isbn={9780262378666},
lccn={2023024589},
series={Adaptive Computation and Machine Learning series},
url={https://mitpress.mit.edu/9780262048972/foundations-of-computer-vision/},
year={2024},
publisher={MIT Press}
}Resources for Instructors
The print version of this book is available for purchase at the MIT Press.
Slides that accompany this book are available for download here.